 克里夫的角落:克里夫硅藻土在数学和计算
克里夫的角落:克里夫硅藻土在数学和计算 MATLAB的博客
MATLAB的博客 史蒂夫与MATLAB图像处理
史蒂夫与MATLAB图像处理 人在仿真软件万博1manbetx
人在仿真软件万博1manbetx 深度学习
深度学习 开发区域
开发区域 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 文件交换的选择
文件交换的选择 汉斯在物联网
汉斯在物联网 学生休息室
学生休息室 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー 创业、加速器,和企业家
创业、加速器,和企业家线性代数在MATLAB:尝试AMD的AOCL
在R2022a, MathWorks开始航运AMD与英特尔MKL AOCL MATLAB。本文将解释这些是什么,为什么你可能会关心他们。
bla和LAPACK
很多现代技术的计算成为可能布拉斯特区和LAPACK库。你可能没有听说过,但我几乎可以肯定你用它们。你曾经乘两个密集使用MATLAB矩阵在一起吗?如果是这样,你是一个布拉斯特区用户。计算特征值或稠密矩阵的奇异值分解吗?是吗?你是一个LAPACK用户。MATLAB的用户,但你所做的这些操作在Python或R ?你也很可能这些库的用户。
bla和LAPACK许多依赖于计算的核心,因此,你可以想象,他们严肃对待公司发展矩阵实验室!当MATLAB第一次开始使用LAPACK早在2000年,例如,克里夫硅藻土写了许多细节和随后的速度提升。
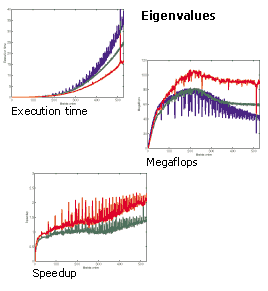
2000年从克里夫的文章显示特征值计算的速度。红线显示加速LAPACK前相比,MATLAB
许多人在MathWorks找到有趣的东西上面的结果是,性能测量在Megaflops(10 ^ 6每秒浮点运算),数千倍慢于吉拍(10 ^ 9失败)我们预计从今天即使是最温和的笔记本电脑。今年早些时候,我们进入了一个新的计算时的时代前沿的超级计算机证明它可以运行在1 Exaflop(10 ^ 18失败)。
两个库,许多实现
bla和LAPACK了解图书馆的一件事是,有很多他们的实现。所谓的参考布拉斯特区和LAPACK定义用户界面和容易阅读,实现每个操作的实现。
不同群体产生这些库使用各种策略的优化实现。我提到的一个例子,OpenBLAS,在我发布的R2022a苹果硅MATLAB的beta版本。另一个例子是英特尔的数学内核库(MKL),顾名思义,是一个图书馆从英特尔bla和LAPACK提供高度优化的版本的硬件。
英特尔MKL bla和LAPACK一直是MATLAB提供的很长一段时间了。举例来说,在MATLAB R2022a
> >版本-lapack ans = '英特尔(R) oneAPI数学内核库2021.3版本的产品为英特尔(R) 64架构的应用程序构建20210611 (CNR分支AVX512_E1)支持线性代数包(LAPACK 3.9.0)”布拉斯特区ans = > >版本的英特尔(R) oneAPI数学内核库2021.3版本的产品为英特尔万博1manbetx(R) 64架构的应用程序构建20210611 (CNR分支AVX512_E1) '
MKL AMD处理器上的工作很好,但我们的一些用户要求官方支持AMD的加速这些库的实现。万博1manbetx被称为AMD CPU优化图书馆,简称AOCL,这些是由AMD和针对自己的硬件虽然与英特尔MKL一样,他们工作在AMD和英特尔的硬件。
从R2022a AOCL中选择可用MATLAB
R2022a,我们已经开始航运与MATLAB AOCL但不是默认激活。更改默认的版本不是MathWorks做的一切。因此,R2022a继续使用默认MKL但用户的Intel和AMD硬件(在Windows和Linux)能够切换到使用的版本AOCL通过MathWorks资格测试。
指令进行切换在这个MATLAB给出答案。
你可能会这样做的原因,当然,是速度。也许,AOCL比MKL快一些操作和我们感兴趣的是听到你在这种情况下。当然我们也很感兴趣的任何问题你遇到在这一点。
性能差异你能看到什么?
你应该只会看到性能的差异函数,利用线性代数。任何潜在的差异将取决于类型的操作等因素,矩阵规模和结构和哪些CPU使用。
它不一定是一个库的情况下总是优于其他任何硬件。例如,使用脚本laBench.mAzure D16ads_v5实例上运行,使7763的核心AMD EPYC我发现以下时间为10000 x 10000矩阵:
英特尔MKL结果(3)的- 矩阵乘以时间是5.60秒
- 柯列斯基时间是1.07秒
- 矩阵乘以时间是5.31秒
- 柯列斯基时间是1.22秒
所以矩阵与矩阵的乘法速度在这个硬件使用AOCL但柯列斯基分解慢这个矩阵的大小。
交给你了我非常兴奋的最近更新,希望你太。如果你试一试,让我知道你在评论区或通过twitter。






评论
留下你的评论,请点击在这里MathWorks账户登录或创建一个新的。