代码生成的语义分割网络
这个例子显示了一个代码生成图像分割的应用程序,使用深度学习。它使用codegen命令来生成一个墨西哥人函数执行预测DAG网络对象SegNet[1],深入学习网络进行图像分割。
第三方的先决条件
要求
这个示例中生成CUDA墨西哥人,有以下第三方的要求。
CUDA®启用NVIDIA GPU®和兼容的驱动程序。
可选
等non-MEX构建静态、动态库或可执行文件,这个例子有以下额外的需求。
英伟达工具包。
英伟达cuDNN图书馆。
环境变量的编译器和库。有关更多信息,请参见第三方硬件(GPU编码器)和设置必备产品s manbetx 845(GPU编码器)。
验证GPU环境
使用coder.checkGpuInstall(GPU编码器)函数来确认所需的编译器和库运行这个例子是正确设置。
envCfg = coder.gpuEnvConfig (“主机”);envCfg。DeepLibTarget =“cudnn”;envCfg。DeepCodegen = 1;envCfg。安静= 1;coder.checkGpuInstall (envCfg);
分割网络
SegNet[1]是一种卷积神经网络(CNN)设计语义图像分割。这是一个深encoder-decoder多层次pixel-wise分割网络训练CamVid[2]数据集和导入MATLAB®推理。SegNet[1]训练部分像素属于11类,包括天空、建筑,钢管,道路,人行道,树,SignSymbol,栅栏,汽车,行人和骑自行车。
信息培训语义分割网络MATLAB使用CamVid[2]数据集,明白了语义分割使用深度学习。
的segnet_predict入口点函数
的segnet_predict.m入口点函数接受一个图像输入和执行预测图像通过使用保存在深度学习网络SegNet.mat文件。加载的网络对象的函数SegNet.mat文件到一个持续的变量mynet和重用持久变量对后续预测调用。
类型(“segnet_predict.m”)
函数= segnet_predict () % # codegen % MathWorks版权2018 - 2019,公司持续mynet;如果isempty (mynet) mynet = coder.loadDeepLearningNetwork (“SegNet.mat”);结束%通过在输入=预测(mynet,);
得到Pretrained SegNet DAG网络对象
网= getSegNet ();
下载pretrained SegNet (107 MB)…
DAG网络包含91层包括卷积,批处理规范化,池、unpooling,像素分类输出层。使用analyzeNetwork函数显示深度学习网络的交互式可视化体系结构。
analyzeNetwork(净);
墨西哥人运行代码生成
生成CUDA代码segnet_predict.m入口点函数,创建一个GPU代码配置对象为一个墨西哥人的目标和目标语言设置为c++。使用coder.DeepLearningConfig(GPU编码器)函数创建一个CuDNN深度学习配置对象,并将其分配给DeepLearningConfigGPU代码配置对象的属性。运行codegen命令指定一个输入(360480 3)的大小。这个值对应于输入层的大小SegNet。
cfg = coder.gpuConfig (墨西哥人的);cfg。TargetLang =“c++”;cfg。DeepLearningConfig = coder.DeepLearningConfig (“cudnn”);codegen配置cfgsegnet_predictarg游戏{(360480 3 uint8)}报告
代码生成成功:查看报告,打开(“codegen /墨西哥人/ segnet_predict / html / report.mldatx”)。
运行生成的墨西哥人
加载和显示一个输入图像。调用segnet_predict_mex在输入图像。
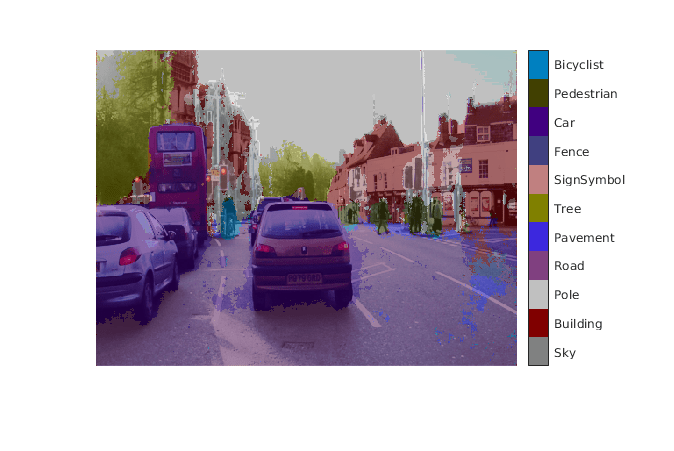
我= imread (“gpucoder_segnet_image.png”);imshow (im);predict_scores = segnet_predict_mex (im);

的predict_scores变量是一个三维矩阵,11频道对应pixel-wise预测分数为每个类。计算通道通过使用最大预测分数pixel-wise标签。
[~,argmax] = max (predict_scores [], 3);
覆盖输入图像上的分段标签和显示分割区域。
类= [“天空”“建筑”“极”“路”“路面”“树”“SignSymbol”“篱笆”“汽车”“行人”“自行车”];提出= camvidColorMap ();argmax SegmentedImage = labeloverlay (im,“ColorMap”,提出);图imshow (SegmentedImage);pixelLabelColorbar(提出、类);
引用
[1]Badrinarayanan Vijay,亚历克斯·肯德尔和罗伯托·Cipolla。“SegNet:深度图像分割卷积Encoder-Decoder架构。”arXiv预印本arXiv: 1511.00561,2015年。
加布里埃尔·[2]Brostow J。朱利安Fauqueur,罗伯托Cipolla。“语义视频对象类:高清地面实况数据库。”模式识别的字母30卷,问题2,2009年,页88 - 97。
