基于MFCC和LSTM网络的噪声关键词识别
本例展示了如何使用深度学习网络识别含噪语音中的关键词。特别是,本例使用双向长短时记忆(BiLSTM)网络和mel频率倒谱系数(MFCC)。
介绍
关键词识别(KWS)是语音辅助技术的一个重要组成部分,用户在向设备发出完整的命令或查询之前,先说出一个预定义的关键词来唤醒系统。
这个例子训练了一个具有梅尔频率倒谱系数(MFCC)特征序列的KWS深度网络。该示例还演示了如何使用数据增强来提高噪声环境中的网络精度。
本例使用长短时记忆(LSTM)网络,这是一种非常适合研究序列和时间序列数据的递归神经网络(RNN)。LSTM网络可以学习序列时间步长之间的长期依赖关系。LSTM层(第一层(深度学习工具箱))可以向前方向查看时间序列,而双向LSTM层(bilstmLayer(深度学习工具箱))可以从正反两个方向看时间序列。这个例子使用了一个双向LSTM层。
该示例使用谷歌语音命令数据集训练深度学习模型。要运行该示例,必须首先下载数据集。如果您不想下载数据集或训练网络,那么您可以通过在MATLAB®中打开此示例并运行示例的3-10行来下载和使用预训练的网络。
Spot关键字与预先训练的网络
在详细进入训练过程之前,您将下载并使用预先训练的关键字识别网络来识别关键字。
在本例中,spot的关键字是是的.
读取关键字发出的测试信号。
[audioIn,fs]=音频读取(“keywordTestSignal.wav”);声音(音频输入,fs)
下载并加载预先训练的网络、用于特征归一化的均值(M)和标准差(S)向量,以及示例中稍后用于验证网络的2个音频文件。
网址=“http://ssd.mathworks.com/万博1manbetxsupportfiles/audio/KeywordSpotting.zip”;downloadNetFolder = tempdir;netFolder = fullfile (downloadNetFolder,“关键词识别”);如果~exist(netFolder,“dir”)disp(“下载预先训练的网络和音频文件(4个文件- 7 MB)……”解压缩(url, downloadNetFolder)终止负载(fullfile (netFolder“KWSNet.mat”));
创建一个audioFeatureExtractor对象以执行特征提取。
WindowLength = 512;OverlapLength = 384;afe=音频特征提取程序(“SampleRate”,财政司司长,...“窗口”损害(WindowLength“周期性”),...“OverlapLength”OverlapLength,...“mfcc”,真的,...“mfccDelta”,真的,...“mfccDeltaDelta”,真正的);
从测试信号中提取特征并将其标准化。
特征=提取(afe,audioIn);特征=(特征-M)。/S;
计算关键字定位二进制掩码。掩码值为1对应于发现关键字的段。
掩码= (KWSNet、特点进行分类。');
掩码内的每个样本对应于语音信号(窗长-重叠长度).
将掩码扩展到信号的长度。
mask = repmat(mask, WindowLength-OverlapLength, 1);Mask = double(Mask) - 1;掩码=面具(:);
绘制测试信号和遮罩。
figure audioIn = audioIn(1:长度(掩码));t =(0:长度(audioIn) 1) / fs;情节(t, audioIn)网格在持有在绘图(t、遮罩)图例(“演讲”,“是的”)

听标记的关键字。
声音(音频输入(掩码==1),fs)
使用来自麦克风的流式音频检测命令
在麦克风的流式音频上测试预先训练的命令检测网络。尝试随机说出单词,包括关键字(是的).
调用generateMATLABFunction上audioFeatureExtractor对象创建特征提取函数。您将在处理循环中使用这个函数。
generateMATLABFunction (afe“generateKeywordFeatures”,“正在流”,真正的);
定义一个可以从麦克风读取音频的音频设备阅读器。配置帧长度为跳数长度。这使您能够为麦克风中的每一个新的音频帧计算一组新的特性。
HopLength = WindowLength - OverlapLength;FrameLength = HopLength;adr = audioDeviceReader (“SampleRate”,财政司司长,...“样品性能框架”,帧长);
创建语音信号和估计掩码的可视化范围。
范围= timescope (“SampleRate”,财政司司长,...“时间跨度源”,“财产”,...“时间间隔”5,...“TimeSpanOverrunAction”,“滚动”,...“BufferLength”,fs*5*2,...“ShowLegend”,真的,...“ChannelNames”,{“演讲”,“关键词面具”},...“YLimits”(-1.2 - 1.2),...“标题”,“关键词发现”);
定义估计掩码的速率。你将生成一个掩码NumHopsPerUpdate音频帧。
NumHopsPerUpdate=16;
初始化音频缓冲区。
dataBuff=dsp.AsyncBuffer(窗口长度);
初始化计算特性的缓冲区。
featureBuff = dsp.AsyncBuffer (NumHopsPerUpdate);
初始化缓冲区以管理音频和掩码的打印。
plotBuff=dsp.AsyncBuffer(NumHopsPerUpdate*WindowLength);
要无限期运行循环,请将timeLimit设置为正.要停止模拟,请关闭scope。
时限=20;抽搐虽然toc如果featureBuff。NumUnreadSamples == NumHopsPerUpdate featureMatrix = read(featureBuff);featureMatrix (~ isfinite (featureMatrix)) = 0;featureMatrix = (featureMatrix - M)./S;[keywordNet, v] = classifyAndUpdateState(KWSNet,featureMatrix.');V = double(V) - 1;v = repmat(v, HopLength, 1);v = (,);v =模式(v);v = repmat(v, NumHopsPerUpdate * HopLength,1); data = read(plotBuff); scope([data, v]);如果~ isVisible(范围)打破;终止终止终止隐藏(范围)

在本例的其余部分中,您将学习如何训练关键字识别网络。
培训过程总结
培训过程包括以下步骤:
检查验证信号上的“金标准”关键字定位基线。
从无噪数据集创建训练话语。
使用从这些话语中提取的MFCC序列训练关键词定位LSTM网络。
当应用到验证信号时,通过比较验证基线和网络输出来检查网络的准确性。
检查网络精度,确认是否有被噪声破坏的信号。
通过使用向语音数据中注入噪声来增强训练数据集
audioDataAugmenter.使用增强的数据集对网络进行再培训。
验证再训练后的网络在应用于噪声验证信号时具有更高的精度。
检查确认信号
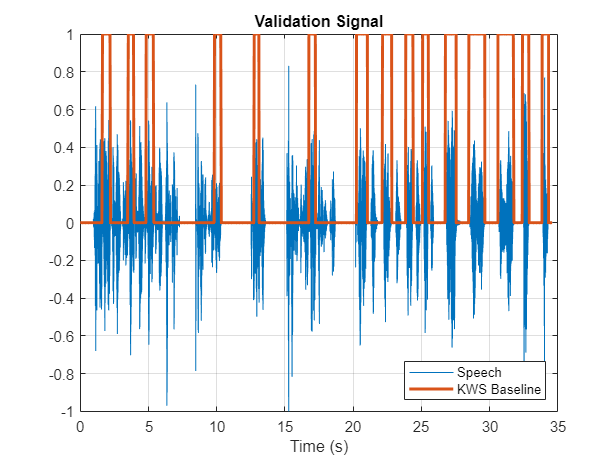
您可以使用示例语音信号来验证KWS网络。验证信号包括34秒的带有关键字的语音是的出现间歇性。
加载验证信号。
[audioIn,fs]=audioread(完整文件(netFolder,“关键字Speech-16-16-mono-34secs.flac”));
听信号。
声音(音频输入,fs)
将信号可视化。
图t = (1/fs) * (0:length(audioIn)-1);情节(t, audioIn);网格在xlabel(‘时间’)头衔(“验证语音信号”)

检查KWS基线
加载KWS基线。此基线是使用演讲稿:使用音频标签创建关键字定位掩码.
负载(“KWSBaseline.mat”,“KWSBaseline”)
基线是与验证音频信号长度相同的逻辑向量。段在音频素在发出关键字的位置设置为1KWSBaseline.
将语音信号与KWS基线一起可视化。
无花果=图;情节(t [audioIn KWSBaseline '])网格在xlabel(‘时间’)传说(“演讲”,“KWS基线”,“位置”,‘东南’)l=findall(图,“类型”,“行”);l(1)。线宽= 2;标题(“验证信号”)
听识别为关键词的语音片段。
声音(audioIn (KWSBaseline)、fs)
您训练的网络的目标是输出一个由0和1组成的KWS掩码,如此基线。
加载语音命令数据集
下载并提取Google语音命令数据集[1].
网址='https://ssd.mathworks.com/万博1manbetxsupportfiles/audio/google_speech.zip';downloadFolder=tempdir;datasetFolder=fullfile(downloadFolder,“谷歌演讲”);如果~存在(datasetFolder“dir”)disp('下载谷歌语音命令数据集(1.5 GB)…')解压(url,数据集文件夹)终止
创建一个音频数据存储这指向了数据集。
ads=音频数据存储(数据集文件夹,“LabelSource”,“foldername”,“Includesubfolders”,真正的);广告= shuffle(广告);
数据集包含本示例中未使用的背景噪声文件。使用子集创建一个没有背景噪声文件的新数据存储。
isBackNoise = ismember(广告。标签,“背景”);广告(广告,~ isBackNoise) =子集;
该数据集大约有65000个1秒长的30个短单词(包括关键字YES)。获取数据存储中单词分布的细分。
countEachLabel(ads)
ans=30×2表标签计数1713鸟1731猫1733狗1746倒2359八2352五2357四2372走2372快乐1742房子1750左2353马文1746九2364号2357⋮
分裂广告分为两个数据存储:第一个数据存储包含与关键字对应的文件。第二个数据存储包含所有其他单词。
关键词=“是的”;isKeyword=ismember(ads.Labels,关键字);ads_关键字=子集(ads,isKeyword);ads_其他=子集(ads,~isKeyword);
要使用整个数据集对网络进行训练并达到尽可能高的精度,请设置reduceDataset来错误的。要快速运行此示例,请设置reduceDataset来真正的.
还原酶=错误的;如果reduceDataset%将数据集缩减到原来的20倍ads_keyword = splitEachLabel(ads_keyword,round(numel(ads_keyword. files) / 20)); / /将ads_keyword改为ads_keywordnumUniqueLabels =元素个数(独特(ads_other.Labels));ads_other = splitEachLabel(ads_other,round(numel(ads_other. files) / numUniqueLabels / 20)); / /分配标签终止

获取每个数据存储中单词分布的分解。洗牌的其他广告数据存储,以便连续读取返回不同的单词。
countEachLabel (ads_keyword)
ans=1×2表标签计数是2377
countEachLabel(ads_其他)
ans=29×2表标签计数1713鸟1731猫1733狗1746倒2359八2352五2357四2372走2372快乐1742房子1750左2353马文1746九2364号2357⋮
ads_other=洗牌(ads_other);
创建训练句子和标签
训练数据存储包含发出一个单词的1秒语音信号。您将创建更复杂的训练语音,其中包含关键字和其他单词的混合。
下面是一个构造的句子的例子。从关键字数据存储中读取一个关键字,并将其规范化为最大值为1。
是=读取(ads_关键字);是=是/最大值(abs(是));
该信号具有非语音部分(无声、背景噪声等),不包含有用的语音信息。这个例子移除沉默使用侦探讲话.
获取信号中有用部分的开始和结束索引。
SpeechIndex=detectSpeech(是,fs);
随机选择要在合成训练句子中使用的单词数。最多使用10个单词。
numWords=randi([0 10]);
随机选择关键字出现的位置。
关键字位置= randi([1 numWords+1]);
阅读所需数量的非关键词话语,并构建训练句子和口罩。
句子= [];掩码= [];对于索引=1:numWords+1如果index == keywordLocation句子=[句子;yes];% #好吧newMask=0(大小(yes));newMask(speechindex(1,1):speechindex(1,2))=1;mask=[mask;newMask];% #好吧其他的其他=阅读(ads_other);else = Other ./ max(abs(Other));句子=(句子,其他);% #好吧掩码=[掩码;零(大小(其他))];% #好吧终止终止
把训练句子和面具一起画出来。
图t=(1/fs)*(0:长度(句子)-1);图t=图;绘图(t[句子,掩码])网格在xlabel(‘时间’)传说(“训练信号”,“面具”,“位置”,‘东南’)l=findall(图,“类型”,“行”);l(1)。线宽= 2;标题(“话语”)

听训练句子。
声音(句子,fs)
提取特征
本示例使用39个MFCC系数(13 MFCC, 13 delta和13 delta-delta系数)训练一个深度学习网络。
定义MFCC提取所需的参数。
WindowLength = 512;OverlapLength = 384;
创建audioFeatureExtractor对象以执行特征提取。
afe=音频特征提取程序(“SampleRate”,财政司司长,...“窗口”损害(WindowLength“周期性”),...“OverlapLength”OverlapLength,...“mfcc”,真的,...“mfccDelta”,真的,...“mfccDeltaDelta”,真正的);
提取特征。
featureMatrix=摘录(afe,句子);大小(featureMatrix)
ans=1×2478 39
请注意,通过在输入中滑动窗口来计算MFCC,因此特征矩阵比输入语音信号短。每行特征矩阵对应于语音信号的128个样本(窗长-重叠长度).
计算与相同长度的遮罩特征矩阵.
HopLength=WindowLength-重叠长度;范围=HopLength*(1:大小(featureMatrix,1))+HopLength;featureMask=零(大小(范围));对于索引=1:numel(范围)特征掩码(索引)=模式(掩码((索引-1)*跃点长度+1:(索引-1)*跃点长度+窗长度));终止
从训练数据集中提取特征
对整个训练数据集进行句子合成和特征提取是非常耗时的。为了加快处理速度,如果您有Parallel Computing Toolbox™,请对训练数据存储进行分区,并在单独的worker上处理每个分区。
选择一些数据存储分区。
numPartitions = 6;
初始化特征矩阵和掩模的单元格数组。
TrainingFeatures = {};TrainingMasks = {};
使用命令执行句子合成、特征提取和蒙版创建帕弗.
emptyCategories = categorical([1 0]);emptyCategories (:) = [];抽搐帕弗ii = 1:numPartitions subads_keyword = partition(ads_keyword,numPartitions,ii);subads_other =分区(ads_other、numPartitions ii);数= 1;localFeatures =细胞(长度(subads_keyword.Files), 1);localMasks =细胞(长度(subads_keyword.Files), 1);虽然hasdata (subads_keyword)%创造一个训练句子[句子,掩码]=帮助者合成内容(subads\u关键字,subads\u其他,fs,WindowLength);%计算mfcc特性featureMatrix=摘录(afe,句子);featureMatrix(~isfinite(featureMatrix))=0;%创建面具hopLength=WindowLength-重叠长度;范围=(hopLength)*(1:大小(featureMatrix,1))+hopLength;featureMask=零(大小(范围));对于index = 1:numel(range) featureMask(index) = mode(mask((index-1)*hopLength+1:(index-1)*hopLength+WindowLength));终止localFeatures{count}=featureMatrix;localMasks{count}=[emptyCategories,范畴(featureMask)];计数=计数+1;终止TrainingFeatures=[TrainingFeatures;localFeatures];TrainingMasks=[TrainingMasks;localMasks];终止fprintf(“训练特征提取花费了%f秒。\n”,toc)
训练特征提取耗时33.656404秒。
将所有特征归一化,使其均值为零,标准差为单位,这是一个很好的做法。计算每个系数的平均值和标准偏差,并使用它们来规范化数据。
sampleFeature=TrainingFeatures{1};numFeatures=大小(sampleFeature,2);featuresMatrix=cat(1,训练特征{:});如果减少数据集负载(完整文件(netFolder、,“keywordNetNoAugmentation.mat”),“keywordNetNoAugmentation”,“米”,'S');其他的M=平均值(特征矩阵);S=标准值(特征矩阵);终止对于index=1:length(TrainingFeatures)f=TrainingFeatures{index};f=(f-M)。/S;TrainingFeatures{index}=f;% #好吧终止
提取验证特性
从验证信号中提取MFCC特征。
featureMatrix=extract(afe,audioIn);featureMatrix(~isfinite(featureMatrix))=0;
规范化验证特性。
FeaturesValidationClean = (featureMatrix - M)./S;range = HopLength * (1:size(FeaturesValidationClean,1)) + HopLength;
构造验证KWS掩码。
featureMask = 0(大小(范围);对于索引=1:numel(范围)特性掩码(索引)=模式(KWSBaseline((索引-1)*跃点长度+1:(索引-1)*跃点长度+窗长度));终止BaselineV=分类(功能掩码);
定义LSTM网络体系结构
LSTM网络可以学习序列数据时间步长之间的长期依赖关系。本例使用双向LSTM层bilstmLayer(深度学习工具箱)从前后两个方向查看序列。
将输入大小指定为大小顺序numFeatures.指定两个隐藏的双向LSTM层,输出大小为150,并输出一个序列。该命令指示双向LSTM层将输入时间序列映射为150个特性,并传递给下一层。指定两个类,包括大小为2的完全连接层,然后是softmax层和分类层。
层=[...sequenceInputLayer numFeatures bilstmLayer(150年“OutputMode”,“序列”)双层(150,“OutputMode”,“序列”)完整连接层(2)softmaxLayer分类层];
定义培训选项
指定分类器的训练选项。设置最大时代设置为10,以便网络通过训练数据传递10次。设置小批量来64这样网络一次可以查看64个训练信号。设置阴谋来“训练进步”生成随着迭代次数增加而显示训练进度的图。集冗长的来错误的禁用打印与plot.Set中显示的数据相对应的表格输出的步骤洗牌来“每个时代”在每个历元开始时洗牌训练序列。设置LearnRateSchedule来“分段”每次经过一定数量的纪元(5),学习率就降低一个指定的因子(0.1)。集验证数据验证预测值和目标。
此示例使用自适应矩估计(ADAM)解算器。ADAM使用类似LSTM的递归神经网络(RNN)比默认的带动量的随机梯度下降(SGDM)解算器性能更好。
maxEpochs=10;miniBatchSize=64;options=trainingOptions(“亚当”,...“初始学习率”1的军医,...“最大时代”maxEpochs,...“最小批量大小”,小批量,...“洗牌”,“每个时代”,...“冗长”假的,...“ValidationFrequency”、地板(元素个数(TrainingFeatures) / miniBatchSize),...“验证数据”,{FeaturesValidationClean',BaselineV},...“情节”,“训练进步”,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”,0.1,...“LearnRateDropPeriod”,5);
培训LSTM网络
使用指定的培训选项和层架构培训LSTM网络列车网络(深度学习工具箱).由于训练集很大,训练过程可能需要几分钟。
[keywordNetNoAugmentation, netInfo] = trainNetwork (TrainingFeatures、TrainingMasks层,选择);

如果减少数据集负载(完整文件(netFolder、,“keywordNetNoAugmentation.mat”),“keywordNetNoAugmentation”,“米”,'S');终止
检查无噪声验证信号的网络精度
使用经过训练的网络估计验证信号的KWS掩码。
v=分类(关键字网络增强、功能验证清除);
根据实际标签和估计标签的向量计算并绘制验证混淆矩阵。
图cm=混淆图(基线v、v、,“标题”,“验证准确性”);cm.摘要=“column-normalized”;cm.概述=“row-normalized”;

将网络输出从分类转换为双精度。
v=double(v)-1;v=repmat(v,HopLength,1);v=v(:);
监听由网络识别的关键字区域。
声音(audioIn(逻辑(v)), fs)
可视化估计和预期的KWS口罩。
基线=双(BaselineV) - 1;基线= repmat(基线HopLength 1);基线=基线(:);T = (1/fs) * (0:length(v)-1);无花果=图;情节(t) [audioIn(1:长度(v)), v, 0.8 *基线])网格在xlabel(‘时间’)传说(“训练信号”,“网络掩码”,“基线掩码”,“位置”,‘东南’)l=findall(图,“类型”,“行”);l(1)。线宽= 2;l(2)。线宽= 2;标题(“无噪语音的结果”)

检查网络精度是否存在噪声验证信号
现在,您将检查网络精度的噪声语音信号。噪声信号是通过加性高斯白噪声破坏验证信号得到的。
加载嘈杂的信号。
[audioInNoisy,fs]=audioread(完整文件(netFolder,“NoisyKeywordSpeech-16-16-mono-34secs.flac”)); 声音(audioInNoisy,fs)
将信号可视化。
图t = (1/fs) * (0:length(audioInNoisy)-1);情节(t, audioInNoisy)网格在xlabel(‘时间’)头衔(“噪声验证语音信号”)

从噪声信号中提取特征矩阵。
featureMatrixV = extract(afe, audioInNoisy);featureMatrixV (~ isfinite (featureMatrixV)) = 0;FeaturesValidationNoisy = (featureMatrixV - M)./S;
将特征矩阵传递给网络。
v =分类(keywordNetNoAugmentation FeaturesValidationNoisy。');
将网络输出与基线进行比较。注意,精度低于你得到一个干净的信号。
图cm=混淆图(基线v、v、,“标题”,“验证准确性-含噪语音”);cm.摘要=“column-normalized”;cm.概述=“row-normalized”;

将网络输出从分类转换为双精度。
v=double(v)-1;v=repmat(v,HopLength,1);v=v(:);
监听由网络识别的关键字区域。
声音(audioIn(逻辑(v)), fs)
可视化估计和基线遮罩。
t=(1/fs)*(0:length(v)-1);fig=图形;绘图(t[audioInNoisy(1:length(v)),v,0.8*基线)网格在xlabel(‘时间’)传说(“训练信号”,“网络掩码”,“基线掩码”,“位置”,‘东南’)l=findall(图,“类型”,“行”);l(1)。线宽= 2;l(2)。线宽= 2;标题(“含噪语音的结果-无数据增强”)

执行数据增加
经过训练的网络在有噪声的信号上表现不佳,因为经过训练的数据集只包含无噪声的句子。您将通过增加数据集以包含有噪声的句子来纠正这一点。
使用audioDataAugmenter来扩充您的数据集。
ada = audioDataAugmenter (“时间树概率”,0,...“PitchShiftProbability”,0,...“VolumeControlProbability”,0,...“TimeShiftProbability”,0,...“SNRRange”[1],...“AddNoiseProbability”,0.85);
通过这些设置,可以audioDataAugmenter对象以85%的概率破坏带有高斯白噪声的输入音频信号。SNR从范围[-1](dB)中随机选择。增强器不修改输入信号的概率为15%。
例如,将音频信号传递给增强器。
Reset (ads_keyword) x = read(ads_keyword);data =增加(ada, x, fs)
资料=1×2表音频AugmentationInfo ________________ ________________ { 16000×1双}(1×1结构)
检查AugmentationInfo变量数据验证信号是如何修改的。
data.AugmentationInfo
ans=带字段的结构:信噪比:0.3410
重置数据存储。
重置(ads_keyword)重置(ads_other)
初始化特征和遮罩单元。
TrainingFeatures={};TrainingMasks={};
再次执行特征提取。每个信号被噪声破坏的概率为85%,因此您的增强数据集约有85%的噪声数据和15%的无噪声数据。
抽搐帕弗ii = 1:numPartitions subads_keyword = partition(ads_keyword,numPartitions,ii);subads_other =分区(ads_other、numPartitions ii);数= 1;localFeatures =细胞(长度(subads_keyword.Files), 1);localMasks =细胞(长度(subads_keyword.Files), 1);虽然hasdata(subads_关键字)[句子,掩码]=助手合成内容(subads_关键字,subads_其他,fs,WindowLength);%噪音污染增强数据=增强(ada,句子,fs);句子=增强数据.音频{1};%计算mfcc特性featureMatrix=extract(afe,句子);featureMatrix(~isfinite(featureMatrix))=0;hopLength=WindowLength-OverlapLength;range=hopLength*(1:size(featureMatrix,1))+hopLength;featureMask=Zero(size(range));对于index = 1:numel(range) featureMask(index) = mode(mask((index-1)*hopLength+1:(index-1)*hopLength+WindowLength));终止localFeatures{count}=featureMatrix;localMasks{count}=[emptyCategories,范畴(featureMask)];计数=计数+1;终止TrainingFeatures=[TrainingFeatures;localFeatures];TrainingMasks=[TrainingMasks;localMasks];终止fprintf(“训练特征提取花费了%f秒。\n”,toc)
训练特征提取耗时36.090923秒。
计算每个系数的平均值和标准偏差;使用它们来规范化数据。
sampleFeature=TrainingFeatures{1};numFeatures=大小(sampleFeature,2);featuresMatrix=cat(1,训练特征{:});如果减少数据集负载(完整文件(netFolder、,“KWSNet.mat”),“KWSNet”,“米”,'S');其他的M=平均值(特征矩阵);S=标准值(特征矩阵);终止对于index=1:length(TrainingFeatures)f=TrainingFeatures{index};f=(f-M)。/S;TrainingFeatures{index}=f;% #好吧终止
用新的平均值和标准差值对验证特征进行归一化。
FeaturesValidationNoisy = (featureMatrixV - M)./S;
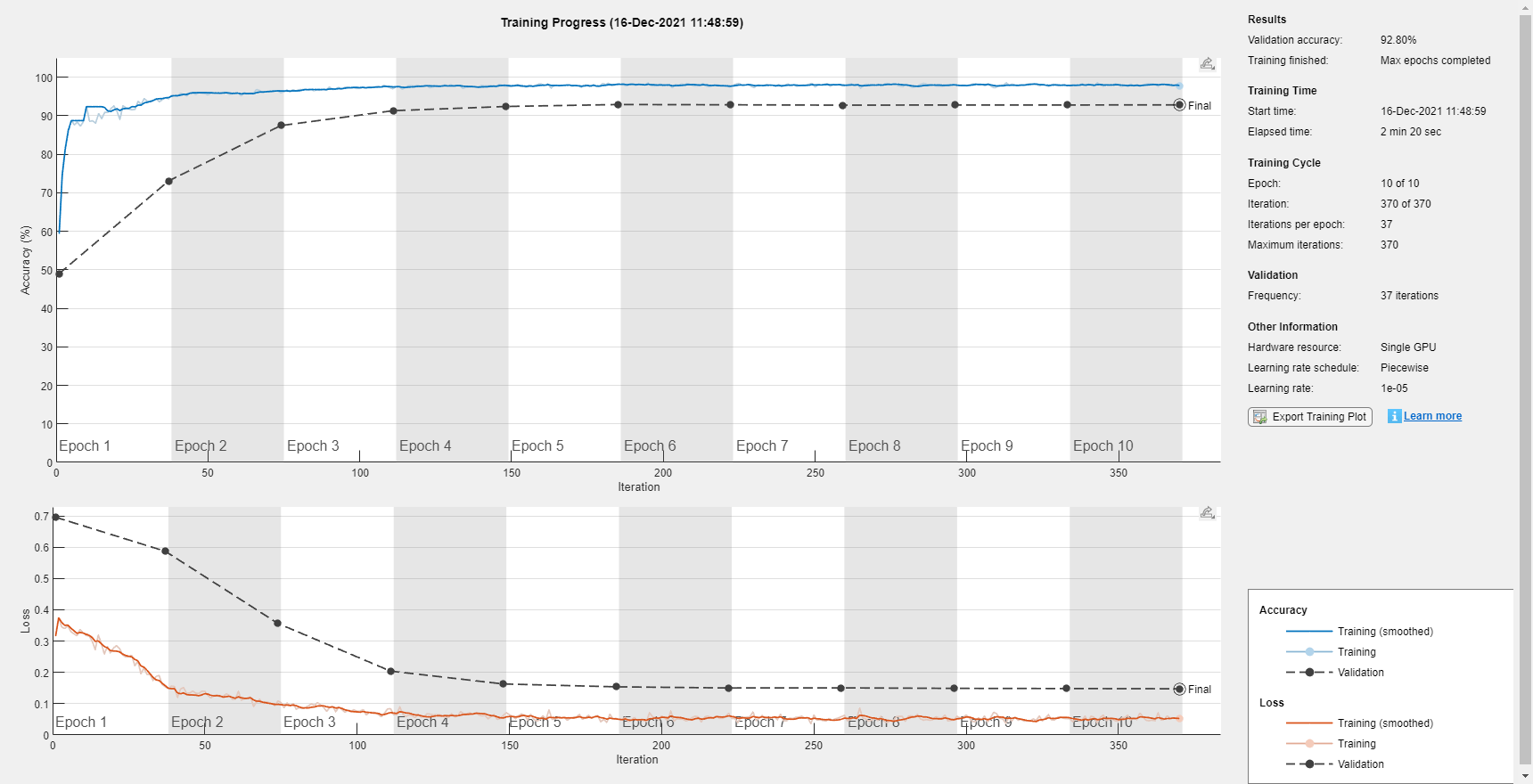
具有扩充数据集的重训练网络
重新创建训练选项。使用噪声基线功能和掩码进行验证。
选择= trainingOptions (“亚当”,...“初始学习率”1的军医,...“最大时代”maxEpochs,...“最小批量大小”,小批量,...“洗牌”,“每个时代”,...“冗长”假的,...“ValidationFrequency”、地板(元素个数(TrainingFeatures) / miniBatchSize),...“验证数据”, BaselineV} {FeaturesValidationNoisy。”...“情节”,“训练进步”,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”,0.1,...“LearnRateDropPeriod”,5);
培训网络。
[KWSNet,netInfo]=列车网络(列车功能、列车屏蔽、图层、选项);
如果减少数据集负载(完整文件(netFolder、,“KWSNet.mat”));终止
验证验证信号上的网络准确性。
v=分类(KWSNet,特征验证噪声);
比较估计和预期的KWS掩码。
图cm=混淆图(基线v、v、,“标题”,“数据增强的验证准确性”);cm.摘要=“column-normalized”;cm.概述=“row-normalized”;

听确定的关键字区域。
v=double(v)-1;v=repmat(v,HopLength,1);v=v(:);声音(audioIn(logical(v)),fs)
可视化估计和预期的面具。
图=图;图(t,[audioInNoisy(1:长度(v)),v,0.8*基线)网格在xlabel(‘时间’)传说(“训练信号”,“网络掩码”,“基线掩码”,“位置”,‘东南’)l=findall(图,“类型”,“行”);l(1)。线宽= 2;l(2)。线宽= 2;标题(“含噪语音的结果-数据增强”)

参考文献
[1]监狱长P。“语音指令:单字语音识别的公共数据集”,2017。可以从https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.Google 2017版权所有。语音命令数据集根据Creative Commons Attribute 4.0许可证获得许可。
附录-辅助功能
函数(句子,面具)= HelperSynthesizeSentence (ads_keyword ads_other, fs,最小长度)%读一个关键词关键字=读取(ads_关键字);关键字=关键字。/max(abs(关键字));%确定感兴趣的区域SpeechIndex=detectSpeech(关键字,fs);如果isempty(speech hindices) || diff(speech hindices (1,:)) <= minlength speech hindices = [1,length(keyword)];终止关键词=关键词(演讲指数(1,1):演讲指数(1,2));%选择其他单词的随机数(介于0和10之间)numWords=randi([0 10]);%选择插入关键字的位置loc=randi([1个单词+1]);句子=[];掩码=[];对于索引=1:numWords+1如果索引==loc句子=[句子;关键字];newMask = 1(大小(关键字));mask = [mask;newMask];其他的其他=读取(ads_other);其他=其他。/max(abs(other));句子=[句子;其他];掩码=[掩码;零(大小(其他))];终止终止终止
您还可以从以下列表中选择网站: