使用联合学习培训网络
这个例子展示了如何使用联邦学习训练网络。联邦学习是一种允许您以分布式、去中心化的方式训练网络的技术[1]。
联邦学习允许使用来自不同数据源的数据训练模型,而无需将数据移动到中心位置,即使各个数据源与数据集的总体分布不匹配。这就是所谓的非独立和相同分布(非iid)数据。当训练数据很大,或者在传输训练数据时存在隐私问题时,联邦学习尤其有用。
联合学习技术而不是分发数据,将多个模型列入与数据源相同的位置。您可以通过定期收集和组合本地训练模型的可读参数来创建从所有数据源中学到的全局模型。通过这种方式,您可以在没有集中处理任何培训数据的情况下培训全局模型。
这个示例使用联邦学习来使用高度非iid的数据集并行训练分类模型。该模型使用数字数据集进行训练,该数据集由1万张数字0到9的手写图像组成。该示例使用10个worker并行运行,每个worker处理单个数字的图像。通过在每一轮训练后平均网络的可学习参数,每个工人的模型可以在所有类中提高性能,而不需要处理其他类的数据。
虽然数据隐私是联合学习的应用之一,但此示例不处理维护数据隐私和安全性的详细信息。此示例演示了基本联合学习算法。
设置并行环境
创建一个具有与数据集中类相同数量的worker的并行池。对于本例,使用带有10个工作器的本地并行池。
池= parpool (“本地”10);numWorkers = pool.NumWorkers;
加载数据集
本示例中使用的所有数据最初存储在一个集中的位置。要使该数据高度非iid,您需要根据类在工人之间分发数据。要创建验证和测试数据集,需要将一部分数据从工作人员转移到客户机。数据正确设置后,工人各班的培训数据和客户端各班的测试验证数据,在培训过程中不进行进一步的数据传输。
指定包含图像数据的文件夹。
digitdatasetpath = fullfile(matlabroot,'工具箱',“nnet”,“nndemos”,...“nndatasets”,'digitdataset');
把数据分发给工人。每个工作人员只接收一个数字的图像,例如工作人员1接收数字0的所有图像,工作人员2接收数字1的图像,等等。
每个数字的图像都存储在以该数字命名的单独文件夹中。在每个工人身上,使用fullfile函数指定特定类文件夹的路径。然后,创建一个imageDatastore它包含了这个数字的所有图像。接下来,使用splitEachLabel功能以随机分隔30%的数据以用于验证和测试。最后,创造一个augmentedImageDatastore包含训练数据。
inputSize = [28 28 1];spmddigitDatasetPath = fullfile(digitDatasetPath,num2str(labindex - 1));imd = imageDatastore (digitDatasetPath,...'upplyubfolders',真的,...'labelsource',“foldernames”);[imdsTrain, imdsTestVal] = splitEachLabel (imd, 0.7,“随机”);augimdsTrain = augmentedImageDatastore (inputSize (1:2), imdsTrain);结束
要在培训期间和之后测试组合的全局模型的性能,创建包含所有类图像的测试和验证数据集。将来自每个工作人员的测试和验证数据与单个数据存储相结合。然后,将此数据存储拆分为两个数据存储,每个数据存储区包含15%的整体数据 - 一个用于在培训期间验证网络,另一个用于在培训后测试网络。
文件列表= [];labelList = [];为i = 1:numWorkers tmp = imdsTestVal{i};文件列表=猫(1,文件列表,tmp.Files);labelList =猫(1 labelList tmp.Labels);结束imdsGlobalTestVal = imageDatastore(文件列表);imdsGlobalTestVal。标签= labelList;[imdsGlobalTest, imdsGlobalVal] = splitEachLabel (imdsGlobalTestVal, 0.5,“随机”);augimdsGlobalTest = augmentedImageDatastore (inputSize (1:2), imdsGlobalTest);augimdsGlobalVal = augmentedImageDatastore (inputSize (1:2), imdsGlobalVal);
现在对数据进行了这样的安排,使得每个工作者都拥有来自单个类的数据来进行培训,客户机持有来自所有类的验证和测试数据。
定义网络
确定数据集中的类数。
类=类别(imdsGlobalTest.Labels);numClasses =元素个数(类);
定义网络架构。
图层= [imageInputLayer(inputSize,“归一化”,“没有”,“名字”,“输入”32岁的)convolution2dLayer (5“名字”,'conv1') reluLayer (“名字”,“relu1”) maxPooling2dLayer (2“名字”,“maxpool1”64年)convolution2dLayer(5日,“名字”,“conv2”) reluLayer (“名字”,“relu2”) maxPooling2dLayer (2“名字”,“maxpool2”)全连接列(numcrasses,“名字”,'fc') softmaxLayer (“名字”,“softmax”)];Lgraph = LayerGraph(层);
从层图中创建dlnetwork对象。
dlnet = dlnetwork (lgraph)
dlnet = dlnetwork with properties: Layers: [9×1 nnet.cnn.layer.Layer]连接:[8×2 table]可学习表:[6×3 table]状态:[0×3 table] InputNames: {'input'} OutputNames: {'softmax'} Initialized: 1
定义模型梯度函数
创建函数modelGradients,列于模型梯度函数这个例子的部分,需要一个dlnetwork对象和具有相应标签的一小批输入数据,并返回损失相对于网络中可学习参数的梯度和相应的损失。
定义联邦平均函数
创建函数federatedAveraging,列于联邦平均功能这个示例的一部分,它获取每个worker上的网络的可学习参数和每个worker的归一化因子,并返回所有网络上的平均可学习参数。使用普通学习参数来更新每个工作人员的全局网络和网络。
定义计算精度函数
创建函数computeAccuracy,列于计算精度函数这个例子的部分,需要一个dlnetwork对象中的数据集小公子对象和类列表,并返回数据集中所有观察值的预测准确性。
指定培训选项
在培训过程中,工人定期向客户传递他们的网络可学习参数,以便客户可以更新全局模型。训练分为几轮。在每一轮训练结束时,对可学习参数进行平均,并更新全局模型。然后,工人模型被新的全局模型所取代,并继续对工人进行培训。
训练300轮,每轮5个纪元。在每一轮中进行少量时间点的培训,可以确保员工的网络在平均之前不会偏离太远。
numRounds = 300;numEpochsperRound = 5;miniBatchSize = 100;
指定SGD优化选项。指定初始学习速率为0.001,动量为0。
learnRate = 0.001;动量= 0;
火车模型
为自定义迷你批处理预处理函数创建一个函数句柄preprocessMiniBatch(定义在Mini-Batch预处理功能部分示例)。
在每个工人上,找到在该工人上本地处理的培训观察的总数。当你在每一轮通信之后找到平均的可学习参数时,使用这个数字来规范化每个工人的可学习参数。如果每个工人的数据量有差异,这有助于平衡平均值。
在每个工人身上,创造一个小公子在培训期间,对象处理和管理迷你批次图像。对于每个迷你批处理:
使用自定义小批量预处理功能对数据进行预处理
preprocessMiniBatch将标签转换为一个热的编码变量。使用尺寸标签格式化图像数据
“SSCB”(空间,空间,通道,批处理)。默认情况下,小公子对象将数据转换为dlarray底层类型的对象单.不要向类标签添加格式。如果有可用的GPU,训练。默认情况下,
小公子对象将每个输出转换为gpuArray如果可用GPU。使用GPU需要并行计算工具箱™和支持的GPU设备。万博1manbetx有关支持设备的信息,请参阅发布(并行计万博1manbetx算工具箱)的GPU支持。
预处理= @ (x, y) preprocessMiniBatch (x, y,类);spmdsizeOfLocalDataset = augimdsTrain.NumObservations;兆贝可= minibatchqueue (augimdsTrain,...“MiniBatchSize”miniBatchSize,...“MiniBatchFcn”,预处理,...'minibatchformat',{“SSCB”,''});结束
创建一个小公子对象,该对象管理要在培训期间使用的验证数据。使用相同的设置小公子在每一个工人。
mbqGlobalVal = minibatchqueue (augimdsGlobalVal,...“MiniBatchSize”miniBatchSize,...“MiniBatchFcn”,预处理,...'minibatchformat',{“SSCB”,''});
初始化训练进度图。
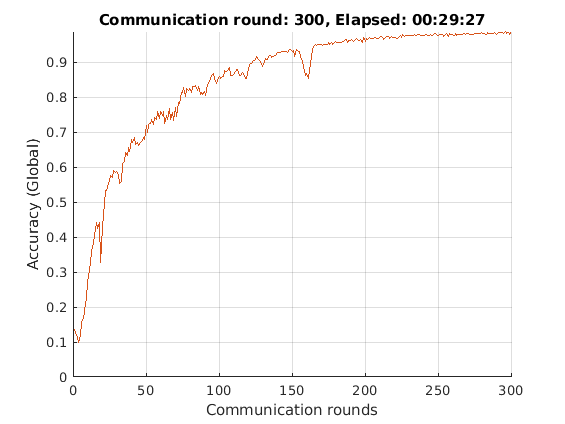
animatedline = animatedline(“颜色”[0.85 0.325 0.098]);ylim([0正])包含(“沟通”轮)ylabel(“精度(全球)”网格)在
初始化SGDM求解器的速度参数。
速度= [];
初始化全局模型。首先,全局模型对每个工人具有与未经训练的网络相同的初始参数。
与= dlnet;
使用自定义训练循环训练模型。对于每一轮的交流,
用最新的全球网络更新员工的网络。
对网络的工人进行五个时期的培训。
求所有网络的平均参数
federatedAveraging函数。用平均值替换全局网络参数。
使用验证数据计算更新后的全球网络的准确性。
显示培训进度。
对于每个epoch,将数据打乱并在小批数据上循环。对于每个迷你批处理:
评估模型的梯度和损失
dlfeval和modelGradients功能。参数更新本地网络参数
sgdmupdate函数。
开始=抽搐;为轮= 1:numRoundsspmd发送全局更新的参数到每个工作者。dlnet.learnables.Value = GlobalModel.Learnables.Value;%循环纪元。为时代= 1:numEpochsperRound%Shuffle数据。洗牌(兆贝可);%循环小批。尽管hasdata(兆贝可)%读取小批数据。[dlX, dlT] =下一个(兆贝可);%使用dlfeval和dlfeval评估模型渐变,状态和损失梯度的功能和更新网络状态。[渐变,损失] = DLFeval(@ Maposgradients,DLNet,DLX,DLT);%使用SGDM优化器更新网络参数。[dlnet,速度]= sgdmupdate (dlnet、渐变速度,learnRate动量);结束结束收集每个worker上更新的可学习参数。workerLearnables = dlnet.Learnables.Value;结束%基于数据比率查找每个工人的归一化因子那个工人被解雇了。sizeOfAllDatasets =总和([sizeOfLocalDataset {:}));normalizationFactor = [sizeOfLocalDataset {}): / sizeOfAllDatasets;用新的可学习参数更新全局模型,归一化和百分比对所有工人平均。GlobalModel.Learnables.Value = FederatedAveraging(WorkerLearnables,NormalizationFactor);%计算全局模型的精度。精度= computeAccuracy(与、mbqGlobalVal、类);%显示全局模型的训练进度。d =持续时间(0,0,toc(start),“格式”,“hh: mm: ss”);Addpoints(LineAccuralyTrain,Rounds,Double(精度))标题(“通信圆:”+轮+”,过去:“+字符串(d))绘制结束
在最后一轮培训之后,用最终的平均可学习参数更新每个工人的网络。如果您想继续使用或培训员工网络,这是很重要的。
spmddlnet.learnables.Value = GlobalModel.Learnables.Value;结束
测试模型
通过将测试集上的预测与真实标签进行比较,检验模型的分类准确率。
创建一个小公子管理测试数据的对象。使用相同的设置小公子培训和验证期间使用的对象。
mbqGlobalTest = minibatchqueue (augimdsGlobalTest,...“MiniBatchSize”miniBatchSize,...“MiniBatchFcn”,预处理,...'minibatchformat',“SSCB”);
使用computePredictions函数来计算预测的类,并计算在所有测试数据中预测的准确性。
精确度= CopareAccuracy(GlobalModel,MBQGlobaltest,课程)
精度=单0.9873
在完成计算之后,可以删除并行池。的gcp函数返回当前并行池对象,以便删除池。
删除(gcp (“nocreate”));
模型梯度函数
的modelGradients函数接受一个dlnetwork对象DLNET.,输入数据的小批处理dlX与相应的标签T并返回损失相对于可学习参数的梯度DLNET.和损失。要自动计算渐变,请使用dlgradient.函数。要计算训练期间网络的预测,可以使用向前函数。
功能[gradient,loss] = modelGradients(dlnet,dlX,T) dlYPred = forward(dlnet,dlX);损失= crossentropy (dlYPred T);梯度= dlgradient(损失、dlnet.Learnables);结束
计算精度函数
的computePredictions函数接受一个dlnetwork对象DLNET., 一种小公子对象MBQ.和类列表,并返回所提供的数据集上所有预测的准确性。要在验证期间或训练结束后计算网络的预测,可以使用预测函数。
功能准确率= compute准确率(dlnet,mbq,classes)预测= [];correctPredictions = [];洗牌(兆贝可);尽管Hasdata(MBQ)[DLXTEST,DLTTEST] =下一个(MBQ);ttest = onehotdecode(dlttest,classes,1)';dlypred =预测(Dlnet,Dlxtest);ypred = onehotdecode(dlypred,classes,1)';预测= [预测;ypred];classpredictions = [纠正案例;Ypred == ttest];结束predSum =总和(correctPredictions);精度=单(predSum. /尺寸(correctPredictions 1));结束
Mini-Batch预处理功能
preprocessMiniBatch函数通过以下步骤对数据进行预处理:
从传入单元格数组中提取图像数据并将其连接到数字阵列中。通过第四维度连接图像数据将第三维度添加到每个图像,以用作单例通道维度。
从传入的单元格数组中提取标签数据,并将其连接到沿第2维的分类数组中。
单热编码分类标签到数字阵列中。编码到第一维度生成与网络输出的形状匹配的编码阵列。
功能[x,y] = preprocessminibatch(Xcell,Ycell,类)%连接。猫(X = 4,伊势亚{1:结束});%从细胞中提取标签数据并连接。Y =猫(2,YCell{1:结束});%一次热编码标签。Y = onehotencode (Y, 1,“类名”,课程);结束
联邦平均功能
功能federatedAveraging函数在每个工作人员和每个工作人员的归一化因子上获取网络的学习参数,并返回所有网络的平均被动参数。使用普通学习参数来更新每个工作人员的全局网络和网络。
功能learnables = federated平均(workerLearnables,normalizationFactor) numWorkers =大小(normalizationFactor,2);%初始化容器的平均可读性,与现有的大小相同%可学的。以第一工作者网络的可学习对象为例。exampleLearnables = workerLearnables {1};可学的=细胞(高度(exampleLearnables), 1);为i = 1:高度(可学习的)可学习的{i} =零(大小(示例可学习的{i}),“喜欢”(exampleLearnables{我}));结束%将所有工人的归一化可学习参数加入%计算平均值。为i = 1:numWorkers tmp = workerLearnables{i};为值= 1:numel(学习)学习栏{value} = learnables {value} + normalizationfactor(i)。* tmp {值};结束结束结束
参考文献
另请参阅
dlarray|dlfeval|dlgradient.|dlnetwork|dlupdate|小公子|sgdmupdate
相关话题
您还可以从以下列表中选择一个网站:
