使用YOLO v3深度学习的对象检测代码生成
本示例展示了如何为带有自定义层的“只看一次”(YOLO) v3对象检测器生成CUDA®MEX。YOLO v3在YOLO v2的基础上进行了改进,增加了多尺度的检测,以帮助检测较小的物体。此外,用于训练的损失函数被分离为均方误差用于边界盒回归和二元交叉熵用于目标分类,以帮助提高检测精度。本例中使用的YOLO v3网络是从使用YOLO v3深度学习的目标检测计算机视觉工具箱(TM)中的示例。有关更多信息,请参见使用YOLO v3深度学习的目标检测(计算机视觉工具箱)。
第三方的先决条件
要求
支持CUDA的NVIDIA®GPU和兼容的驱动程序。
可选
对于非mex构建,如静态、动态库或可执行文件,此示例具有以下附加要求。
NVIDIA CUDA工具包。
NVIDIA cuDNN库。
编译器和库的环境变量。有关更多信息,请参见第三方硬件(GPU编码器)和设置必备产品s manbetx 845(GPU编码器)。
验证GPU环境
要验证用于运行此示例的编译器和库是否已正确设置,请使用coder.checkGpuInstall(GPU编码器)函数。
envCfg = coder.gpuEnvConfig(“主机”);envCfg。DeepLibTarget =“cudnn”;envCfg。DeepCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
v3组网
本例中使用的YOLO v3组网基于squeezenet,并采用SqueezeNet中的特征提取网络,最后增加了两个检测头。第二检测头的尺寸是第一检测头的两倍,因此能够更好地检测小物体。请注意,可以根据要检测的对象的大小指定任意数量的不同大小的检测头。YOLO v3网络使用使用训练数据估计的锚盒来获得与数据集类型相对应的更好的初始先验,并帮助网络学习准确地预测锚盒。有关锚框的信息,请参见用于对象检测的锚盒(计算机视觉工具箱)。
本例中的YOLO v3组网如下图所示。
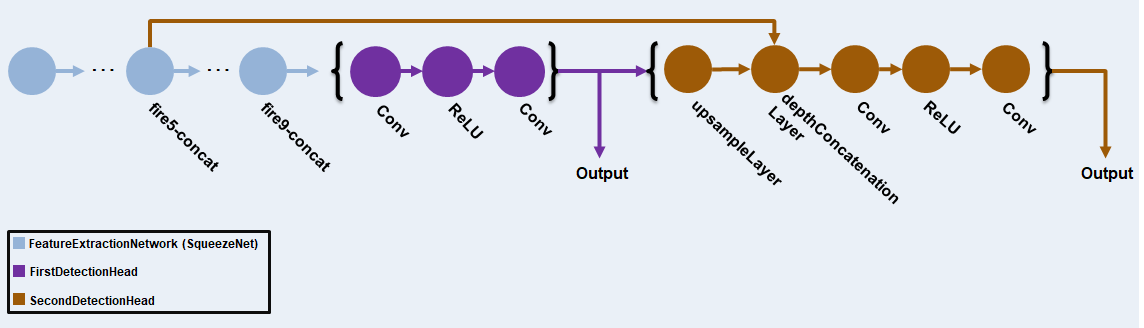
每个检测头预测各自锚框蒙版的边界框坐标(x, y,宽度,高度)、对象置信度和类概率。因此,对于每个检测头,最后一个卷积层的输出滤波器个数等于锚盒掩码个数乘以每个锚盒的预测元素个数。检测头包括所述网络的输出层。
预训练YOLO v3网络
下载YOLO v3网络。
fileName = matlab.internal.examples.download万博1manbetxSupportFile(“视觉/数据/”,“yolov3SqueezeNetVehicleExample_21a.zip”);解压缩(文件名);
本例中使用的YOLO v3网络使用中描述的步骤进行训练使用YOLO v3深度学习的目标检测(计算机视觉工具箱)。
matFile =“yolov3SqueezeNetVehicleExample_21a.mat”;pretrained = load(matFile);Net = pretrained.net;
YOLO v3网络使用aresize2dLayer(图像处理工具箱)通过以2的比例因子复制相邻的像素值来调整二维输入图像的大小。resize2DLayer是作为支持代码生成的自定义层实现的。万博1manbetx有关更多信息,请参见为代码生成定义自定义深度学习层。
注意:您还可以使用通过计算机视觉工具箱™模型的YOLO v3对象检测支持包提供的预训练检测器网络。万博1manbetx
要使用此预训练网络,必须首先从附加组件资源管理器中安装用于YOLO v3对象检测的计算机视觉工具箱模型。有关安装附加组件的详细信息,请参见获取和管理附加组件。
然后,保存网络yolov3ObjectDetector对象到mat文件,然后继续。例如,
= yolov3ObjectDetector(“darknet53-coco”);net =检测器。network;matFile =“pretrainedYOLOv3Detector.mat”;保存(matFile,“净”);
的yolov3Detect入口点函数
的yolov3Detect入口点函数接受输入图像,并将其传递给经过训练的网络进行预测yolov3Predict函数。的yolov3Predict函数将网络对象从mat文件加载到持久变量中,并在随后的预测调用中重用持久对象。具体来说,该函数使用dlnetwork中训练的网络的表示使用YOLO v3深度学习的目标检测(计算机视觉工具箱)的例子。从YOLO v3网格单元坐标得到的预测yolov3Predict然后使用支持函数将调用转换为边界框坐标万博1manbetxgenerateTiledAnchors和applyAnchorBoxOffsets。
类型(“yolov3Detect.m”)
function [bboxes,scores,labelsIndex] = yolov3Detect(matFile, im,…)networkInputSize, networkOutputs, confencethreshold,…overlapThreshold, classes) % yolov3Detect函数用于检测图像中的边界框、分数和% labelsIndex。The MathWorks, Inc. %%预处理数据%本例将所有预处理转换应用于训练期间应用的数据集,除了数据增强。由于示例%使用预训练的YOLO v3网络,因此输入数据必须代表原始数据的%,并且不进行修改,以便进行无偏评估。具体地说,下列预处理操作应用于输入数据。% 1。将图像大小调整为网络输入大小,因为图像比networkInputSize大%。2.在%[0 1]范围内缩放图像像素。 3. Convert the resized and rescaled image to a dlarray object. im = dlarray(preprocessData(im, networkInputSize), "SSCB"); imageSize = size(im,[1,2]); %% Define Anchor Boxes % Specify the anchor boxes estimated on the basis of the preprocessed % training data used when training the YOLO v3 network. These anchor box % values are same as mentioned in "Object Detection Using YOLO v3 Deep % Learning" example. For details on estimating anchor boxes, see "Anchor % Boxes for Object Detection". anchors = [ 41 34; 163 130; 98 93; 144 125; 33 24; 69 66]; % Specify anchorBoxMasks to select anchor boxes to use in both the % detection heads of the YOLO v3 network. anchorBoxMasks is a cell array of % size M-by-1, where M denotes the number of detection heads. Each % detection head consists of a 1-by-N array of row index of anchors in % anchorBoxes, where N is the number of anchor boxes to use. Select anchor % boxes for each detection head based on size-use larger anchor boxes at % lower scale and smaller anchor boxes at higher scale. To do so, sort the % anchor boxes with the larger anchor boxes first and assign the first % three to the first detection head and the next three to the second % detection head. area = anchors(:, 1).*anchors(:, 2); [~, idx] = sort(area, 'descend'); anchors = anchors(idx, :); anchorBoxMasks = {[1,2,3],[4,5,6]}; %% Predict on Yolov3 % Predict and filter the detections based on confidence threshold. predictions = yolov3Predict(matFile,im,networkOutputs,anchorBoxMasks); %% Generate Detections % indices corresponding to x,y,w,h predictions for bounding boxes anchorIndex = 2:5; tiledAnchors = generateTiledAnchors(predictions,anchors,anchorBoxMasks,... anchorIndex); predictions = applyAnchorBoxOffsets(tiledAnchors, predictions,... networkInputSize, anchorIndex); [bboxes,scores,labelsIndex] = generateYOLOv3DetectionsForCodegen(predictions,... confidenceThreshold, overlapThreshold, imageSize, classes); end function YPredCell = yolov3Predict(matFile,im,networkOutputs,anchorBoxMask) % Predict the output of network and extract the confidence, x, y, % width, height, and class. % load the deep learning network for prediction persistent net; if isempty(net) net = coder.loadDeepLearningNetwork(matFile); end YPredictions = cell(coder.const(networkOutputs), 1); [YPredictions{:}] = predict(net, im); YPredCell = extractPredictions(YPredictions, anchorBoxMask); % Apply activation to the predicted cell array. YPredCell = applyActivations(YPredCell); end
评估目标检测的入口函数
按照以下步骤计算来自测试数据的图像上的入口点函数。
将置信度阈值指定为0.5,以只保留置信度分数高于此值的检测。
将重叠阈值指定为0.5,以消除重叠检测。
从输入数据中读取图像。
使用入口点函数
yolov3Detect以获取预测的边界框、置信度分数和类标签。显示带有边界框和置信度分数的图像。
定义所需的阈值。
confidenceThreshold = 0.5;overlapThreshold = 0.5;
指定训练网络的网络输入大小和网络输出数量。
networkInputSize = [227 227];networkOutputs = numel(net.OutputNames);
读取从标记数据集中获得的示例图像数据使用YOLO v3深度学习的目标检测(计算机视觉工具箱)的例子。此图像包含一个类型为vehicle的对象实例。
I = imread()“vehicleImage.jpg”);
指定类名。
classNames = {“汽车”};
在YOLO v3网络上调用检测方法并显示结果。
[bboxes,scores,labelsIndex] = yolov3Detect(matFile,I,)...networkInputSize、networkOutputs confidenceThreshold overlapThreshold,类名);labels = classNames(labelsIndex);%显示图像上的检测结果IAnnotated = insertObjectAnnotation(I,“矩形”、bboxes strcat(标签,{“——”}, num2str(分数)));图imshow (IAnnotated)

生成CUDA MEX
生成CUDA®代码yolov3Detect入口点功能,创建一个GPU代码配置对象为一个MEX目标,并设置目标语言为c++。使用编码器。DeepLearningConfig(GPU编码器)函数创建一个CuDNN深度学习配置对象,并将其分配给DeepLearningConfig属性的GPU代码配置对象。
. cfg = code . gpuconfig (墨西哥人的);cfg。TargetLang =“c++”;cfg。DeepLearningConfig =编码器。DeepLearningConfig(TargetLibrary=“cudnn”);args = {coder.Constant(matFile),I,coder.Constant(networkInputSize),...confidenceThreshold coder.Constant (networkOutputs),...overlapThreshold,一会};codegen配置cfgyolov3Detectarg游戏arg游戏报告
代码生成成功:查看报告
要为TensorRT目标生成CUDA®代码,请创建并使用TensorRT深度学习配置对象而不是CuDNN配置对象。同样,为了生成MKLDNN目标的代码,创建一个CPU代码配置对象,并使用MKLDNN深度学习配置对象作为其DeepLearningConfig财产。
运行生成的MEX
使用相同的图像输入调用生成的CUDA MEX我和前面一样,显示结果。
[bboxes,scores,labelsIndex] = yolov3Detect_mex(matFile, 1,...networkInputSize、networkOutputs confidenceThreshold,...overlapThreshold,类名);labels = classNames(labelsIndex);图;IAnnotated = insertObjectAnnotation(I,“矩形”、bboxes strcat(标签,{“——”}, num2str(分数)));imshow (IAnnotated);

效用函数
下面列出的实用程序函数基于中使用的函数使用YOLO v3深度学习的目标检测(计算机视觉工具箱)示例和修改以使实用程序函数适合于代码生成。
类型(“applyActivations.m”)
版权所有:The MathWorks, Inc. numCells = size(YPredCell, 1);YPredCell{iCell,idx} = sigmoidActivation(YPredCell{iCell,idx});YPredCell{iCell, idx} = exp(YPredCell{iCell, idx});end end for iCell = 1:numCells YPredCell{iCell, 6} = sigmoidActivation(YPredCell{iCell, 6});end end function out = sigmoidActivation(x) out = 1 /(1+exp(-x));结束
类型(“extractPredictions.m”)
版权所有:The MathWorks, Inc. numPredictionHeads = size(YPredictions, 1);预测= cell(numPredictionHeads,6);for ii = 1:numPredictionHeads %获取所需的特征大小信息。numChannelsPred = size(YPredictions{ii},3);nummanchors = size(anchorBoxMask{ii},2);numPredElemsPerAnchors = numChannelsPred/ nummanchors;allIds = (1:numChannelsPred);stride = numPredElemsPerAnchors;endIdx = numChannelsPred;YPredictionsData = extractdata(yprediction{ii}); % X positions. startIdx = 1; predictions{ii,2} = YPredictionsData(:,:,startIdx:stride:endIdx,:); xIds = startIdx:stride:endIdx; % Y positions. startIdx = 2; predictions{ii,3} = YPredictionsData(:,:,startIdx:stride:endIdx,:); yIds = startIdx:stride:endIdx; % Width. startIdx = 3; predictions{ii,4} = YPredictionsData(:,:,startIdx:stride:endIdx,:); wIds = startIdx:stride:endIdx; % Height. startIdx = 4; predictions{ii,5} = YPredictionsData(:,:,startIdx:stride:endIdx,:); hIds = startIdx:stride:endIdx; % Confidence scores. startIdx = 5; predictions{ii,1} = YPredictionsData(:,:,startIdx:stride:endIdx,:); confIds = startIdx:stride:endIdx; % Accumulate all the non-class indexes nonClassIds = [xIds yIds wIds hIds confIds]; % Class probabilities. % Get the indexes which do not belong to the nonClassIds classIdx = setdiff(allIds, nonClassIds, 'stable'); predictions{ii,6} = YPredictionsData(:,:,classIdx,:); end end
类型(“generateTiledAnchors.m”)
函数tiledAnchors = generateTiledAnchors(YPredCell,anchorBoxes,…)版权所有:the MathWorks, Inc. numPredictionHeads = size(YPredCell,1);tiledAnchors = cell(numPredictionHeads, size(anchorIndex, 2));对于i = 1:numPredictionHeads锚= anchorBoxes(anchorBoxMask{i},:);[h,w,~,n] = size(YPredCell{i,1});[tiledAnchors{2},我tiledAnchors{1}我]= ndgrid (h - 0: 0: w1,…1:尺寸(锚,1),1:n);[~, ~, tiledAnchors{我3}]= ndgrid (h - 0: 0: w1,锚(:,2),1:n);[~, ~, tiledAnchors{我4}]= ndgrid (h - 0: 0: w1,锚(:1),1:n);结束结束
类型(“applyAnchorBoxOffsets.m”)
函数YPredCell = applyAnchorBoxOffsets(tiledAnchors,YPredCell,…Copyright 2020-2021 the MathWorks, Inc. for i = 1:size(YPredCell,1) [h,w,~,~] = size(YPredCell{i,1});YPredCell{i,anchorIndex(1)} = (tiledAnchors{i,1}+…YPredCell{我anchorIndex(1)})。/ w;YPredCell{i,anchorIndex(2)} = (tiledAnchors{i,2}+…YPredCell{我anchorIndex (2)}) / h;YPredCell{i,anchorIndex(3)} = (tiledAnchors{i,3}.*…YPredCell{我anchorIndex(3)})。/ inputImageSize (2);YPredCell{i,anchorIndex(4)} = (tiledAnchors{i,4}.*…YPredCell{我anchorIndex(4)})。/ inputImageSize (1); end end
类型(“preprocessData.m”)
调整图像的大小,并将像素缩放到0到1之间。版权所有:The MathWorks, Inc. imgSize = size(图片);将单通道的输入图像转换为3通道。if nummel (imgSize) < 1 image = repmat(image,1,1,3);End image = im2single(rescale(image));image = iLetterBoxImage(image,coder.const(targetSize(1:2)));end function Inew = iLetterBoxImage(I,targetSize) % LetterBoxImage通过保留输入图像I的宽度和高度%长宽比返回一个调整大小的图像。'targetSize'是一个1 × 2的向量,包含%的目标尺寸。% %输入I可以是uint8、uint16、int16、双精度、单精度或逻辑精度,并且%必须是实数且非稀疏的。[Irow,Icol, icchannels] = size(I); % Compute aspect Ratio. arI = Irow./Icol; % Preserve the maximum dimension based on the aspect ratio. if arI<1 IcolFin = targetSize(1,2); IrowFin = floor(IcolFin.*arI); else IrowFin = targetSize(1,1); IcolFin = floor(IrowFin./arI); end % Resize the input image. Itmp = imresize(I,[IrowFin,IcolFin]); % Initialize Inew with gray values. Inew = ones([targetSize,Ichannels],'like',I).*0.5; % Compute the offset. if arI<1 buff = targetSize(1,1)-IrowFin; else buff = targetSize(1,2)-IcolFin; end % Place the resized image on the canvas image. if (buff==0) Inew = Itmp; else buffVal = floor(buff/2); if arI<1 Inew(buffVal:buffVal+IrowFin-1,:,:) = Itmp; else Inew(:,buffVal:buffVal+IcolFin-1,:) = Itmp; end end end
参考文献
1.雷蒙,约瑟夫和阿里·法哈蒂。“YOLOv3:渐进式改进。”预印本,提交2018年4月8日。https://arxiv.org/abs/1804.02767。
