过滤器
过滤推理经建会特工潜伏状态的动态回归数据
描述
例子
计算过滤状态概率
从两国经建会动态计算过滤状态概率回归模型的一维反应过程。这个示例使用任意参数的值的数据生成过程(文章)。
为文章创建完全指定的模型
创建一个两国并存的离散时间马尔可夫链模型的转换机制。
P = [0.9 - 0.1;0.2 - 0.8);mc = dtmc (P);
mc是一个完全指定的dtmc对象。
对于每个国家,创建一个基于“增大化现实”技术(0)(常数)模型的响应过程。将模型存储在一个向量。
mdl1 = arima (“不变”2,“方差”3);mdl2 = arima (“不变”2,“方差”1);mdl = [mdl1;mdl2];
mdl1和mdl2完全指定的华宇电脑对象。
创建一个经建会动态回归模型的转换机制mc和子的向量mdl。
Mdl = msVAR (mc, Mdl);
Mdl是一个完全指定的msVAR对象。
模拟数据的文章
过滤器需要响应计算过滤状态概率。生成一个随机响应和状态路径,从文章的长度30。
rng (1000);%的再现性(y, ~, sp) =模拟(Mdl 30);
计算状态概率
从经建会模型计算过滤和平滑状态概率模拟响应数据。
fs =过滤器(Mdl y);党卫军=光滑(Mdl y);
fs和党卫军是30-by-2过滤和平滑状态概率矩阵,分别为每个时期模拟地平线。虽然过滤状态概率t(fs (t:)通过时间)是基于响应数据t(y (1:t)),平滑状态概率t(党卫军(t):))是基于所有的观察。
画出模拟路径和过滤和平滑状态概率在同一图。
图绘制(sp,“米”)举行在情节(fs (:, 2),“r”)情节(ss (:, 2),‘g’)yticks([0 1 2])包含(“时间”)标题(“观察状态用估计状态概率”)({传奇“模拟状态”,“过滤概率:状态2”,…的平滑概率:状态2})举行从

计算过滤概率的衰退
考虑两国经建会动态回归模型的战后美国实际GDP增长率。模型中给出的参数估计[1]。
创建经建会动态回归模型
创建一个完全指定的离散时间马尔可夫链模型,描述了政权转换机制。标签的政权。
P = [0.92 - 0.08;0.26 - 0.74);mc = dtmc (P,“StateNames”,(“扩张”“衰退”]);
创建单独的、完全指定两个政权的AR(0)模型。
σ= 3.34;跨州%同方差的模型mdl1 = arima (“不变”,4.62,“方差”σ^ 2);mdl2 = arima (“不变”,-0.48,“方差”σ^ 2);mdl = [mdl1 mdl2];
创建经建会动态回归模型的转换机制mc针对各州具体情况和子mdl。
Mdl = msVAR (mc, Mdl);
Mdl是一个完全指定的msVAR对象。
加载和数据预处理
载入美国GDP数据集。
负载Data_GDP
数据包含我们的季度测量实际GDP在1947 q1 - 2005: Q2。兴趣的时期[1]1947:- 2004:沿。更详细的数据集,输入描述在命令行中。
转换数据的年率系列:
将数据转换为一个季度评估期内
按年计算季度利率
qrate = diff(数据(2:230)。/数据(2:229);季度率%arate = 100 * ((1 + qrate)。^ 4 - 1);%折合成年率
转换滴第一次观察到。
计算过滤状态概率
计算过滤状态概率的数据和模型。
FS =过滤器(Mdl arate);FS(最终,:)
ans =1×20.9396 - 0.0604
FS是由- 2 228 -过滤状态概率矩阵。行对应时期的数据arate,列对应的制度。
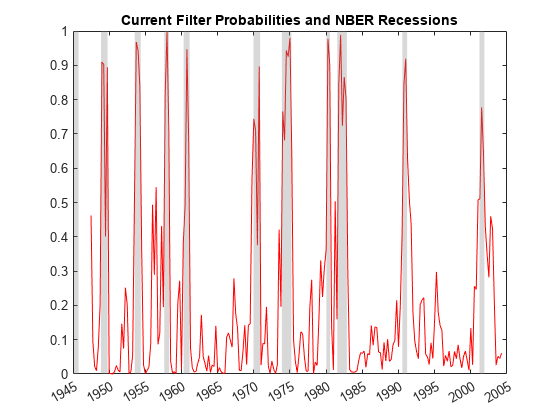
情节的过滤概率衰退,如[1],图6所示。
图;情节(日期(3:230),FS (:, 2),“r”)datetick (“x”)标题(“当前过滤概率和NBER衰退”)recessionplot
计算平滑状态概率
计算平滑状态概率,然后画出平滑概率的衰退[1],图6所示。
党卫军=平滑(Mdl arate);图绘制(日期(3:230),学生(:,2),“r”)datetick (“x”)recessionplot标题(“充分样本平滑概率和NBER衰退”)

计算过滤与VARX的子状态的概率模型
计算过滤状态概率从一个三态经建会动态回归模型为二维VARX响应过程。这个示例使用任意文章的参数值。
为文章创建完全指定的模型
创建一个三态离散时间马尔可夫链模型切换机制。
P = [5 1 1;1 5 1;1 1 5];mc = dtmc (P);
mc是一个完全指定的dtmc对象。dtmc规范化的行P所以他们总和1。
对于每个国家,创建一个完全指定VARX(0)模型(仅常数和回归系数矩阵)的响应过程。指定不同的常数向量模型。指定相同的两个解释变量的回归系数,并指定相同的协方差矩阵。VARX模型存储在一个向量。
%的常量C1 = (1, 1);C2 = [3; 3);C3 = (5; 5);%回归系数β= (0.2 - 0.1;-0.3 0);%的协方差矩阵σ= [1.8 - -0.4;-0.4 - 1.8);% VARX子mdl1 = varm (“不变”C1,“β”,β,…协方差的σ);mdl2 = varm (“不变”C2,“β”,β,…协方差的σ);mdl3 = varm (“不变”C3,“β”,β,…协方差的σ);mdl = [mdl1;mdl2;mdl3];
mdl包含三个完全指定的varm模型对象。
的文章,创建一个完全指定经建会动态回归模型的切换机制mc和子mdl。
Mdl = msVAR (mc, Mdl);
Mdl是一个完全指定的msVAR模型。
模拟数据的文章
模拟数据的两个外生系列通过生成30观测标准二维高斯分布。
rng (1)%的再现性2 X = randn(30日);
生成一个随机响应和状态路径,从文章的长度30。指定子模型回归模拟外生数据组件。
(Y, ~, SP) =模拟(Mdl 30“X”,X);
Y是一个30-by-2矩阵的模拟反应路径。SP是一个30-by-1向量的一个模拟状态的路径。
计算状态概率
计算过滤和平滑的状态概率从文章给出模拟响应数据。
FS =过滤器(Mdl Y“X”,X);党卫军=平滑(Mdl Y“X”,X);
FS和党卫军是30-by-2过滤和平滑状态概率矩阵,分别为每个时期模拟地平线。
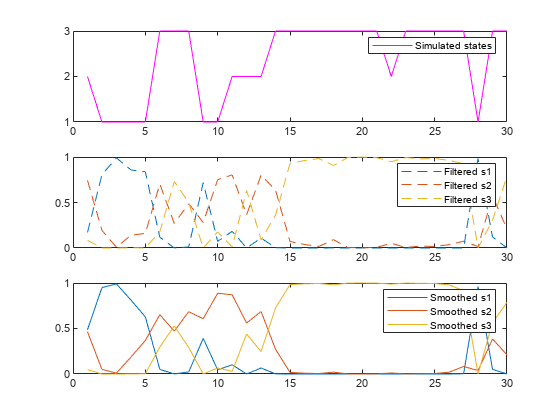
画出模拟路径和过滤和平滑状态概率的次要情节相同的图。
图次要情节(3、1、1)的阴谋(SP,“米”)yticks((1 2 3))({传奇“模拟状态”})次要情节(3、1、2)情节(FS,“——”)({传奇“过滤s1 ','过滤s2 ',“过滤s3”})次要情节(3,1,3)情节(党卫军,“- - -”)({传奇“平滑s1 ','平滑s2 ',“平滑s3”})
指定Presample数据
考虑到数据计算过滤概率的衰退感兴趣的,但假设时期是1960:q1 - 2004: Q2。同时,可以考虑添加一个自回归项每个子模型。
创建部分指定模型估计
创建一个部分指定经建会动态回归模型的估计。指定AR(1)的子。
P =南(2);mc = dtmc (P,“StateNames”,(“扩张”“衰退”]);mdl = arima (1,0,0);Mdl = msVAR (mc, [Mdl;mdl));
因为子AR(1),每个需要一个presample观察初始化其估计的动态组件。
创建完全指定模型包含初始值
创建包含初始参数值的模型估计过程。
mc0 = dtmc (0.5 * 1 (2),“StateNames”,(“扩张”“衰退”]);submdl01 = arima (“不变”,1“方差”,1基于“增大化现实”技术的,0.001);submdl02 = arima (“不变”,1“方差”,1基于“增大化现实”技术的,0.001);Mdl0 = msVAR (mc0 [submdl01;submdl02]);
加载和数据预处理
加载数据。把整个设置为一个折合成年率系列。
负载Data_GDPqrate = diff(数据)。/数据(1:结束(- 1));arate = 100 * ((1 + qrate)。^ 4 - 1);
识别presample并估计样本时期使用的日期与折合成年率系列。因为转换适用于第一个区别,必须从原样品第一次观察到的日期。
日期= datetime(日期(2:结束),“ConvertFrom”,“datenum”,…“格式”,“yyyy QQQ”,“场所”,“en_US”);estPrd = datetime ([“1960:第二季”“2004:第二季”),“InputFormat”,“yyyy QQQ”,…“格式”,“yyyy QQQ”,“场所”,“en_US”);idx = isbetween(日期、estPrd (1) estPrd (2));idxPre =日期< (estPrd (1);
估计模型
适合的模型估计样本数据。指定presample观察。
arate0 = arate (idxPre);arateEst = arate (idx);EstMdl =估计(Mdl Mdl0 arateEst,“Y0”,arate0);
EstMdl是一个完全指定的msVAR对象。
计算状态概率
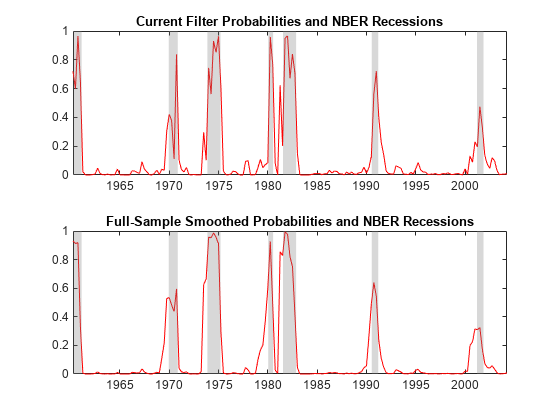
计算过滤和平滑状态概率估计模型和数据的估计。指定presample观察。情节衰退的概率估计的次要情节相同的图。
FS =过滤器(EstMdl arateEst,“Y0”,arate0);党卫军=平滑(EstMdl arateEst,“Y0”,arate0);图;次要情节(2,1,1)情节(日期(idx), FS (:, 2),“r”)标题(“当前过滤概率和NBER衰退”)recessionplot次要情节(2,1,2)情节(日期(idx),学生(:,2),“r”)标题(“充分样本平滑概率和NBER衰退”)recessionplot
Loglikelihood返回的数据
考虑的模型和数据计算过滤概率的衰退。
创建指定的完全经建会模型。
P = [0.92 - 0.08;0.26 - 0.74);mc = dtmc (P,“StateNames”,(“扩张”“衰退”]);σ= 3.34;mdl1 = arima (“不变”,4.62,“方差”σ^ 2);mdl2 = arima (“不变”,-0.48,“方差”σ^ 2);mdl = [mdl1;mdl2];Mdl = msVAR (mc, Mdl);
加载和数据进行预处理。
负载Data_GDPqrate = diff(数据(2:230)。/数据(2:229);arate = 100 * ((1 + qrate)。^ 4 - 1);
计算过滤状态概率和loglikelihood数据和模型。
[FS, logL] =过滤器(Mdl arate);logL
logL = -640.3016
输入参数
输出参数
引用
[2]汉密尔顿,j . D。“经济分析的一种新方法的非平稳时间序列和商业周期”。费雪。57卷,1989年,页357 - 384。
[3]汉密尔顿,j . D。“分析的时间序列的变化机制。”计量经济学杂志。45卷,1990年,页39 - 70。
[4]汉密尔顿,詹姆斯D。时间序列分析。普林斯顿,纽约:普林斯顿大学出版社,1994年。
