债券投资组合优化
这个例子展示了如何构建一个10年期、20年期和30年期国债的最优投资组合,这些国债将持有一个月。重点放在整体资产配置过程。
步骤1:加载市场数据-加载从FRED下载的历史日国债收益率。
步骤2:计算市场不变量-每日到期收益率的变化被选择为不变量,并假定为多元正态。由于30年期债券的数据缺失,采用期望最大化算法估计不变量的均值和协方差。不变式的统计数据被投射到投资的地平线上。
步骤3:模拟地平线上的不变量-由于收益率曲线的高相关性和固有结构,主成分分析应用于不变量统计。在主成分分析空间中进行多元正态随机抽取。仿真被转换回不变空间使用主成分分析负载。
第四步:计算地平线上的收益分布-模拟的收益率曲线的月变化被用来计算投资组合证券在地平线上的收益率。这需要从模拟的收益率曲线中插入值,因为组合证券的到期日将比10年、20年和30年短一个月。每个场景/证券的利润/损失是通过使用模拟的和内插的收益率对国债定价来计算的。模拟线性收益及其统计数据是根据价格计算出来的。
第五步:优化资产配置-对国债收益统计数据进行二次均值/方差优化,以计算沿有效边界10个点的最优投资组合权重。投资者的偏好是选择最接近可能夏普比率平均值的投资组合。
步骤1:加载市场数据
DGS6MO, DGS1, DGS2, DGS3, DGS5, DGS7, DGS10, DGS20, DGS30系列的历史到期产量数据日期:2000年9月1日- 2010年9月1日http://research.stlouisfed.org/fred2/categories/115注意:使用Datafeed Toolbox™下载数据,使用如下命令:>>康涅狄格州=弗雷德;>>数据=fetch(康涅狄格州,‘DGS10’,‘9/1/2000’,‘9/1/2010’);为了方便起见,结果被聚合并存储在二进制MAT文件中
disp (“第一步:加载并可视化市场数据……”);
步骤1:加载和可视化市场数据…
histData =负载(“HistoricalYTMData.mat”);每个系列的到期时间tsYTMMats = histData.tsYTMMats;%观察日期率tsYTMObsDates = histData.tsYTMObsDates;%观察利率tsYTMRates = histData.tsYTMRates;可视化产量曲线如矿坑的= min (tsYTMRates (:));maxy = max (tsYTMRates (:));图;h =情节(tsYTMMats tsYTMRates,' k o ');轴([0,32岁,如矿坑的,maxy]);包含(“到期时间”);ylabel (“收益”);传奇(“历史收益率曲线”,“位置”,“本身”);网格在;为i = 1:50:length(tsYTMObsDates) set(h,“ydata”tsYTMRates(我:));标题(datestr (tsYTMObsDates (i)));暂停(0.1);结束
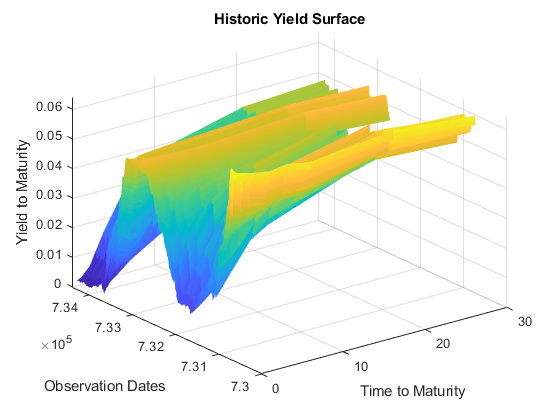
步骤2:计算市场不变量
对于市场不变量,使用标准:每个系列的日到期收益率变化。你可以估计它们的统计分布是多变量正态分布。IID对每个不变序列的分析都产生了不错的结果——在“独立”因素方面比“相同”因素更有效果。使用更复杂的分布和/或时间序列模型进行更彻底的建模超出了这个项目的范围。需要考虑的是在缺失数据存在的情况下对分布参数的估计。30年期国债在2002年2月至2006年2月期间停止发行,因此在这段时间内没有收益。
disp (“第二步:计算市场不变量……”);
步骤2:计算市场不变量…
%不变量被假定为YTM利率的每日变化tsYTMRateDeltas = diff (tsYTMRates);%大约三分之一的30年期利率(第9栏)从原始数据中丢失了%的数据集。而不是抛出所有这些观察,一个期望% Maximization例程用于估计均值和协方差%不变量。使用默认选项(NaN跳过初始估计等)。[tsInvMu, tsInvCov] = ecmnmle (tsYTMRateDeltas);计算标准偏差和相关性[tsInvStd, tsInvCorr] = cov2corr (tsInvCov);投资期限为1个月。(2010年9月1日起计21个营业日%和10/1/2010)。因为不变量是可和的,而均值和正态分布的方差是正态的,我们可以预测%不变的投资期限如下hrznInvMu = 21 * tsInvMu ';hrznInvCov = 21 * tsInvCov;[hrznInvStd, hrznInvCor] = cov2corr (hrznInvCov);%显示结果disp (“预测地平线的市场不变量有以下统计数据”);
投射到地平线上的市场不变量有以下统计数据
disp (”的意思是:“);
意思是:
disp (hrznInvMu);
1.0e-03 * -0.5149 -0.4981 -0.4696 -0.4418 -0.3788 -0.3268 -0.2604 -0.2184 -0.1603
disp (的标准差:);
标准偏差:
disp (hrznInvStd);
0.0023 0.0024 0.0030 0.0032 0.0033 0.0032 0.0030 0.0027 0.0026
disp (的关系:);
相关:
disp (hrznInvCor);
1.0000 0.8553 0.5952 0.5629 0.4980 0.4467 0.4028 0.3338 0.3088 0.8553 1.0000 0.8282 0.7901 0.7246 0.6685 0.6175 0.5349 0.4973 0.5952 0.8282 1.0000 0.9653 0.9114 0.8589 0.8055 0.7102 0.6642 0.5629 0.7901 0.9653 1.0000 0.9106 0.8664 0.7789 0.7361 0.4980 0.7246 0.9114 0.9519 1.0000 0.9725 0.9438 0.8728 0.8322 0.4467 0.6685 0.8589 0.9106 0.97251.0000 0.9730 0.9218 0.8863 0.4028 0.6175 0.8055 0.8664 0.9438 0.9730 1.0000 0.9562 0.9267 0.3338 0.5349 0.7102 0.7789 0.8728 0.9218 0.9562 1.0000 0.9758 0.3088 0.4973 0.6642 0.7361 0.8322 0.8863 0.9267 0.9758 1.0000
步骤3:在地平线上模拟市场不变量
高相关性对于模拟视界上不变量的分布(最终是证券价格)并不理想。利用主成分分解提取正交不变量。这也可以用于降维,然而,由于不变量的数量仍然相对较少,保留所有9个分量以更准确地重建。然而,市场数据中的缺失值使你无法直接从时间序列数据中进行估计。相反,这可以直接用协方差矩阵来做
disp (“第三步:在Horizon模拟市场不变量……”);
步骤3:在Horizon模拟市场不变量…
%使用不变量协方差进行PCA分解[pcaFactorCoeff, pcaFactorVar pcaFactorExp] = pcacov (hrznInvCov);%保留主成分分解的所有成分numFactors = 9;%建立PCA因子协方差矩阵pcaFactorCov = corr2cov(√pcaFactorVar)、眼睛(numFactors));%模拟次数(随机抽取)numSim = 10000;%固定随机种子,以获得可重复的结果流= RandStream (“mrg32k3a”);RandStream.setGlobalStream(流);从多变量正态分布中随机抽取,均值为零%和对角协方差(numFactors pcaFactorSims = mvnrnd (0, 1), pcaFactorCov, numSim);%转换为视界不变量并计算统计量hrznInvSims = pcaFactorSims*pcaFactorCoeff' + rerepmat (hrznInvMu,numSim,1); / /设置为1hrznInvSimsMu =意味着(hrznInvSims);hrznInvSimsCov = x (hrznInvSims);[hrznInvSimsStd, hrznInvSimsCor] = cov2corr (hrznInvSimsCov);%显示结果disp ("模拟不变量与原始不变量有非常相似的统计量");
模拟不变量与原始不变量具有非常相似的统计量
disp (”的意思是:“);
意思是:
disp (hrznInvSimsMu);
1.0e-03 * 0.4983 -0.5002 -0.4832 -0.4542 -0.4031 -0.3597 -0.2867 -0.2515 -0.1875
disp (的标准差:);
标准偏差:
disp (hrznInvSimsStd);
0.0023 0.0023 0.0030 0.0031 0.0032 0.0031 0.0029 0.0027 0.0026
disp (的关系:);
相关:
disp (hrznInvSimsCor);
1.0000 0.8527 0.5827 0.5502 0.4846 0.4327 0.3896 0.3197 0.2961 0.8527 1.0000 0.8227 0.7840 0.7181 0.6603 0.6097 0.5246 0.4896 0.5827 0.8227 1.0000 0.9646 0.9100 0.8569 0.8048 0.7074 0.6633 0.5502 0.7840 0.9646 1.0000 0.9507 0.9085 0.8656 0.7757 0.7344 0.4846 0.7181 0.9100 0.9507 1.0000 0.9721 0.9428 0.8710 0.8319 0.4327 0.6603 0.8569 0.9085 0.97211.0000 0.9726 0.9211 0.8870 0.3896 0.6097 0.8048 0.8656 0.9428 0.9726 1.0000 0.9552 0.9264 0.3197 0.5246 0.7074 0.7757 0.8710 0.9211 0.9552 1.0000 0.9753 0.2961 0.4896 0.6633 0.7344 0.8319 0.8870 0.9264 0.9753 1.0000
第四步:计算安全回报在地平线上的分布
投资组合包括10年期、20年期和30年期国债。为简单起见,假设这些是结算日的新发行债券,并根据当前收益率曲线的市场价值定价。利润和损失的分配是通过在地平线上根据每个模拟收益率对每个证券定价并减去购买价格来计算的。地平线价格要求非标准到期收益率。这些是用三次样条插值计算的。模拟的线性回报是它们的统计数据,是从盈利和亏损场景中计算出来的。
disp (“第四步:计算安全回报在地平线上的分布……”);
第四步:计算安全回报分布在地平线…
%购买和投资期限settleDate =“9/1/2010”;hrznDate =“10/1/2010”;在结算日购买的新发行国库券的到期日treasuryMaturities = {“9/1/2020”,“9/1/2030”,“9/1/2040”};%结算日利息证券的观察收益treasuryYTMAtSettle = tsYTMRates(结束,七章);%初始化数组,供以后使用treasuryYTMAtHorizonSim = 0 (numSim, 3);treasuryPricesAtSettle = 0(1、3);treasuryPricesAtHorizonSim = 0 (numSim, 3);%使用实际/实际日计数的基础与年化收益率基础= 8;使用已知的到期收益率在结算日对国库券进行价格注意:为了简单起见,我们假设这些证券都不存在%包括息票支付。希望是,尽管价格可能不是%精确的整体结构/值之间的关系为资产配置过程保留的%。为j=1:3 treasuryPricesAtSettle(j) = bndprice(treasurytmatsettle (j),0, settingdate,...treasuryMaturities (j),“基础”、基础);结束要在地平线上为国债定价,我们需要知道到期收益率%分别为9岁11个月、19岁11个月和29岁11个月%的模拟。我们用三次样条插值来近似这些将模拟不变量变换为YTM在水平处hrznYTMRatesSims = repmat(tsYTMRates(end,:),numSim,1) + hrznInvSims;hrznYTMMaturities = {“4/1/2011”,“10/1/2011”,“10/1/2012”,“10/1/2013”,...“10/1/2015”,“10/1/2017”,“10/1/2020”,“10/1/2030”,...“10/1/2040”};将日期转换为数字序列日期x = datenum (hrznYTMMaturities);ξ= datenum (treasuryMaturities);%为了数字精度,将x值从0开始移位minDate = min (x);x = x - minDate;xi = xi - minDate;%每一个模拟和到期的接近10年,20年,30年的收益率%的节点。注意,样条拟合与线性拟合的效果有%对结果的理想分配有显著影响。这是由于%到使用线性拟合时产量的显著低估%表示距离已知节点不远的点为i=1:numSim treasuryYTMAtHorizonSim(i,:) = interp1(x,hrznYTMRatesSims(i,:),xi,样条的);结束%可视化1模拟产量曲线与插值图;情节(x, hrznYTMRatesSims (1:)' k o '习,treasuryYTMAtHorizonSim (1:)“罗”);包含(的时间(天));ylabel (“收益”);传奇({“模拟收益率曲线”,“窜改收益率”},“位置”,“本身”);网格在;标题(“放大看样条与线性插值”);

每一个模拟的到期收益率在地平线上的国债价格与上面所说的bndprice相同的假设基础= 8 * 1 (numSim 1);为j=1:3 treasuryPricesAtHorizonSim(:,j) = bndprice(treasurytmathorizonsim (:,j)),0,...hrznDate treasuryMaturities (j),“基础”、基础);结束计算线性回报的分布return = (treasuryPricesAtHorizonSim - repmat(treasuryPricesAtSettle,numSim,1))./repmat(treasuryPricesAtSettle,numSim,1);计算收益统计retsMean =意味着(treasuryReturns);retsCov = x (treasuryReturns);[retsStd, retsCor] = cov2corr (retsCov);可视化30年期国库的结果图;嘘(treasuryReturns, 100);标题(《10年、20年、30年国债收益率分布》);网格在;传奇({“十年”,“20年”,“30年”});
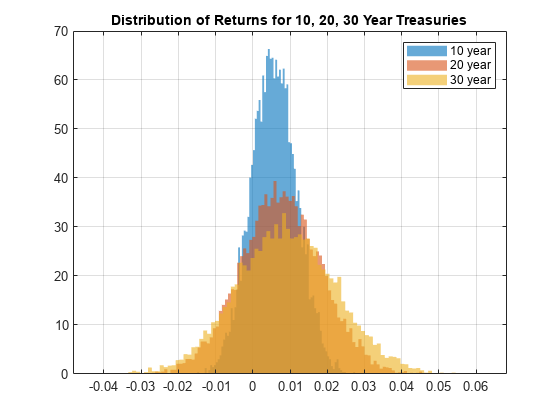
第五步:优化资产配置
采用二次规划方法优化资产配置。计算了10个最优投资组合,并计算了它们的夏普比率。基于投资者偏好的最优投资组合选择最接近夏普比率均值的投资组合
disp (“第五步:优化资产配置……”);
第五步:优化资产配置……
沿着有效边界的投影计算10个点% std /回报空间。[portStd, portRet portWts] = portopt (retsMean retsCov 10);%可视化图;次要情节(2,1,1)情节(portStd portRet,' k o ');包含(“组合性病”);ylabel (“投资回报”);标题(“有效边界投影”);传奇(“最佳组合”,“位置”,“本身”);网格在;次要情节(2,1,2)栏(portWts,“堆叠”);包含(组合数的);ylabel (的组合权重);标题(“投资于每个国库的百分比”);传奇({“十年”,“20年”,“30年”});
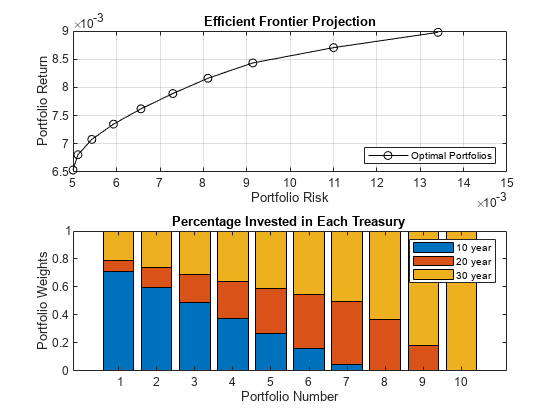
%夏普比率是用0无风险利率计算的,因为我们在投资%的美国国债夏普= portRet. / portStd;%投资者根据接近均值的夏普比率选择投资组合sharpeTarget =意味着(夏普);investorChoice = find(min(abs(sharpetarget)) == abs(sharpetarget));investorPortfolioWts = portWts (investorChoice:);disp (10年期、20年期和30年期国债的投资者比例配置);
投资者在10年、20年、30年国债中的比例配置
disp (investorPortfolioWts);
0.3989 0.3196 0.2815
另请参阅
tbilldisc2yield|tbillprice|tbillrepo|tbillval01|tbillyield|tbillyield2disc
相关的例子
更多关于
你也可以从以下列表中选择一个网站:
