滑动窗口方法和指数加权方法
移动对象和块使用滑动窗口方法和指数加权方法中的一个或两个计算流信号的移动统计。滑动窗口方法具有有限的脉冲响应,而指数加权方法具有无限脉冲响应。要在有限的数据持续时间内分析统计信息,请使用滑动窗口方法。指数加权方法需要较少的系数并且更适合于嵌入式应用。
| 对象,块 | 滑动窗口方法 | 指数加权方法 |
|---|---|---|
DSP.MedianFilter.那中位过滤器 |
✓ | |
dsp.movingverage.那平均移动 |
✓ | ✓ |
dsp.movingmaximum.那移动最大值 |
✓ | |
dsp.movingminimum.那移动最少 |
✓ | |
dsp.movingrms.那移动rms |
✓ | ✓ |
dsp.movingstandddeviation.那移动标准偏差 |
✓ | ✓ |
dsp.movingvariance.那移动方差 |
✓ | ✓ |
滑动窗口方法
在滑动窗口方法中,指定长度的窗口,Len.,通过数据,按样本进行样本,通过窗口中的数据计算统计信息。每个输入样本的输出是当前样本的窗口上的统计信息Len.- 1以前的样本。在第一次步骤中,计算第一个Len.- 1输出窗口没有足够的数据时,算法用零填充窗口。在随后的时间步骤中,要填充窗口,该算法使用来自先前数据帧的样本。移动统计算法具有状态并记住以前的数据。
考虑使用滑动窗口方法计算用于计算流输入数据的移动平均值的示例。该算法使用窗口长度为4.具有输入的每个输入样本,长度4的窗口沿数据移动。
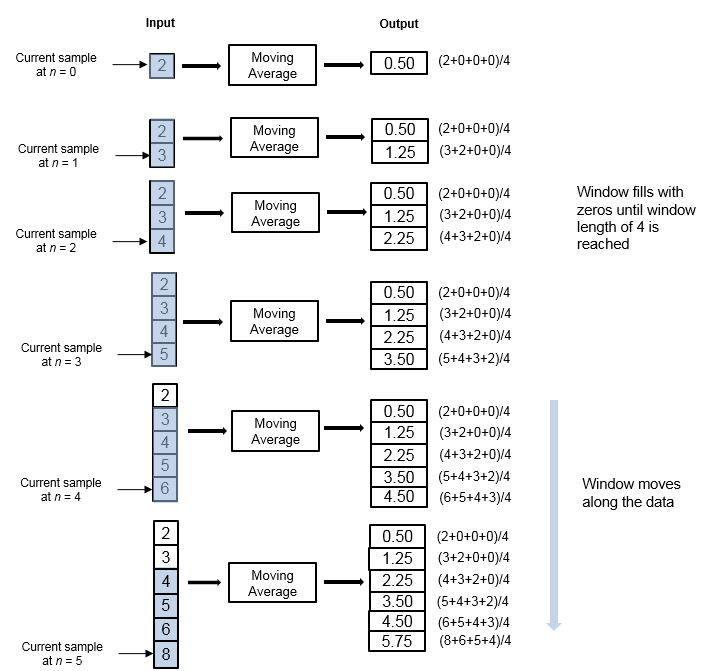
窗口具有有限长度,使算法成为有限脉冲响应滤波器。要在有限的数据持续时间内分析统计信息,请使用滑动窗口方法。
窗口长度的影响
窗口长度定义算法计算统计量的数据的长度。窗口随着新数据进入而移动。如果窗口很大,则统计计算的统计数据较近数据的静止统计信息。对于不会迅速更改的数据,使用长窗口获得更平滑的统计信息。对于快速更改的数据,请使用较小的窗口。
指数加权方法
指数加权方法具有无限脉冲响应。该算法计算一组权重,并递归将这些权重应用于数据样本。随着数据的年龄增加,加权因子的大小指数呈指数增长,并且从未达到零。换句话说,最近的数据对当前样本的统计数据比旧数据更多。由于无限脉冲响应,算法需要更少的系数,使其更适合嵌入式应用程序。
遗忘因子的值决定了加权因子的变化率。遗忘因数为0.9给较旧数据的重量比忘记因数为0.1。为了给近期数据提供更多重量,将遗忘因子移动到0.为了检测快速变化的数据中的小移位,较小的值(低于0.5)更合适。1.0忘记因子表示无限内存。所有先前的样品都有相等的重量。遗忘因子的最佳值取决于数据流。对于给定的数据流,计算忘记因子的最佳值,请参阅[1]。
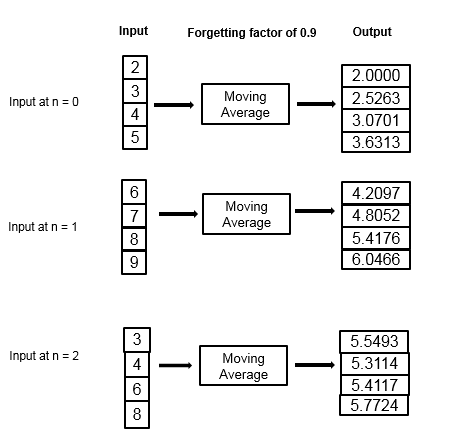
考虑使用指数加权方法计算计算移动平均线的示例。遗忘因子是0.9。
移动平均算法更新权重,并针对使用以下递归方程进入的每个数据样本来递归地计算移动平均值。
λ - 遗忘因子。
- 加权因子应用于当前数据样本。
- 电流数据输入样本。
- 在前一个样本中移动平均水平。
- 以前的数据对平均数据的影响。
- 当前样品的平均值。
| 数据 | 重量 | 平均数 |
|---|---|---|
| 框架1 | ||
| 2 | 1.N= 1,此值为1。 | 2 |
| 3. | 0.9×1 + 1 = 1.9 | (1-(1 / 1.9))×2 +(1 / 1.9)×3 = 2.5263 |
| 4. | 0.9×1.9 + 1 = 2.71 | (1-(1 / 2.71))×2.52 +(1 / 2.71)×4 = 3.0701 |
| 5. | 0.9×2.71 + 1 = 3.439 | (1-(1/3.439))×3.07 +(1 / 3.439)×5 = 3.6313 |
| 框架2 | ||
| 6. | 0.9×3.439 + 1 = 4.095 | (1-(1/4.095))×3.6313 +(1/4.095)×6 = 4.2097 |
| 7. | 0.9×4.095 + 1 = 4.6855 | (1-(1/4.6855))×4.2097 +(1/4.6855)×7 = 4.8052 |
| 8. | 0.9×4.6855 + 1 = 5.217 | (1-(1 / 5.217))×4.8052 +(1 / 5.217)×8 = 5.4176 |
| 9. | 0.9×5.217 + 1 = 5.6953 | (1-(1 / 5.6953))×5.4176 +(1 / 5.6953)×9 = 6.0466 |
| 框架3. | ||
| 3. | 0.9×5.6953 + 1 = 6.1258 | (1-(1/6.1258))×6.0466 +(1 / 6.1258)×3 = 5.5493 |
| 4. | 0.9×6.1258 + 1 = 6.5132 | (1-(1 / 6.5132))×5.5493 +(1 / 6.5132)×4 = 5.3114 |
| 6. | 0.9×6.5132 + 1 = 6.8619 | (1-(1 / 6.8619))×5.3114 +(1 / 6.8619)×6 = 5.4117 |
| 8. | 0.9×6.8619 + 1 = 7.1751 | (1-(1/7.1751))×5.4117 +(1/7.1751)×8 = 5.7724 |
移动平均算法具有状态并从前一步中记住数据。
对于第一个样本,何时N= 1,算法选择 = 1.对于下一个样本,更新加权因子并且使用递归方程计算平均值。
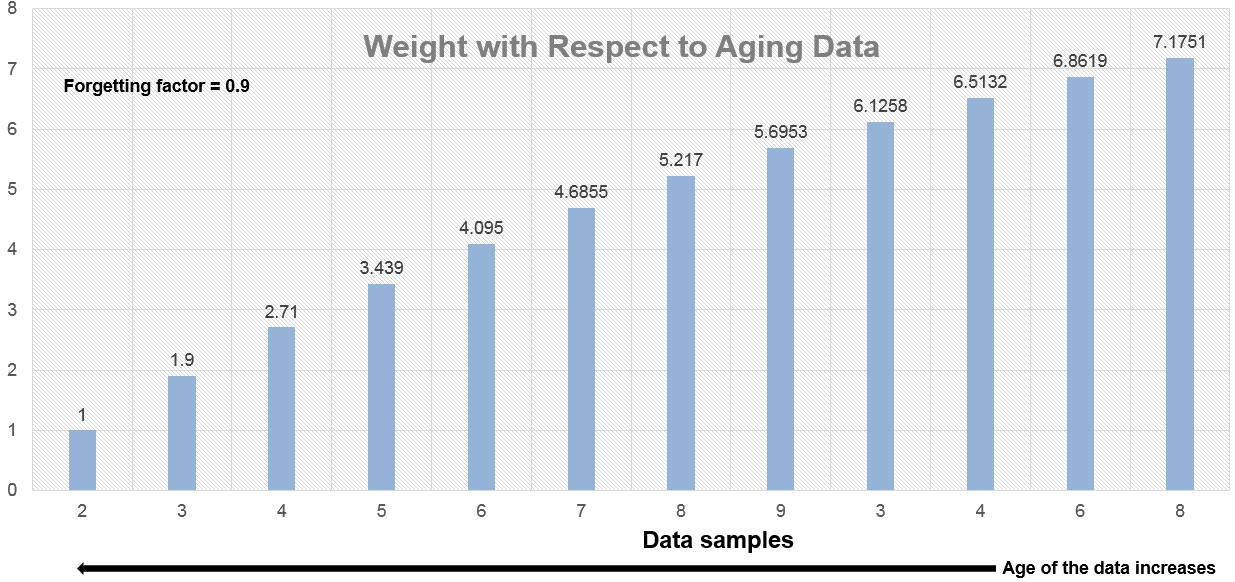
随着数据的年龄增加,加权因子的大小指数呈指数增长,并且从未达到零。换句话说,最近的数据对电流平均的数据具有更多的影响而不是旧数据。
当忘记因子为0.5时,施加到较旧数据的权重低于忘记因子为0.9时的权重。
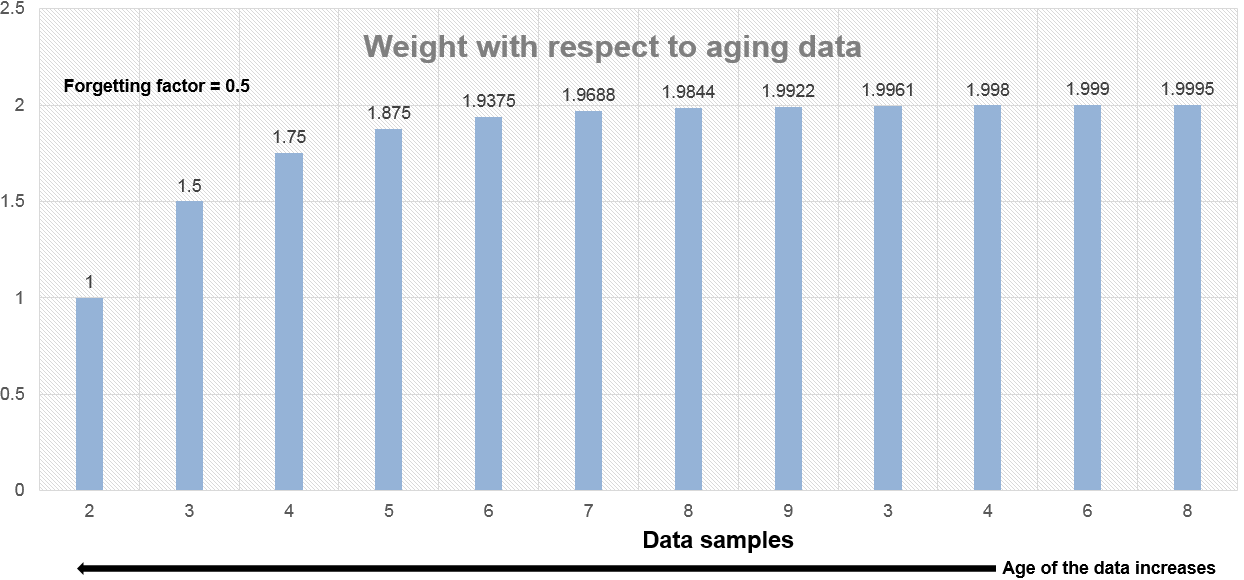
当忘记因子为1时,所有数据样本都同样称重。在这种情况下,指数加权方法与具有无限窗口长度的滑动窗法相同。
当信号快速变化时,使用较低的遗忘因子。当忘记因子低时,过去数据的效果对当前平均值较小。这使得瞬态更清晰。例如,考虑一种快速变化的嘈杂步长信号。

使用指数加权方法计算该信号的移动平均值。将算法的性能与遗忘因子0.8,0.9和0.99进行比较。
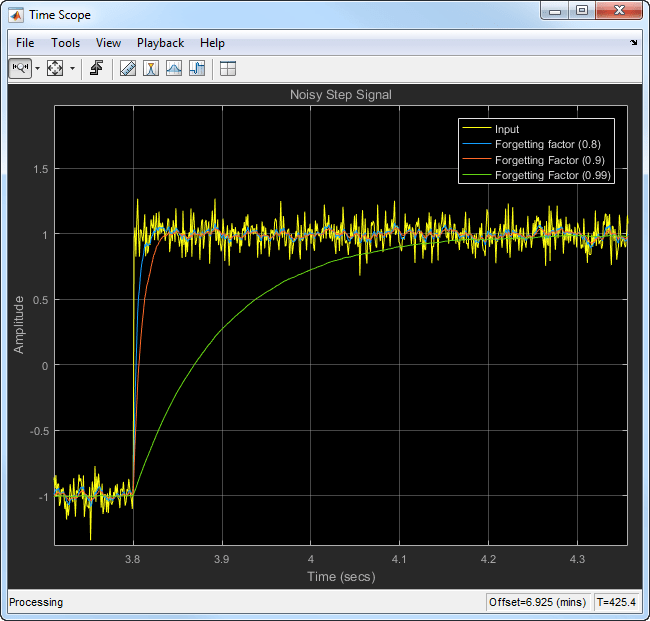
当您放大绘图时,当忘记因子低时,您可以看到移动平均线的瞬态是尖锐的。这使得它更适合于迅速变化的数据。
有关移动平均算法的更多信息,请参阅算法章节dsp.movingverage.System Object™或平均移动块页面。
有关其他移动统计算法的更多信息,请参阅算法各个系统对象和块页面中的部分。
参考
[1] Bodenham,Dean。“自适应滤波和变更检测流数据。”博士论文。帝国学院,伦敦,2012。
相关话题
您还可以从以下列表中选择一个网站: