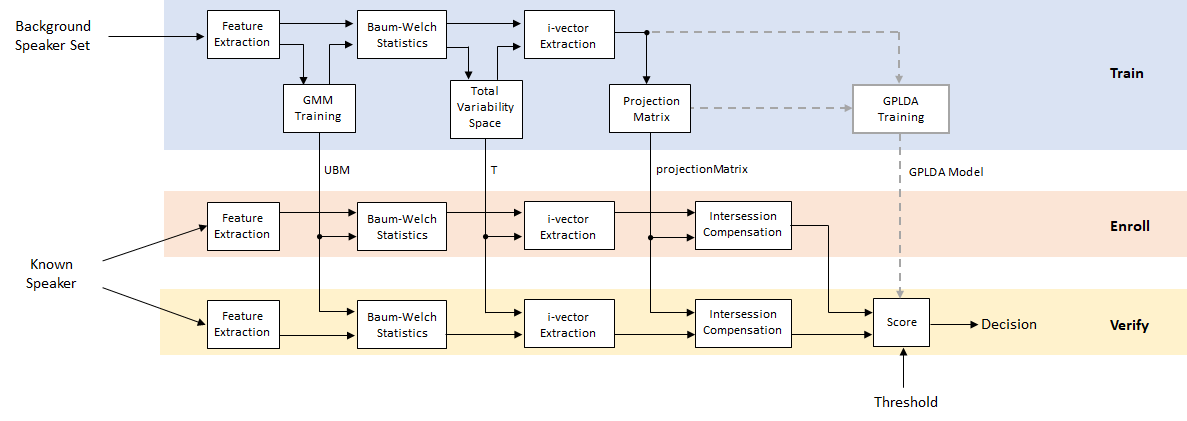
使用i-Vectors进行说话人验证
说话人验证或认证的任务是确认说话人的身份是否属实。多年来,发言人验证一直是一个活跃的研究领域。早期的性能突破是使用高斯混合模型和通用背景模型(GMM-UBM)。[1]在声学特征上(通常mfcc).例如,请参见使用高斯混合模型的说话人验证.GMM-UBM系统的主要困难之一涉及会话间的可变性。联合因素分析(JFA)被提出,以补偿这一变异性分别建模发言者间的变异性和渠道或会话变异性[2][3].然而,[4]发现JFA中的通道因子也包含关于说话人的信息,并建议将通道和说话人空间组合成一个总变性空间.然后使用后端程序(如线性判别分析(LDA)和类内协方差归一化(WCCN))来补偿会话间的变异性,然后是一个评分,如余弦相似度评分。[5]提出用概率LDA (PLDA)模型代替余弦相似度评分。[11]和[12]提出了一种将i向量高斯化的方法,从而在PLDA中做高斯假设,称为G-PLDA或简化PLDA。虽然i向量最初被提出用于说话人的验证,但它已经被应用于许多问题,如语言识别、说话人日记、情感识别、年龄估计和防欺骗[10].最近,已经提出了深度学习技术来替换I-viporsd-vectors或x-vectors[8][6].
使用i向量系统
音频工具箱提供了ivectorSystem它封装了训练i向量系统、注册扬声器或其他音频标签、评估系统的决定阈值、识别或验证扬声器或其他音频标签的能力。看到ivectorSystem提供使用此特性并将其应用于多个应用程序的示例。
要了解更多关于i矢量系统如何工作的信息,请继续看这个例子。
开发i-向量系统
在本例中,您将开发一个标准i向量系统,用于说话人验证,该系统使用LDA-WCCN后端,带有余弦相似度评分或G-PLDA评分。
在整个示例中,您将发现可调参数上的活动控件。更改控件不会重新运行示例。如果更改控件,则必须重新运行该示例。
数据集管理
本例使用Graz University of Technology的Pitch Tracking数据库(PTDB-TUG)[7].数据集由20名英语母语人士读取2342次来自Timit语料库的语音富裕的句子。下载并提取数据集。根据您的系统,下载和提取数据集可能需要大约1.5小时。
url =“https://www2.spsc.tugraz.at/databases/PTDB-TUG/SPEECH_DATA_ZIPPED.zip”;downloadFolder = tempdir;datasetFolder = fullfile (downloadFolder,“PTDB-TUG”);如果~存在(datasetFolder“dir”)disp(“正在下载PTDB-TUG (3.9 G)……”解压缩(url, datasetFolder)结束
下载PTDB-TUG (3.9 G)…
创建一个audioDatastore指向数据集的。该数据集最初用于音高跟踪训练和评估,包括喉镜读数和基线音高决定。仅使用原始录音。
广告= audioDatastore ([fullfile (datasetFolder“语音数据”,“女性”,“麦克风”), fullfile (datasetFolder,“语音数据”,“男性”,“麦克风”),...“IncludeSubfolders”,真的,...“FileExtensions”,“wav”);文件名= ads.Files;
文件名包含扬声器id。对文件名进行解码以设置标签audioDatastore对象。
speakerIDs = extractBetween(文件名,'mic_',“_”);ads.Labels =分类(speakerIDs);countEachLabel(广告)
ans =20×2表标签计数_____ _____ F01 236 F02 236 F03 236 F04 236 F05 236 F06 236 F07 236 F08 234 F09 236 F10 236 M01 236 M02 236 M03 236 M04 236 M05 236 M06 236⋮
分离audioDatastore对象转换为训练、评估和测试集。训练集包含16个扬声器。评估集包含4个演讲者,并进一步分为注册集、评估训练i向量系统的检测误差权衡集和测试集。
developmentLabels =分类([“M01”,“M02”,“M03”,“M04”,“M06”,“M07”,“M08”,“M09”,“F01”,“F02”,“F03”,“F04”,“F06”,“F07”,“F08”,“F09”]);evaluationLabels =分类([“M05”,“M010”,“F05”,“F010”]);adsTrain =子集(广告,ismember (ads.Labels developmentLabels));adsEvaluate =子集(广告,ismember (ads.Labels evaluationLabels));numFilesPerSpeakerForEnrollment =3.;[adsEnroll, adsTest adsDET] = splitEachLabel (adsEvaluate numFilesPerSpeakerForEnrollment 2);

显示结果的标签分布audioDatastore对象。
CountAcneLabel(adstrain)
ans =16×2表标签计数_____ _____ F01 236 F02 236 F03 236 F04 236 F06 236 F07 236 F08 234 F09 236 M01 236 M02 236 M03 236 M04 236 M06 236 M07 236 M08 236 M09 236
countEachLabel (adsEnroll)
ans =2×2表标签计数_____ _____ F05 3 M05 3
countEachLabel (adsDET)
ans =2×2表标签计数_____ _____ F05 231 M05 231
countEachLabel (adsTest)
ans =2×2表标签计数_____ _____ F05 2 M05 2
从训练数据集中读取音频文件,听它,并绘制它。重置数据存储。
[音频、audioInfo] =阅读(adsTrain);fs = audioInfo.SampleRate;t =(0:大小(音频,1)1)/ fs;声音(音频、fs)情节(t)、音频)包含(“时间(s)”) ylabel (“振幅”)轴([0 t(end) -1 1])标题(“来自训练集的样本话语”)
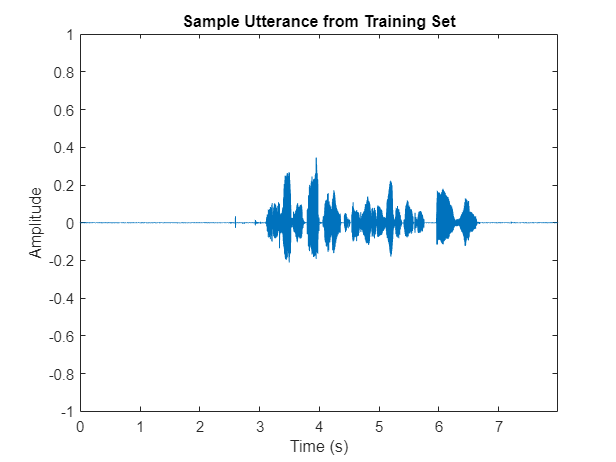
重置(adsTrain)
您可以减少数据集和此示例中使用的参数的数量,以便以性能成本加速运行时。通常,减少数据集是开发和调试的良好做法。
speedUpExample =错误的;如果speedupexample adstrain = spliteachlabel(adstrain,30);ADSDET = SpliteachLabel(ADSDET,21);结束

特征提取
创建一个audioFeatureExtractor对象提取20个mfcc、20个delta- mfcc和20个delta-delta mfcc。使用增量窗口长度为9。提取特征从25 ms Hann窗口与10 ms跳。
numCoeffs =20.;deltaWindowLength =
9;windowDuration =
0.025;hopDuration =
0.01;windowSamples =圆(windowDuration * fs);hopSamples =圆(hopDuration * fs);overlapSamples = windowSamples - hopSamples;afe = audioFeatureExtractor (...“SampleRate”,fs,...“窗口”损害(windowSamples“周期”),...“OverlapLength”overlapSamples,......“mfcc”,真的,...“mfccDelta”,真的,...“mfccDeltaDelta”,真正的);setExtractorParams (afe“mfcc”,“DeltaWindowLength”deltaWindowLength,“NumCoeffs”numCoeffs)




从训练数据存储中读取的音频提取功能。功能返回为anumHops——- - - - - -numFeatures矩阵。
=特征提取(afe、音频);[numHops, numFeatures] =大小(特性)
numHops = 797
numFeatures = 60
培训
训练一个i向量系统在计算上是昂贵和耗时的。如果您有Parallel Computing Toolbox™,您可以将工作分散到多个核上以加快示例的速度。确定系统的最佳分区数。如果您没有并行计算工具箱™,请使用单个分区。
如果〜isempty(ver('平行线'))&&〜SpeedupExample Pool = GCP;numpar = numpartitions(adstrain,pool);别的numPar = 1;结束
使用“本地”配置文件启动并行池(Parpool)连接到并行池(工人数:6)。
特征归一化因子
使用辅助函数,helperFeatureExtraction,从数据集中提取所有特征。的helperFeatureExtraction函数从音频中的语音区域中提取MFCC。语音检测由检测跳孔函数。
featuresAll = {};抽搐parforii = 1:numPar adsPart = partition(adsTrain,numPar,ii);featuresPart =细胞(0,元素个数(adsPart.Files));为了iii = 1:numel(adpart . files) audioData = read(adpart);featuresPart {3} = helperFeatureExtraction (afe audioData, []);结束featuresAll = [featuresAll, featuresPart];结束AllFeatures = Cat(2,包括{:});流(“从训练集中提取特征完成(%0.0f秒)。”toc)
从训练集完成特征提取(58秒)。
计算每个特征的全球平均值和标准偏差。您将在以后调用helperFeatureExtraction函数对特性进行规范化。
normFactors。米ean = mean(allFeatures,2,“omitnan”);normFactors。年代TD = std(allFeatures,[],2,“omitnan”);
通用背景模型(UBM)
初始化高斯混合模型(GMM),它将成为i-vector系统中的通用背景模型(UBM)。组件权重初始化为均匀分布的。在TIMIT数据集上训练的系统通常包含大约2048个组件。
numComponents =64;如果speedUpExample numComponents = 32;结束numComponentsα= 1 (1)/ numComponents;μ= randn (numFeatures numComponents);vari = rand(numFeatures,numComponents) + eps;于是=结构('compoundpropoxt'α,“亩”亩,“σ”,vari);

使用期望 - 最大化(EM)算法列出UBM。
麦克斯特=10;如果speedUpExample maxIter = 2;结束抽搐为了iter = 1:maxiter tic% 期待N = 0(1、numComponents);F = 0 (numFeatures numComponents);S = 0 (numFeatures numComponents);L = 0;parforii = 1:numPar adsPart = partition(adsTrain,numPar,ii);而hasdata(adsPart) audioData = read(adsPart);%提取特征afe, Y = helperFeatureExtraction (audioData normFactors);%计算后验对数可能性logLikelihood = helperGMMLogLikelihood (Y, ubm);%计算后验归一化概率amax = max (logLikelihood [], 1);loglikelihood = max + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);f = Y * gamma;s = (Y *Y) * gamma;%更新足够的话语统计数据N = N + N;F = F + F;S = S + S;%更新日志可能性l = l + sum(loglikelihoodsum);结束结束打印当前日志可能性流('Training UBM: %d/%d complete (%0.0f seconds), Log-likelihood = %0.0f\n',iter,maxiter,toc,l)%最大化N = max (N, eps);于是。ComponentProportion = max(N/sum(N),eps); ubm.ComponentProportion = ubm.ComponentProportion/sum(ubm.ComponentProportion); ubm.mu = F./N; ubm.sigma = max(S./N - ubm.mu.^2,eps);结束

Training UBM: 1/10 complete(59秒),Log-likelihood = -162907120 Training UBM: 2/10 complete(53秒),Log-likelihood = -82282814 Training UBM: 3/10 complete(54秒),Log-likelihood = -78667384 Training UBM: 4/10 complete(55秒),Log-likelihood = -77041863训练UBM: 7/10完成(52秒),Log-likelihood = -75958218训练UBM: 7/10完成(52秒),Log-likelihood = -75724712训练UBM: 8/10完成(53秒),Log-likelihood = -75561701训练UBM: 9/10完成(54秒),Log-likelihood = -75417170训练UBM:10/10完成(55秒),对数可能性= -75275185
计算Baum-Welch统计
鲍姆-韦尔奇的统计数据是N(零级)和F(第一阶)使用最终UBM计算的EM算法中使用的统计信息。
是时刻的特征向量吗 .
,在那里 为发言者的人数。为了训练整个可变性空间,每个音频文件都被认为是一个单独的扬声器(无论它是否属于一个物理的单个扬声器)。
后验概率是UBM的组成部分吗 说明了特征向量 .
通过训练集计算零点和一阶Baum-Welch统计数据。
numSpeakers =元素个数(adsTrain.Files);数控= {};Fc = {};抽搐parforii = 1:numPar adsPart = partition(adsTrain,numPar,ii);numFiles =元素个数(adsPart.Files);Npart =细胞(1、numFiles);Fpart =细胞(1、numFiles);为了jj = 1:numFiles audioData = read(adsPart);%提取特征afe, Y = helperFeatureExtraction (audioData normFactors);%计算后验对数似然logLikelihood = helperGMMLogLikelihood (Y, ubm);%计算后验归一化概率amax = max (logLikelihood [], 1);loglikelihood = max + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);f = Y * gamma;Npart {jj} =重塑(n, 1, 1, numComponents);Fpart {jj} =重塑(f, numFeatures 1 numComponents);结束数控=(数控,Npart);Fc = (Fc, Fpart);结束流('Baum-Welch统计数据已完成(%0.0f秒)。\ n'toc)
Baum-Welch统计完成(54秒)。
将统计数据扩展为矩阵和中心 ,如[3],这样
是一个 对角线矩阵,其块是 .
是一个 通过连接得到的超向量 .
是UBM中组件的数量。
为特征向量中特征的个数。
N =数控;F = Fc;民大=重塑(ubm.mu numFeatures 1, []);为了s = 1:numSpeakers N{s} = repelem(重塑(Nc{s},1,[]),numFeatures);F{s} =重塑(Fc{s} - Nc{s}.*muc,[],1);结束
因为这个例子假设UBM的对角协方差矩阵,N也是对角矩阵,并保存为向量以进行有效计算。
完全变化空间
在i向量模型中,理想说话人超向量由一个说话人无关分量和一个说话人相关分量组成。说话人依赖分量由总变异性空间模型和说话人的i向量组成。
说话人是话语的超向量吗
为与说话人和信道无关的超矢量,可视为UBM超矢量。
为低秩矩形矩阵,表示总变异性子空间。
i向量是说话者的吗
i向量的维数, ,通常远低于C F-Dimension扬声器话语监控器,制作I形载体或i-vocor,一种更紧凑和易易无发言的表示。
为了训练整个可变性空间,
,首先随机初始化T,然后迭代地执行这些步骤[3]:
计算隐藏变量的后验分布。
2.累积扬声器的统计数据。
3.更新总变性空间。
[3]提出初始化 通过UBM方差,然后更新 根据公式:
其中S(S)是居中的二阶Baum-Welch统计量。然而,更新 在实践中经常被放弃,因为收效甚微。这个例子没有更新 .
创建Sigma变量。
σ= ubm.sigma (:);
指定总可变性空间的维度。TIMIT数据集使用的典型值是1000。
numTdim =32;如果speedupexample numtdim = 16;结束

初始化T单位矩阵,并预先分配单元格数组。
T = randn(元素个数(ubm.sigma) numTdim);T = T /规范(T);我=眼睛(numTdim);嗯=细胞(numSpeakers, 1);Eyy =细胞(numSpeakers, 1);Linv =细胞(numSpeakers, 1);
设置训练的迭代次数。报告的典型值是20。
numIterations = 5;
5;

运行训练循环。
为了iterIdx = 1:numIterations% 1。计算隐藏变量的后验分布TtimesInverseSSdiag = (t /σ)';parfors = 1:numSpeakers L = (I + TtimesInverseSSdiag.*N{s}*T);Linv{年代}= pinv (L);是{年代}= Linv{年代}* TtimesInverseSSdiag * F{年代};y{s} = Linv{s} + Ey{s}*Ey{s}';结束% 2。收集所有发言者的数据Eymat =猫(2哦,是吧{:});FFmat =猫(2 F {:});Kt = FFmat * Eymat ';K = mat2cell (Kt、numTdim repelem (numFeatures numComponents));纽特=细胞(numComponents, 1);为了c = 1:numComponents AcLocal = 0 (numTdim);为了s = 1:numSpeakers AcLocal = AcLocal + Nc{s}(:,:,c)*Eyy{s};结束% 3。更新总可变性空间纽特·c {} = (pinv (AcLocal) * K c {}) ';结束猫(T = 1,纽特{:});流('Training Total variation Space: %d/%d complete (%0.0f seconds).\n', numIterations iterIdx toc)结束
训练全部变异性空间:1/5完成(2秒)。训练全部变异性空间:2/5完成(2秒)。训练全部变异性空间:3/5完成(2秒)。训练总变异性空间:4/5完成(1秒)。训练总变异性空间:5/5完成(1秒)。
i矢量提取
一旦计算出总的可变性空间,就可以计算i向量为[4]:
此时,您仍然将每个培训文件视为一个单独的发言者。然而,在下一步中,当您训练投影矩阵来降低维数并增加说话人之间的差异时,i向量必须用适当的、不同的说话人id进行标记。
创建一个单元格数组,其中单元格数组的每个元素包含一个跨文件的i向量矩阵,用于特定扬声器。
演讲者=独特(adsTrain.Labels);numSpeakers =元素个数(扬声器);ivectorPerSpeaker =细胞(numSpeakers, 1);TS = t /σ;TSi = TS ';ubmMu = ubm.mu;抽搐parfor扬声器= 1:NumSpeakers%数据存储的子集到你正在适应的扬声器。adsPart =子集(adsTrain adsTrain.Labels = =扬声器(speakerIdx));numFiles =元素个数(adsPart.Files);ivectorPerFile = 0 (numTdim numFiles);为了fileIdx = 1:numFiles audioData = read(adpart);%提取特征afe, Y = helperFeatureExtraction (audioData normFactors);%计算后验对数似然logLikelihood = helperGMMLogLikelihood (Y, ubm);%计算后验归一化概率amax = max (logLikelihood [], 1);loglikelihood = max + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);f = Y * gamma - n.*(ubmMu);ivectorPerFile(:,fileIdx) = pinv(I + (TS.*repelem(n(:),numFeatures))' * T) * TSi * f(:);结束ivectorPerSpeaker {speakerIdx} = ivectorPerFile;结束流(' i -向量从训练集中提取(%0.0f秒).\n'toc)
从训练集中提取的i-veroors(60秒)。
投影矩阵
对于i向量,已经提出了许多不同的后端。最直接且仍然表现良好的方法是线性判别分析(LDA)和类内协方差归一化(WCCN)的结合。
创建训练向量的矩阵和指示我 - 向量对应哪个扬声器的地图。将投影矩阵初始化为身份矩阵。
w = id vectorperspaeer;发话机展示者= Cellfun(@(x)大小(x,2),w);ivectorstrain =猫(2,w {:});proigndmatrix =眼睛(大小(w {1},1));
LDA试图最小化类内差异,最大化说话者之间的差异。它可以计算为概述[4]:
鉴于:
在哪里
是每个说话人的i向量的均值。
是所有说话人的i向量的均值。
是每个说话人的话语数。
解决最佳特征向量的特征值方程:
最好的特征向量是那些具有最高特征值的人。
performLDA =真正的;如果performLDA tic numEigenvectors =
16;Sw = 0(大小(projectionMatrix, 1));某人= 0(大小(projectionMatrix, 1));wbar =意味着(猫(2 w {:}), 2);为了Ii = 1:numel(w) ws = w{Ii};wsbar =意味着(ws, 2);Sb = Sb + (wsbar - wbar)*(wsbar - wbar)';Sw = Sw + cov(ws',1);结束(~) = eigs(某人,西南,numEigenvectors);= (A / vecnorm (A)) ';= A * ivectorsTrain;w = mat2cell (ivectorsTrain、大小(ivectorsTrain, 1), utterancePerSpeaker);投影矩阵= A *投影矩阵;流('LDA投影矩阵计算(%0.2F秒)。toc)结束


LDA投影矩阵计算(0.22秒)。
WCCN试图与类内协方差相反地缩放i向量空间,因此在i向量比较中,演讲者内部高变异性的方向不被强调[9].
鉴于类内协方差矩阵:
在哪里
是每个说话人的i向量的均值。
是每个说话人的话语数。
解决对于B使用Cholesky分解:
performWCCN =真正的;如果performwccn tic alpha =
0.9;W = 0(大小(projectionMatrix, 1));为了II = 1:NUMER(W)W = W + COV(W {II}',1);结束W = W /元素个数(W);W = (1 - alpha)*W + alpha*eye(size(W,1));B =胆固醇(pinv (W),“低”);投影矩阵= B *投影矩阵;流(“WCCN投影矩阵计算(%0.4f秒)。”toc)结束


计算WCCN投影矩阵(0.0063秒)。
培训阶段现在已经完成。现在可以使用通用背景模型(UBM)、总可变性空间(T)和投影矩阵来登记和验证扬声器。
火车G-PLDA模型
将投影矩阵应用于列车集。
ivectors = cellfun (@ (x) projectionMatrix * x, ivectorPerSpeaker“UniformOutput”、假);
在该示例中实现的该算法是如概述的高斯PLDA[13].在高斯PLDA中,I形载体用以下等式表示:
在哪里 是i向量的全局均值, 是噪声项的全精度矩阵吗 , 为因子载荷矩阵,也称为特征音。
指定要使用的特征音的数量。通常数字在10到400之间。
numegenvoices = 16;
16;

确定不相交的人数,特征向量中的尺寸的数量,以及每个扬声器的话语数量。
K =元素个数(ivectors);D =大小(ivectors {1}, 1);utterancePerSpeaker = cellfun (@ (x)大小(x, 2), ivectors);
找出样本总数,并将i向量居中。
ivectorsMatrix =猫(2,ivectors {:});N =大小(ivectorsMatrix 2);μ=意味着(ivectorsMatrix, 2);= vectorsmatrix -;
从训练的i向量中确定白化矩阵,然后对i向量进行白化。指定ZCA美白,PCA美白,或不美白。
whiteningType =“ZCA”;如果strcmpi (whiteningType“ZCA”) S = cov(vectorsmatrix ');[~, sD, sV] =圣言(年代);W = diag(1 /(sqrt(diag(sD)) + eps))*sV';向量矩阵= W *向量矩阵;elseifstrcmpi (whiteningType主成分分析的) S = cov(vectorsmatrix ');(sV, sD) = eig(年代);W = diag(1 /(sqrt(diag(sD)) + eps))*sV';向量矩阵= W *向量矩阵;别的W =眼睛(大小(ivectorsMatrix, 1));结束

应用长度归一化,然后将训练i向量矩阵转换回单元阵列。
ivectorsMatrix = ivectorsMatrix. / vecnorm (ivectorsMatrix);
计算全局二阶矩为
S = ivectorsMatrix * ivectorsMatrix ';
将训练i向量矩阵转换回单元阵列。
ivectors = mat2cell (ivectorsMatrix D utterancePerSpeaker);
根据样本数量排序,然后按照每个扬声器的话语组分组i-vectors。预计一阶时刻 届人
uniqueLengths =独特(utterancePerSpeaker);numUniqueLengths =元素个数(uniqueLengths);speakerIdx = 1;f = 0 (D、K);为了1: numuniquelengthidx = find(utterancePerSpeaker== uniqueLengthIdx);temp = {};为了speakerIdxWithinUniqueLength = 1:numel(idx) rho = ivectors(idx(speakerIdxWithinUniqueLength));temp =(临时;ρ);% #好< AGROW >f (:, speakerIdx) =(ρ{:},2)总和;speakerIdx = speakerIdx + 1;结束ivectorsSorted {uniqueLengthIdx} = temp;%#OK结束
初始化特征仪矩阵,v和逆噪声方差项, .
v = randn(d,numegenvoices);lambda = pinv(s / n);
指定EM算法的迭代次数,是否采用最小发散值。
numIter =5;最终=
真正的;


使用EM算法训练G-PLDA模型[13].
为了iter = 1: numIter% 期待γ= 0 (numEigenVoices numEigenVoices);EyTotal = 0 (numEigenVoices K);R = 0 (numEigenVoices numEigenVoices);idx = 1;为了lengthIndex = 1:numUniqueLengths ivectorLength = uniqueLengths(lengthIndex);%分离长度相同的i个向量4 = ivectorsSorted {lengthIndex};%计算MM = pinv(ivectorLength*(V'*(Lambda*V)) + eye(numEigenVoices));%[13]中(A.7)式%循环遍历每个扬声器的当前i矢量长度为了speakerIndex = 1:元素个数(iv)% V的潜变量一阶矩嗯= M * V ' *λ* f (:, idx);%[13]中(A.8)式%计算秒矩。Ey = Ey * Ey';%更新RyyR = R + ivectorLength*(M + Eyy);%[13]中(A.13)式%附加EyTotalEyTotal (:, idx) =等等;Idx = Idx + 1;%如果使用最小散度,更新伽马。如果minimumDivergence gamma = gamma + (M + Eyy);%[13]中(A.18)式结束结束结束%计算Ttt = eycotal * f';%[13]中(A.12)式%最大化V = TT ' * pinv (R);[13]中的%等式(A.16)= pinv((S - V*TT)/N);%[13]中(A.17)式%最小差异如果最终伽玛=伽马/ k;%[13]中(A.18)式v = v * chol(伽玛,“低”);%[13]中(A.22)式结束结束
一旦你训练了G-PLDA模型,你就可以使用它来计算一个基于对数似然比的分数[14].给定两个i向量已居中、漂白和长度归一化,分数计算如下:
在哪里 和 是注册和测试的i向量, 为噪声项的方差矩阵, 为特征语音矩阵。的 项是可分解的常数,在实践中可以去掉。
speakerIdx =2;utteranceIdx =
1;w1 = ivectors {speakerIdx} (:, utteranceIdx);speakerIdx =
1;utteranceIdx =
10;wt = ivectors {speakerIdx} (:, utteranceIdx);VVt = V *”;SigmaPlusVVt = pinv(Lambda) + VVt;term1 = pinv([SigmaPlusVVt;VVt SigmaPlusVVt]);term2 = pinv (SigmaPlusVVt);w1wt = (w1; wt);积分= w1wt'*term1*w1wt - w1'*term2*w1 - wt'*term2*wt




分数= 52.4507
在实践中,测试i向量,以及根据您的系统,注册向量,并没有在G-PLDA模型的训练中使用。在下面的评估部分中,您将使用以前未见过的数据进行注册和验证。支持函数万博1manbetx,GPLDASKORE.封装上面的评分步骤,并额外执行居中、白化和规范化。将训练过的G-PLDA模型保存为与支持功能一起使用的结构体万博1manbetxGPLDASKORE..
gpldaModel =结构(“亩”亩,...'whiteningmatrix'W,...'eigenvoices'V,...“σ”pinv(λ));
招收
注册不在培训数据集中的新扬声器。
使用如下步骤序列为注册集中的每个扬声器的每个文件创建i-vectors:
特征提取
鲍姆-韦尔奇统计:确定零阶和一阶统计
i矢量提取
Intersession补偿
然后对文件中的i向量求平均值,为演讲者创建一个i向量模型。为每个说话人重复。
演讲者=独特(adsEnroll.Labels);numSpeakers =元素个数(扬声器);enrolledSpeakersByIdx =细胞(numSpeakers, 1);抽搐parfor扬声器= 1:NumSpeakers%数据存储的子集到你正在适应的扬声器。adsPart =子集(adsEnroll adsEnroll.Labels = =扬声器(speakerIdx));numFiles =元素个数(adsPart.Files);ivectorMat = 0(大小(projectionMatrix, 1), numFiles);为了fileIdx = 1:numFiles audioData = read(adpart);%提取特征afe, Y = helperFeatureExtraction (audioData normFactors);%计算后验对数似然logLikelihood = helperGMMLogLikelihood (Y, ubm);%计算后验归一化概率amax = max (logLikelihood [], 1);loglikelihood = max + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);f = Y * gamma - n.*(ubmMu);% i矢量提取w = pinv (I + (TS。* repelem (n (:), numFeatures))的f * T * TSi * (:);%Intersession补偿w = projectionMatrix * w;ivectorMat (:, fileIdx) = w;结束% i矢量模型enrolledSpeakersByIdx {speakerIdx} =意味着(ivectorMat, 2);结束流('发言者登记(%0.0f秒).\n'toc)
发言者登记(0秒)。
出于记帐的目的,将i-vector单元格数组转换为结构,speaker id作为字段,i-vector作为值
enrolledSpeakers =结构;为了s = 1:numSpeakers enrolledSpeakers.(string(speakers(s)))) = enrolledspeakbyidx {s};结束
验证
可选择CSS评分方法或G-PLDA评分方法。
scoringMethod = “GPLDA”;
“GPLDA”;

误拒率(FRR)
讲话者误拒率(FRR)是给定讲话者被错误拒绝的比率。为已登记的说话人i向量和同一个说话人的i向量创建一个分数数组。
speakersToTest =独特(adsDET.Labels);numSpeakers =元素个数(speakersToTest);scoreFRR =细胞(numSpeakers, 1);抽搐parforspeakerIdx = 1:numSpeakers adpart =子集(adsDET,adsDET. labels ==speakersToTest(speakerIdx));numFiles =元素个数(adsPart.Files);ivectorToTest = enrolledSpeakers。(string (speakersToTest (speakerIdx)));% #好< PFBNS >分数= 0 (numFiles, 1);为了fileIdx = 1:numFiles audioData = read(adpart);%提取特征afe, Y = helperFeatureExtraction (audioData normFactors);%计算后验对数似然logLikelihood = helperGMMLogLikelihood (Y, ubm);%计算后验归一化概率amax = max (logLikelihood [], 1);loglikelihood = max + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);f = Y * gamma - n.*(ubmMu);%提取I-载体w = pinv (I + (TS。* repelem (n (:), numFeatures))的f * T * TSi * (:);%Intersession补偿w = projectionMatrix * w;%的分数如果strcmpi (scoringMethod“CSS”) score(fileIdx) = dot(ivectorToTest,w)/(norm(w)*norm(ivectorToTest));别的得分(fileidx)= gpldaScore(gpldamodel,w,ivectoltest);结束结束scoreFRR {speakerIdx} =分数;结束流('FRR计算(%0.0f秒).\n'toc)
FRR计算(17秒)。
误接受率(FAR)
讲话者错误接受率(FAR)是指不属于讲话者的话语被错误接受为属于讲话者的比例。为已登记的演讲者和不同演讲者的i向量创建一个分数数组。
speakersToTest =独特(adsDET.Labels);numSpeakers =元素个数(speakersToTest);scoreFAR =细胞(numSpeakers, 1);抽搐parforspeakerIdx = 1:numSpeakers adpart =子集(adsDET,adsDET. labels ~=speakersToTest(speakerIdx));numFiles =元素个数(adsPart.Files);ivectorToTest = enrolledSpeakers。(string (speakersToTest (speakerIdx)));% #好< PFBNS >分数= 0 (numFiles, 1);为了fileIdx = 1:numFiles audioData = read(adpart);%提取特征afe, Y = helperFeatureExtraction (audioData normFactors);%计算后验对数似然logLikelihood = helperGMMLogLikelihood (Y, ubm);%计算后验归一化概率amax = max (logLikelihood [], 1);loglikelihood = max + log(sum(exp(logLikelihood-amax),1));gamma = exp(logLikelihood - logLikelihood)';%计算Baum-Welch统计n =总和(γ1);f = Y * gamma - n.*(ubmMu);%提取I-载体w = pinv (I + (TS。* repelem (n (:), numFeatures))的f * T * TSi * (:);% Intersession补偿w = projectionmatrix * w;%的分数如果strcmpi (scoringMethod“CSS”) score(fileIdx) = dot(ivectorToTest,w)/(norm(w)*norm(ivectorToTest));别的得分(fileidx)= gpldaScore(gpldamodel,w,ivectoltest);结束结束scoreFAR {speakerIdx} =分数;结束流(“远远不计算(%0.0f秒)。\ n'toc)
FAR计算(17秒)。
等错误率(EER)
要比较多个系统,您需要一个结合FAR和FRR性能的单一指标。为此,您需要确定等错误率(EER),这是FAR和FRR曲线满足的阈值。在实践中,EER阈值可能不是最佳选择。例如,如果使用说话人验证作为有线传输的多身份验证方法的一部分,FAR很可能比FRR更重要。
阿明= min(猫(scoreFRR {:}, scoreFAR {:}));amax = max(猫(scoreFRR {:}, scoreFAR {:}));thresholdsToTest = linspace (amin amax, 1000);%计算每个阈值的FRR和FAR。如果strcmpi (scoringMethod“CSS”)%在CSS中,较大的分数表示注册和测试向量%相似。FRR =意味着(猫(scoreFRR {}): < thresholdsToTest);远=意味着(猫(scoreFAR {:}) > thresholdsToTest);别的%在G-PLDA中,较小的分数表明注册和测试载体是%相似。FRR =意味着(猫(scoreFRR {:}) > thresholdsToTest);远=意味着(猫(scoreFAR {}): < thresholdsToTest);结束[~,EERThresholdIdx] = min(abs(FAR - FRR));EERThreshold = thresholdsToTest (EERThresholdIdx);无论何时=意味着([(EERThresholdIdx), FRR (EERThresholdIdx)]);图绘制(thresholdsToTest,,“k”,...thresholdsToTest FRR,“b”,...EERThreshold,无论何时,“罗”,'markerfacecolor',“r”)标题(sprintf ('等错误率= %0.4f,阈值= %0.4f',eer,eerthreshold))xlabel(“阈值”) ylabel (的错误率)传说(“虚假录取率”,“误拒率”,“等错误率(EER)”,“位置”,“最佳”网格)在轴紧

万博1manbetx支持功能
特征提取与归一化
函数(特性,numFrames) = helperFeatureExtraction (afe audioData, normFactors)%的输入:% audioData -音频数据的列向量% afe - audioFeatureExtractor对象% normFactors -用于标准化的特征的平均值和标准偏差。%如果正常因素为空,则不应用归一化。%% 输出% feature -提取特征的矩阵%numframes - 返回的帧数(特征向量)%正常化audiodata = audiodata / max(abs(audiodata(:)));%保护禁止纳尼audioData (isnan (audioData)) = 0;分离语音片段idx =检测echech(audiodata,afe.samplevere);特征= [];为了ii = 1:size(idx,1) f = extract(afe,audioData(idx(ii,1):idx(ii,2)));特点=[功能;f];% #好< AGROW >结束%功能正常化如果~isempty(normFactors) features = (features-normFactors. mean ')./normFactors. std ';结束特点=功能”;倒谱平均减法%(用于信道噪声)如果~isempty(normFactors) feature = feature - mean(feature,'全部');结束numFrames =大小(功能,2);结束
高斯多组分混合对数似然
函数L = helperGMMLogLikelihood(x,gmm) xMinusMu = repmat(x,1,1,numel(gmm. componentproportion)) - permute(gmm.mu,[1,3,2]); / /按顺序排列permuteSigma =排列(gmm.sigma[1、3、2]);Lunweighted = -0.5*(sum(log(permuteSigma),1) + sum(xMinusMu.*(xMinusMu./permuteSigma),1) + size(gmm.mu,1)*log(2*pi));temp =挤压(排列(Lunweighted(1、3、2)));如果尺寸(temp, 1) = = 1%如果只有一个帧,末尾的单例维度为%在置换中被移除。这就解释了边缘情况。temp = temp';结束L = temp + log(gmm.ComponentProportion)';结束
G-PLDA得分
函数分数= gpldaScore (w1, gpldaModel wt)%集中数据w1 = w1 - gpldamodel.mu;wt = wt - gpldamodel.mu;%漂白数据= gpldaModel.WhiteningMatrix * 1;wt = gpldaModel.WhiteningMatrix * wt;%长度规范化数据w1 = w1. / vecnorm (w1);wt = wt. / vecnorm (wt);%基于对数似然对i向量的相似性进行评分。VVt = gpldaModel。EigenVoices * gpldaModel.EigenVoices ';SVVt = gpldaModel。σ+ VVt;([SVVt VVt;VVt SVVt]);term2 = pinv (SVVt);w1wt = (w1; wt);Score = w1wt'*term1*w1wt - w1'*term2*w1 - wt'*term2*wt ';结束
参考文献
[1] Reynolds, Douglas A.等,“使用自适应高斯混合模型的说话人验证”。数字信号处理,第10卷,第5期。1-3, 2000年1月,第19-41页。doi.org(crossref),DOI:10.1006 / DSPR.1999.0361。
[2] Kenny, Patrick等,《说话人识别中的联合因素分析与特征通道》。IEEE音频,语音和语言处理汇刊,第15卷,第5期。4, 2007年5月,第1435-47页。doi.org(crossref), doi: 10.1109 / TASL.2006.881693。
[3] Kenny, P.等,《说话人验证中说话人变异性的研究》。《IEEE音频、语音和语言处理汇刊》,第16卷,第5期。5、2008年7月,第980-88页。doi.org(crossref), doi: 10.1109 / TASL.2008.925147。
[4] Dehak, Najim等《说话人验证的前端因素分析》《IEEE音频、语音和语言处理汇刊》,卷。19,没有。4,2011年5月,第788-98页。doi.org(crossref), doi: 10.1109 / TASL.2010.2064307。
Matejka, Pavel, Ondrej Glembek, Fabio Castaldo, m.j. Alam, Oldrich Plchot, Patrick Kenny, Lukas Burget, Jan cernoky。i-Vector Speaker验证中的全协方差UBM和重尾PLDA2011 IEEE声学、语音和信号处理国际会议(ICASSP), 2011年。https://doi.org/10.1109/icassp.2011.5947436。
[6] Snyder, David等,《x -向量:用于说话人识别的鲁棒DNN嵌入》。2018 IEEE声学、语音和信号处理国际会议(ICASSP), IEEE, 2018,第5329-33页。doi.org(crossref), doi: 10.1109 / ICASSP.2018.8461375。
信号处理与语音通信实验室。已于2019年12月12日生效。https://www.spsc.tugraz.at/databases-and-tools/ptdb-tug-pitch-tracking-database-from-graz-university-of-technology.html。
[8] Variani,Ehsan等人。“对于小型足迹文本依赖扬声器验证的深度神经网络。”2014 IEEE声学、语音和信号处理国际会议(ICASSP),IEEE,2014,第4052-56页。doi.org(crossref), doi: 10.1109 / ICASSP.2014.6854363。
[9] Dehak, Najim, Réda Dehak, James R. Glass, Douglas A. Reynolds和Patrick Kenny。“没有评分标准化技术的余弦相似度评分”。奥德赛(2010)。
维尔马,普尔基特和普拉迪普·k·达斯。i -向量在语音处理中的应用:综述国际语音技术杂志,卷。18,不。2015年12月4日,第529-46页。doi.org(crossref), doi: 10.1007 / s10772 - 015 - 9295 - 3。
[11] D. Garcia-Romero和C. Espy-Wilson,“说话人识别系统中的i向量长度归一化分析”。Interspeech, 2011, pp. 249-252。
[12]肯尼,帕特里克。带有重尾先验的贝叶斯说话人验证。奥德赛2010 -演讲者和语言识别研讨会2010年,捷克共和国布尔诺。
Sizov, Aleksandr, Kong Aik Lee和Tomi Kinnunen。统一生物识别认证中的概率线性判别分析变异。《计算机科学结构、句法和统计模式识别》讲义, 2014, 464 - 75。https://doi.org/10.1007/978 - 3 - 662 - 44415 - 3 - _47。
[14] Rajan, Padmanabhan, Anton Afanasyev, Ville Hautamäki,和Tomi Kinnunen. 2014。从单到多注册i -向量:用于说话人验证的实用PLDA评分变体数字信号处理31(八月):93-101。https://doi.org/10.1016/j.dsp.2014.05.001。
你也可以从以下列表中选择一个网站: