paretosearch算法
paretosearch算法概述
该paretosearch算法使用一组点的模式搜索以搜索为反复非劣点。看到多目标术语。模式搜索满足在每次迭代的所有边界和线性约束。
从理论上讲,该算法收敛到接近真实的Pareto前沿分。对于讨论和收敛的证明,见库斯托迪奥等。[1],其证明适用于具有Lipschitz连续目标和约束的问题。
定义paretosearch算法
paretosearch使用许多中间量和公差在其算法的。
| 数量 | 定义 |
|---|---|
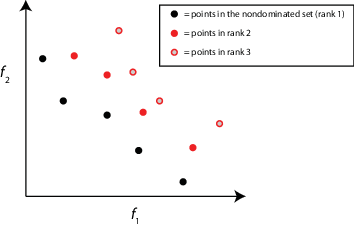
| 秩 | 一个点的排名有一个反复的定义。
|
| 体积 | 点集的超容量p在满足不等式,对于每个索引的目标函数空间Ĵ, F一世(Ĵ)<p一世< M一世, 在哪里F一世(Ĵ) 是个一世的个分量Ĵ在帕累托集合个目标函数值,以及M一世由上开往一世个分量在帕累托集中的所有点。在此图中,M就是所谓的参考点。的灰色的体积的图分别表示的部分的色调,一些计算算法作为容斥计算的一部分使用。
有关详细信息,请参阅弗莱舍[3]。
体积变化是导致算法停止的一个因素。有关详细信息,请参见停止条件。 |
| 距离 | 距离是个体到其最近的邻居亲近的量度。该 该算法将个体在极端位置的距离设置为
该算法分别排序每个维度,所以术语邻居意味着在每个维度的邻居。 具有较高的距离同级别的个人有选择的机会较高(较高的距离为好)。 距离在传播的计算,这是一个停止准则的一部分的一个因素。有关详细信息,请参见停止条件。 |
| 传播 | 价差是帕累托集合移动的一种度量
当极端目标函数值在迭代之间变化不大时(即,μ当帕累托前面的点分布均匀时(即,σ是小)。
|
ParetoSetChangeTolerance |
停止搜索条件。paretosearch停止时的音量,传播,或距离并不比越改ParetoSetChangeTolerance在一个窗口的迭代。有关详细信息,请参见停止条件。 |
MinPollFraction |
在迭代中轮询的位置的最小比例。 此选项不适用时, |

素描paretosearch算法
初始化搜索
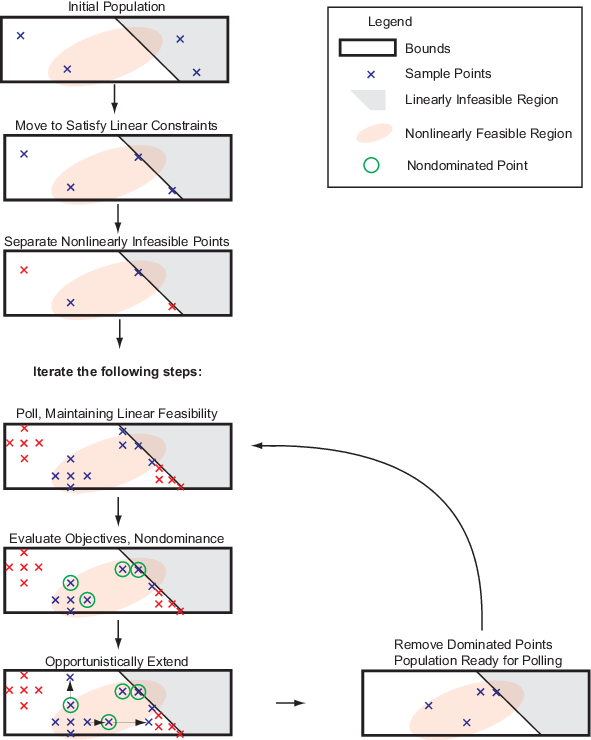
为了创建初始点集,paretosearch生成options.ParetoSetSize从准随机采样点基于问题的边界,在默认情况下。有关详细信息,请参阅Bratley和福克斯[2]。当问题有超过500的尺寸,paretosearch使用拉丁方抽样以生成所述初始点。
如果一个组件没有边界,paretosearch使用一个人工下限的-10和一个人为的上界10。
如果一个组件只有一个约束,paretosearch使用该绑定为宽度的间隔的端点20个+ 2 * ABS(结合的)。例如,如果不存在上界的成分并有一个下限的15paretosearch使用20 + 2 * 15 = 55的间隔宽度,所以使用上界的15 + 55 = 70的人工。
如果您传递一些初始点options.InitialPoints, 然后paretosearch使用这些点作为初始点。paretosearch产生更多的点,如果必要的话,以获得至少options.ParetoSetSize初始点。
paretosearch然后检查初始点,以确保它们是可行的相对于所述边界和线性约束。如果有必要,paretosearch通过求解线性规划问题突出的初始点到的线性可行点线性子空间。这个过程可能会导致一些点重合,在这种情况paretosearch删除任何重复的点。paretosearch不改变初始点人工边界,只对指定的范围和线性约束。
移动点,如果需要满足线性约束,之后,paretosearch检查各点是否满足非线性约束。paretosearch给出惩罚值为天道酬勤对不满足所有非线性约束的任何一点。然后paretosearch计算剩余的可行点的任何遗漏的目标函数值。
注意
目前,paretosearch不支持非线性等式约万博1manbetx束CEQ(X)= 0。
创建存档和在职者
paretosearch维持两组要点:
档案- 包含具有筛目尺寸低于相关联的非支配点A结构options.MeshTolerance并满足所有约束中options.ConstraintTolerance。该档案结构包含不超过2 * options.ParetoSetSize分最初是空的。在每个点档案包含一个相关联的网目尺寸,这是在其中生成该点的网目尺寸。迭代- 包含非支配点并且可能与较大的筛目尺寸或不可行性相关联的一些主导点结构。在每个点迭代包含一个相关联的网目尺寸。迭代包含不超过options.ParetoSetSize点。
民意调查,以找到更好的点
paretosearch调查分迭代,轮询点从点继承关联的网格大小迭代。该paretosearch算法使用的轮询保持可行性的边界和所有线性约束。
如果问题具有非线性的限制,paretosearch计算各调查点的可行性。paretosearch将不可行点的得分与可行点的得分分开。可行点得分为该点目标函数值的向量。一个不可行点的得分为非线性不可行点的和。
paretosearch民调至少MinPollFraction*(数在图案点的)位置中的每个点迭代。如果投票点相对于现任(原始)点至少给出一个非主导的点,那么投票就被认为是成功的。否则,paretosearch继续轮询直至找到一个非支配点或运行在图案点出来。如果paretosearch跑出点,不产生一个非主导的点,paretosearch宣布投票不成功和半网格大小。
如果民意调查显示,非支配点,paretosearch在成功的方向上重复扩展轮询,每一次都将网格大小加倍,直到扩展产生一个主导点。在此扩展期间,如果网格尺寸超过options.MaxMeshSize(默认值:天道酬勤),投票停止。若目标函数值降为-Inf,paretosearch声明问题是无界的,然后停止。
更新档案和迭代结构
轮询毕竟在点迭代时,该算法将新点与算法中的点一起检验迭代和档案结构。paretosearch计算秩,或Pareto最优前沿数目,每个点中,然后将执行以下操作。
标记为删除所有点没有等级1
档案。马克的新排名
1点插入迭代。标志着可行点
迭代其相关联的网孔尺寸小于options.MeshTolerance转移到档案。标志着支配点
迭代只有当他们阻止新的非主导点被添加时才可以移除迭代。
paretosearch然后计算每个点的体积和距离度量。如果档案将溢出的标记点的结果被收录,然后用最大的音量点占据档案,其他人就走了。类似地,新点标记为添加迭代输入迭代按卷的顺序排列。
如果迭代是满了还是没有优势点呢paretosearch不会增加分迭代并声明迭代是不成功的。paretosearch相乘的网目尺寸在迭代1/2。
停止条件
对于三个或更少的目标函数,paretosearch使用量和蔓延的措施停止。对于四个或四个以上的目标,paretosearch使用距离和扩散作为停止措施。在接下来的讨论中,有两种方法paretosearch用途表示的适用的措施。
该算法保持适用措施的最后八个值的向量。经过八年的迭代中,算法检查两个适用措施的值在每次迭代,其中的开始TOL = options.ParetoSetChangeTolerance:
spreadConverged = ABS(扩散(结束 - 1) - 扩展(结束))<= TOL *最大(1,扩散(结束 - 1));= abs(卷(端- 1)-卷(端))<= tol*max(1,卷(端- 1));distanceConverged = ABS(距离(末端 - 1) - 距离(结束))<= TOL *最大(1,距离(末端 - 1));
如果任何适用的测试真正的,算法停止。否则,该算法计算适用的措施,减去第一项的傅立叶变换的平方项的最大值。然后,该算法极大值进行比较,以它们的删除条款(变换的DC分量)。如果任任期删除大于100 * TOL *(最大所有其他条款的),然后算法停止。这个测试本质上决定了措施的顺序没有波动,因此是收敛的。
此外,绘图功能或输出功能可以停止算法,或算法可以停止,因为它超过了时间限制或功能评价限制。
返回值
该算法返回Pareto前端上的点,如下所示。
paretosearch结合点档案和迭代为一组。当有三个或更少的目标函数时,
paretosearch将点从最大的卷返回到最小的卷,直到最大ParetoSetSize点。当有四个或四个以上的目标函数,
paretosearch从到最小的最大距离返回点,出至多ParetoSetSize点。
改进并行计算和向量化函数求值
什么时候paretosearch并行地或以矢量的方式来计算目标函数的值(UseParallel是真正的或UseVectorized是真正的),也有一些变化的算法。
什么时候
UseVectorized是真正的,paretosearch忽略MinPollFraction选项,并评估了该模式的所有投票点。当在并行计算,
paretosearch依次检查中的每个点迭代并执行从每个点处的并行轮询。回国后MinPollFraction在民意调查中,paretosearch确定是否有任何轮询分支配基点。如果是这样,投票被认为是成功的,和任何其他并行的评价暂停。如果没有,继续投票直至支配点出现或投票完成。paretosearch或者执行对工人或在矢量化的方式,而不是两者的目标函数的评估。如果同时设置UseParallel和UseVectorized至真正的,paretosearch在工人上并行计算目标函数值,但不以向量化的方式。在这种情况下,paretosearch忽略MinPollFraction选项,并评估了该模式的所有投票点。
跑paretosearch很快
跑得最快的方式paretosearch取决于几个因素。
如果目标函数的评价是缓慢的,那么它通常最快方法是使用并行计算。在并行计算的开销可能是巨大的,当目标函数的评价是快,但是当他们是缓慢的,通常最好使用更多的计算能力。
注意
并行计算需要并行计算工具箱™许可证。
如果目标函数的评价都不是很耗时的,那么它通常最快方法是使用量化评估。然而,这并非总是如此,因为量化计算评估的整个图案,而串行评估可以采取一个模式的只是一小部分。在高维尤其是,在降低的评估可能会导致串行评价是对一些问题的速度更快。
要使用向量化计算,目标函数必须接受一个具有任意行数的矩阵。每一行表示一个要求值的点。目标函数必须返回目标函数值的矩阵,其行数与它接受的行数相同,每个目标函数有一列。对于单一目标的讨论,请参见向量化适应度函数(
GA) 要么量化目标函数(patternsearch)。
参考
[1]库斯托迪奥,A. L.,J. F. A.马德拉,A. I. F.瓦斯和L. N.森特。直接Multisearch多目标优化。SIAM J.的Optim。,21(3),2011,第一一〇九年至1140年。预印本可在https://estudogeral.sib.uc.pt/bitstream/10316/13698/1/Direct%20multisearch%20for%20multiobjective%20optimization.pdf。
[2] Bratley,P.,和B. L.福克斯。算法659:实现Sobol的准随机序列生成器。ACM反式。数学。软件14,1988,第88-100页。
[3]弗莱舍,M.帕累托最优测度:应用于多目标元启发式。在法罗,葡萄牙2003年4月“进化多优化标准,EMO的第二次国际会议论文集”。在计算机科学系列,卷讲义出版施普林格出版社。2632,第519-533。预印本可在http://www.dtic.mil/get-tr-doc/pdf?AD=ADA441037。
也可以看看
相关的话题
您也可以从以下列表中选择网站: