浅层神经网络时间序列预测与建模
动态神经网络在时间上很好-系列预测。要查看以开环形式、闭环形式和开/闭环多步预测应用NARX网络的示例,请参阅多步神经网络预测.
提示
有关时间序列数据的深入学习,请参见基于深度学习的序列分类.
例如,假设你有pH中和过程的数据。你想要设计一个网络,可以根据过去的pH值和过去进入罐内的酸碱流量来预测罐内溶液的pH值。总共有2001个时间步长这些序列。
你可以用两种方法来解决这个问题:
使用神经网络时间序列应用程序,如所述使用神经网络时间序列应用程序拟合时间序列数据.
使用命令行函数,如中所述使用命令行函数拟合时间序列数据.
通常,最好从应用程序开始,然后使用应用程序自动生成命令行脚本。在使用任何一种方法之前,首先通过选择数据集定义问题。每个神经网络应用程序都可以访问几个样本数据集,您可以使用工具箱进行实验(参见浅层神经网络的样本数据集)。如果您有要解决的特定问题,可以将自己的数据加载到工作区中。
时间序列网络
你可以训练一个神经网络来解决三类时间序列问题。
NARX网络
在第一类时间序列问题中,您希望预测时间序列的未来值Y(T)根据该时间序列的过去值和第二个时间序列的过去值x(T)这种形式的预测称为具有外部(外部)输入的非线性自回归,或NARX(参见时间序列NARX反馈神经网络的设计),并可写成如下:
Y(T) =F(Y(T– 1), ...,Y(T–D),x(T– 1), ..., (T–D))
根据失业率、GDP等经济变量,使用这个模型来预测股票或债券的未来价值。您还可以使用此模型进行系统识别,在系统识别中,开发模型来表示动态系统,如化学过程、制造系统、机器人、航空航天飞行器等。
NAR网络
在第二类时间序列问题中,只涉及一个序列。时间序列的未来值Y(T)仅根据该系列的过去值进行预测。这种形式的预测称为非线性自回归,或NAR,可写为:
Y(T) =F(Y(T– 1), ...,Y(T–D))
您可以使用此模型预测金融工具,但无需使用配套系列。
非线性输入输出网络
第三个时间序列问题类似于第一类问题,涉及两个序列,一个输入序列x(T)和一个输出序列Y(T).这里您要预测Y(T)从以前的x(T),但不了解Y(T).该输入/输出模型可编写如下:
Y(T) =F(x(T– 1), ...,x(T–D))
NARX模型将提供比该投入产出模型更好的预测,因为它使用了包含在先前数据值中的附加信息Y(T)。但是,在某些应用中,以前的Y(T)将不可用。只有在这些情况下,您才需要使用输入-输出模型而不是NARX模型。
定义问题
来为工具箱定义一个时间序列问题,将一组时间序列预测向量排列为单元格数组中的列。然后,将另一组时间序列响应向量(每个预测器向量的正确响应向量)排列到第二单元阵列中。此外,在某些情况下,您只需要有一个响应数据集。例如,您可以定义以下时间序列问题,在该问题中,您希望使用序列的先前值来预测下一个值:
答复={1 2 3 4 5};
下一节将展示如何使用神经网络时间序列本示例使用工具箱提供的示例数据。
使用神经网络时间序列应用程序拟合时间序列数据
这个例子展示了如何训练一个浅层神经网络来拟合时间序列数据神经网络时间序列应用程序。
打开神经网络时间序列应用程序使用ntstool.
ntstool
选择网络
你可以使用神经网络时间序列应用程序解决三种不同类型的时间序列问题。
在第一类时间序列问题中,您希望预测时间序列的未来值 根据该时间序列的过去值和第二个时间序列的过去值 . 这种形式的预测称为具有外部(外部)输入的非线性自回归网络(NARX)。
在第二类时间序列问题中,只涉及一个序列。时间序列的未来值 仅根据该系列的过去值进行预测。这种形式的预测称为非线性自回归(NAR)。
第三种时间序列问题与第一类类似,因为涉及两个序列,一个输入序列(预测器) 和一个输出序列(响应) .这里你想预测 从以前的值 ,但不了解 .
对于本例,请使用NARX网络。点击选择网络>NARX网络.

选择数据
这个神经网络时间序列该应用程序有示例数据,可以帮助您开始训练神经网络。
要导入示例pH中和过程数据,请选择进口>更多示例数据集>导入pH中和数据集。您可以使用此数据集训练神经网络,以使用酸碱溶液流预测溶液的pH值。如果您从文件或工作区导入自己的数据,则必须指定预测值和响应。
有关导入数据的信息将显示在模型摘要. 此数据集包含2001个时间步长。预测值有两个特征(酸和碱溶液流量),响应有一个特征(溶液pH)。

将数据拆分为培训、验证和测试集。保留默认设置。数据分为:
70%用于培训。
15%用于验证网络是否普遍化,并在过度拟合之前停止培训。
15%用于独立测试网络泛化。
有关数据划分的更多信息,请参阅最优神经网络训练的数据分割.
创建网络
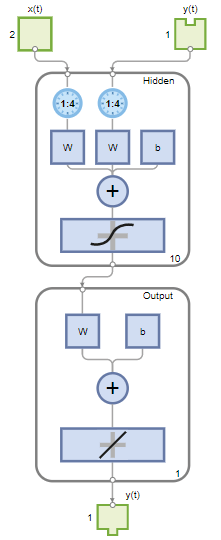
标准NARX网络是一个两层前馈网络,在隐层具有一个S形传递函数,在输出层具有一个线性传递函数。该网络还使用抽头延迟线来存储先前的 和 序列。请注意,NARX网络的输出, ,反馈到网络的输入(通过延迟),因为 是 . 然而,为了进行有效的培训,可以打开此反馈回路。
因为在网络的训练过程中,真实的输出是可用的,所以可以使用如下所示的开环体系结构,使用真实的输出而不是反馈估计的输出。这有两个好处。首先,前馈网络的输入更准确。第二,得到的网络具有纯粹的前馈结构,因此可以使用更高效的算法进行训练。这个网络将在时间序列NARX反馈神经网络的设计.
这个层大小Value定义隐藏神经元的数量。保持默认的图层大小,10. 改变延时重视4.。如果网络培训性能不佳,您可能需要调整这些数字。
您可以在中看到网络体系结构网络窗格。
列车网络
要训练网络,请选择训练>火车与Levenberg-Marquardt. 这是默认的训练算法,与单击相同训练.

与Levenberg Marquardt一起训练(特莱姆)对于大多数问题,建议使用。对于噪声或小问题,贝叶斯正则化(列车司机)可以获得更好的解决方案,但代价是花费更长的时间。对于大型问题,使用比例共轭梯度(共轭梯度)推荐使用,因为它使用的梯度计算比其他两种算法使用的雅可比计算内存效率更高。
在培训窗格中,可以查看培训进度。培训将继续进行,直到满足其中一个停止标准。在本例中,培训将持续进行,直到验证错误连续增加六次(“符合验证标准”)。
分析结果
这个模型摘要包含有关每个数据集的训练算法和训练结果的信息。

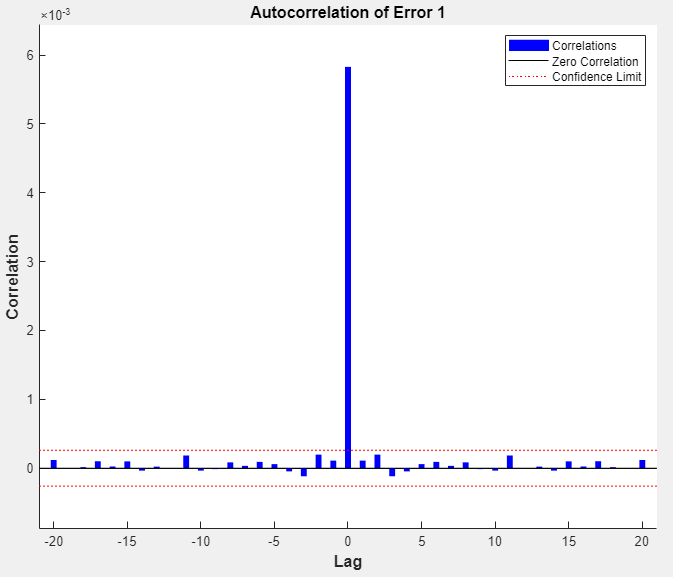
您可以通过生成绘图来进一步分析结果情节部分,单击误差自相关。自相关图描述了预测误差在时间上的关系。对于一个完美的预测模型,自相关函数应该只有一个非零值,并且应该出现在零延迟(这是均方误差)。这意味着预测误差彼此完全不相关(白噪声)。如果预测误差之间存在显著相关性,则可以改进预测-可能通过增加抽头延迟线中的延迟数。在这种情况下,除了零滞后时的相关性外,相关性大约在零周围的95%置信限内,因此模型似乎是可靠的ate。如果需要更精确的结果,您可以重新训练网络。这将改变网络的初始权重和偏差,并可能在重新训练后生成改进的网络。
查看输入错误互相关图以获得网络性能的额外验证。在情节部分,单击输入误差相关. 输入误差互相关图说明了误差如何与输入序列相关 。对于一个完美的预测模型,所有相关性都应为零。如果输入与误差相关,则可能通过增加抽头延迟线中的延迟数来改善预测。在这种情况下,大多数相关性都在零附近的置信范围内。

在情节部分,单击回应. 这将显示输出、响应(目标)和错误与时间的关系。它还指示为培训、测试和验证选择了哪些时间点。
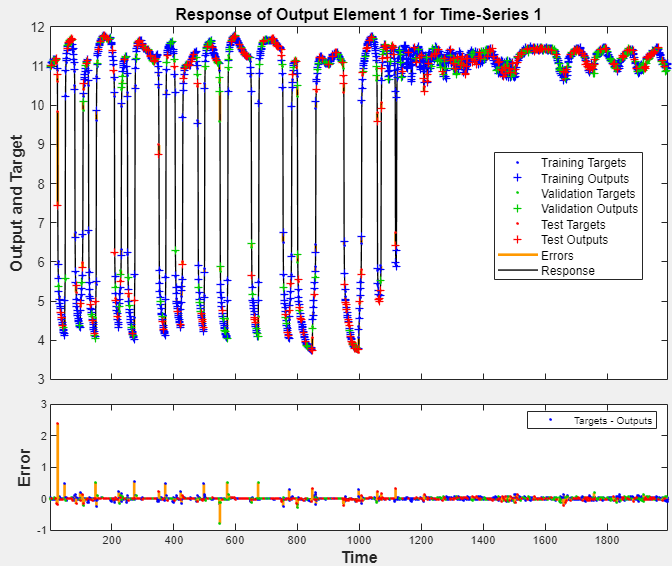
如果您对网络性能不满意,可以执行以下操作之一:
再次训练网络。
增加隐藏神经元的数量。
使用更大的训练数据集。
如果训练集性能较好,而测试集性能较差,这可能表明模型过拟合。减小层的大小,从而减少神经元的数量,可以减少过拟合。
您还可以在其他测试集上评估网络性能。要加载附加测试数据以评估网络,请在试验部分,单击试验.这个模型摘要显示其他测试数据结果。您还可以生成图来分析其他测试数据结果。
生成代码
挑选生成代码>生成简单的培训脚本创建MATLAB代码以从命令行重现前一步骤。如果要了解如何使用工具箱的命令行功能来自定义培训过程,则创建MATLAB代码可能会有所帮助。在使用命令行函数拟合时间序列数据,您将更详细地研究生成的脚本。
出口网络
您可以将经过培训的网络导出到工作区或Simulink®。您还可以使用MATLAB编译器部署网络™ 工具和其他MA万博1manbetxTLAB代码生成工具。要导出经过培训的网络和结果,请选择出口模式>出口到工作区.

使用命令行函数拟合时间序列数据
了解如何使用工具箱的命令行功能的最简单方法是从应用程序生成脚本,然后修改它们以自定义网络培训。例如,请查看上一节中使用神经网络时间序列应用程序。
用NARX神经网络解决外部输入的自回归问题%由神经时间序列应用程序生成的脚本%已创建2021年5月13日17:34:27%%此脚本假定定义了以下变量:%%输入时间序列。%phTargets-反馈时间序列。X=pHputs;T=phTargets;%选择一个训练函数%有关所有培训功能的列表,请键入:help nntrain%“trainlm”通常是最快的。%“trainbr”需要更长的时间,但可能更好地解决具有挑战性的问题。%“trainscg”使用更少的内存。适用于内存不足的情况。列车=“trainlm”;%Levenberg-Marquardt反向传播。%创建具有外部输入的非线性自回归网络inputDelays = 1:4;feedbackDelays = 1:4;hiddenLayerSize = 10;网= narxnet (inputDelays feedbackDelays hiddenLayerSize,“开放式”,trainFcn);%为训练和模拟准备数据%函数PREPARETS为特定网络准备时间序列数据,%按填充输入状态和图层的最小量移动时间%使用PREPARETS可以保留原始的时间序列数据%未更改,但可以轻松地为具有不同%具有开环或闭环反馈模式的延迟数。[x,xi,ai,t]=preparets(net,x,{},t);%培训、验证和测试数据的设置部门净divideParam.trainRatio=70/100;net.divideParam.valRatio=15/100;net.divideParam.testRatio=15/100;%培训网络(净,tr) =火车(净,x, t, xi, ai);%测试网络净(y = x, xi, ai);e = gsubtract (t、y);性能=执行(净、t、y)%查看网络视图(净)%阴谋%取消注释这些行以启用各种绘图。%图,绘图仪(tr)%图,plottrainstate(tr)%, ploterrhist (e)%图,曲线回归(t,y)%图,绘图仪响应(t,y)%, ploterrcorr (e)%图,绘图仪CORR(x,e)%闭环网络%使用此网络进行多步预测。%函数CLOSELOOP将反馈输入替换为直接输入%来自输出层的连接。netc=闭环(净);netc.name=[net.name“-闭环”];视图(netc) (xc、xic aic, tc) = preparets (netc, X, {}, T);yc = netc (xc、xic aic);closedLoopPerformance =执行(净、tc、yc)%超前预报网络%对于某些应用程序,提前一个时间步进行预测是有帮助的。%原始网络同时返回预测的y(t+1)%给定y(t+1)。对于某些应用程序,如决策,它将%一旦y(t)可用,但在%实际y(t+1)出现。可以使网络返回其输出a通过删除一个延迟,使它的最小点击延迟是现在%0而不是1。新网络返回与原始网络相同的输出%网络,但输出左移一个时间步。网络=远程传送(网络);nets.name=[net.name“——提前一步预测”];视图(网络)[xs,xis,ais,ts]=preparets(网络,X,{},T);ys=nets(xs,xis,ais);stepAheadPerformance=perform(网络,ts,ys)
您可以保存脚本,然后从命令行运行脚本以复制上一个应用程序会话的结果。您还可以编辑脚本以自定义培训过程。在这种情况下,请按照脚本中的每个步骤进行操作。
选择数据
脚本假定预测器和响应向量已经加载到工作区中。如果未加载数据,可以按如下方式加载:
负载PHU数据集
菲恩普茨以及回应pHTargets进入工作区。
此数据集是工具箱中的示例数据集之一。有关可用数据集的信息,请参见浅层神经网络的样本数据集。您还可以通过输入命令查看所有可用数据集的列表帮助创建数据集. 您可以使用自己的变量名从这些数据集中的任何一个加载变量。例如,命令
[X,T]=PHU数据集;
X并将pH数据集响应输入细胞阵列T.
选择训练算法
定义训练算法。网络使用默认的Levenberg-Marquardt算法(特莱姆)用于培训。
列车=“trainlm”;%Levenberg-Marquardt反向传播。
对于Levenberg Marquardt没有产生精确结果的问题,或者对于大数据问题,考虑将网络训练函数设置为贝叶斯正则化(Bayesian正则化)。列车司机)或标度共轭梯度(共轭梯度),分别与
网。TrainFcn = 'trainbr'; net.trainFcn = 'trainscg';
创建网络
创建一个网络。NARX网络,narxnet,是一个前馈网络,在隐层具有默认的tan-sigmoid传递函数,在输出层具有线性传递函数。该网络有两个输入。一个是外部输入,另一个是来自网络输出的反馈连接。网络训练完成后,可以关闭此反馈连接,您将在后面的步骤中看到。对于这些输入中的每一个,都有一个抽头延迟线来存储以前的值。要为NARX网络分配网络架构,必须选择与每个抽头延迟线相关的延迟,以及隐藏层神经元的数量。在以下步骤中,将输入延迟和反馈延迟的范围指定为1到4,隐藏神经元的数量指定为10。
inputDelays = 1:4;feedbackDelays = 1:4;hiddenLayerSize = 10;网= narxnet (inputDelays feedbackDelays hiddenLayerSize,“开放式”,trainFcn);
注
增加神经元的数量和延迟的数量需要更多的计算,当数量设置得太高时,这有一种过度拟合数据的趋势,但它允许网络解决更复杂的问题。更多的层需要更多的计算,但它们的使用可能导致网络更有效地解决复杂问题。要使用多个隐藏层,请在中输入隐藏层大小作为数组元素narxnet指挥部。
为培训准备数据
为培训准备数据。当训练包含抽头延迟线的网络时,需要用网络的预测器和响应的初始值填充延迟。有一个工具箱命令可促进此过程-准备工作。此函数有三个输入参数:网络、预测器和响应。此函数返回填充网络中抽头延迟线所需的初始条件,以及已删除初始条件的修改预测器和响应序列。您可以按如下方式调用此函数:
[x,xi,ai,t]=preparets(net,x,{},t);
把数据
建立数据的划分。
净divideParam.trainRatio=70/100;net.divideParam.valRatio=15/100;net.divideParam.testRatio=15/100;
通过这些设置,数据将被随机划分,70%用于培训,15%用于验证,15%用于测试。
列车网络
培训网络。
(净,tr) =火车(净,x, t, xi, ai);
在培训期间,将打开以下培训窗口。此窗口显示培训进度,并允许您通过单击在任意点中断培训停止训练.

当验证错误连续增加六次迭代时,此培训停止。
测试网络
测试网络。训练网络后,可以使用它计算网络输出。以下代码计算网络输出、错误和总体性能。请注意,要模拟带有抽头延迟线的网络,需要为这些延迟信号指定初始值。这是通过输入状态完成的(西)层状态(人工智能)提供人准备工作在早期阶段。
净(y = x, xi, ai);e = gsubtract (t、y);性能=执行(净、t、y)
性能=0.0147
查看网络
查看网络图。
视图(净)
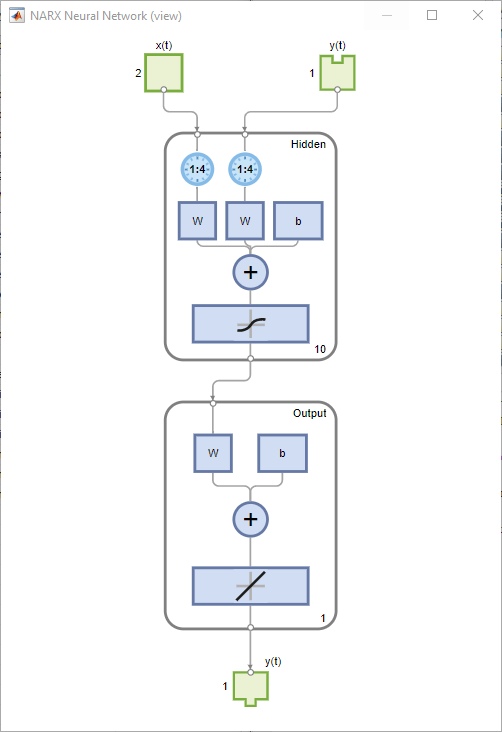
分析结果
绘制性能培训记录,以检查潜在的过度装配。
图,绘图仪(tr)

此图显示,在突出显示的历元之前,训练和验证错误会减少。似乎没有发生过任何过拟合,因为验证错误在此时间之前不会增加。
所有的培训都是在开环(也称为串并联体系结构)中完成的,包括验证和测试步骤。典型的工作流程是在开环中完全创建网络,并且只有在对其进行培训(包括验证和测试步骤)后,才将其转换为闭环以进行多步预测。同样地R价值观神经网络时间序列根据开环训练结果计算app。
闭环网络
关闭NARX网络上的环路。当NARX网络上的反馈回路打开时,它将执行一步超前预测。它正在预测未来的价值Y(T)从以前的Y(T)及x(T).当反馈回路闭合时,它可用于执行多步超前预测。这是因为预测Y(T)将用于替代的实际未来值Y(T).下面的命令可以用来关闭循环并计算闭环性能
netc=闭环(净);netc.name=[net.name“-闭环”];视图(netc) (xc、xic aic, tc) = preparets (netc, X, {}, T);yc = netc (xc、xic aic);closedLoopPerformance =执行(净、tc、yc)
ClosedLoop性能=1.3979

超前预报网络
从网络中移除延迟,以便提前一个时间步获得预测。
网络=远程传送(网络);nets.name=[net.name“——提前一步预测”];视图(网络)[xs,xis,ais,ts]=preparets(网络,X,{},T);ys=nets(xs,xis,ais);stepAheadPerformance=perform(网络,ts,ys)
stepAheadPerformance = 0.0147

从该图中,您可以看到该网络与之前的开环网络相同,只是每个抽头延迟线都已消除了一个延迟。然后,网络的输出为Y(T+1)代替Y(T)。当为某些应用程序部署网络时,这有时可能会有所帮助。
下一步
如果网络性能不令人满意,您可以尝试以下任何方法:
要获得更多命令行操作的经验,请尝试以下任务:
由于随机的初始权重和偏差值,以及将数据划分为训练集、验证集和测试集的不同,每次训练神经网络都会导致不同的解决方案。因此,针对同一问题训练的不同神经网络,对于相同的输入,可以得到不同的输出。为了确保找到了精度较高的神经网络,需要多次再训练。
如果需要更高的精度,还有其他几种技术可以改进初始解。有关详细信息,请参阅万博 尤文图斯提高浅层神经网络泛化能力,避免过拟合.
另见
神经网络拟合|神经网络时间序列|神经网络模式识别|神经网络聚类|火车|准备工作|narxnet|闭环|表演|去除胶束
相关话题
您还可以从以下列表中选择网站:
