基于PointNet++深度学习的航空激光雷达语义分割
此示例演示如何训练PointNet++深度学习网络对航空激光雷达数据执行语义分割。
从机载激光扫描系统获取的激光雷达数据用于地形测绘、城市建模、生物量测量和灾害管理等应用。从这些数据中提取有意义的信息需要语义分割,这是一个为点云中的每个点分配唯一类别标签的过程。
在本例中,通过使用Dayton注释的激光雷达地球扫描(DALES)数据集,训练PointNet++网络执行语义分割[1.]。数据集包含密集的场景,标记航空激光雷达数据来自城市,郊区,农村和商业设置。该数据集提供了8类的语义分割标签,如建筑、汽车、卡车、电线杆、电线、围栏、地面和植被。
加载DALES数据
DALES数据集包含40个场景的航空激光雷达数据。在40个场景中,29个场景用于训练,其余11个场景用于测试。数据中的每个像素都有一个类标签。按照上面的说明去做山谷将数据集下载到指定的文件夹数据文件夹变量。创建文件夹以存储培训和测试数据。
dataFolder=fullfile(tempdir,“戴尔斯”);trainDataFolder = fullfile (dataFolder,“dales_las”,“火车”); testDataFolder=fullfile(dataFolder,“dales_las”,“测试”);
从训练数据预览点云。
lasReader = lasFileReader (fullfile (trainDataFolder“5080_54435.拉斯维加斯”));[pc, attr] = readPointCloud (lasReader“属性”,“分类”);标签=属性分类;%仅选择已标记的数据。pc=select(pc,labels~=0);labels=labels(labels~=0);classNames=[“地面”“植被”“汽车”“卡车”“电力线”“栅栏”“两极”“建筑”];图;ax=pcshow(pc.Location,labels);helperLabelColorbar(ax,类名);标题(“具有重叠语义标签的点云”);

数据进行预处理
DALES数据集中的每个点云覆盖的面积为500×500米,远大于地面旋转激光雷达点云覆盖的典型面积。为了高效的内存处理,请将点云划分为不重叠的小网格。
使用HelperCropPointClouds和合并标签函数,作为支持文件附于本示例,用于:万博1manbetx
将点云裁剪成大小为50 × 50米的不重叠网格。
将点云向下采样到固定大小。
将点云规格化为范围[0 1]。
将裁剪的网格和语义标签分别保存为PCD和PNG文件。
定义栅格尺寸并为每个栅格设置固定数量的点,以实现更快的训练。
gridSize=[50,50];numPoints=8192;
如果训练数据已划分为网格,则设置写文件来错误的。请注意,培训数据必须采用万博1manbetxpcread作用
writeFiles=true;numclass=numel(类名);[pcCropTrainPath,labelcroptrainpath,weights]=helpercroppointclouds和mergelabels(...gridSize、trainDataFolder、numPoints、WriteFile、numClass);
注意:处理过程可能需要一些时间。代码暂停MATLAB®执行,直到处理完成。
中捕获了所有类的训练数据集中的点分布砝码1.使贸易正常化砝码使用maxWeight.
[maxWeight, maxLabel] = max(重量);重量=√maxWeight. /重量);
创建用于培训的数据存储对象
创建一个文件数据存储对象以使用加载PCD文件pcread作用
LDSTREAN=文件数据存储(pcCropTrainPath,“ReadFcn”@ (x) pcread (x));
使用一个像素标签数据库对象来存储像素标签图像中的像素级标签。对象将每个像素标签映射到一个类名,并为每个类分配一个唯一的标签ID。
%指定从1到类数的标签id。labelIDs = 1: numClasses;一会,pxdsTrain = pixelLabelDatastore (labelsCropTrainPath labelIDs);
加载并显示点云。
ptcld=preview(ldsTrain);labels=preview(pxdsTrain);figure;ax=pcshow(ptcld.Location,uint8(labels));helperLabelColorbar(ax,classNames);title(“带有重叠语义标签的裁剪点云”);

使用helperConvertPointCloud函数,用于将点云转换为单元阵列。此函数还将排列点云的维度,使其与网络的输入层兼容。
ldsTransformed = transform(ldsTrain,@(x) helperConvertPointCloud(x));
使用结合函数将点云和像素标签组合到单个数据存储中进行培训。
dsTrain=联合收割机(ldsTransformed,pxdsTrain);
定义PointNet++模型
PointNet + + (2.]细分模型包括两个主要组成部分:
设置抽象模块
特征传播模块
该系列集合抽象模块通过分层分组点逐步对感兴趣的点进行二次采样,并使用自定义点网体系结构将点编码为特征向量。由于语义分割任务需要所有原始点的点特征,因此使用一系列特征传播模块使用基于逆距离的插值方案将特征分层插值到原始点。
使用定点多刺客作用
LGRAPHE=点网络多个杀戮者(numPoints,3,numclass);
为了处理DALES数据集上的类不平衡,从像素分类层函数。如果属于权重较低的类别的点被错误分类,这将对网络造成更大的惩罚。
%将焦点层替换为pixelClassificationLayer。larray=像素分类层(“姓名”,“SegmentationLayer”,“类权重”,...重量、“班级”类名);lgraph = replaceLayer (lgraph,“聚焦”,拉里);
指定培训选项
使用A水坝训练网络的优化算法。使用培训选项函数指定超参数。
learningRate=0.0005;L2规则化=0.01;numEpochs=20;miniBatchSize=6;learnRateDropFactor=0.1;learnRateDropPeriod=10;gradientDecayFactor=0.9;squaredGradientDecayFactor=0.999;选项=培训选项(“亚当”,...“初始学习率”,学习率,...“L2Regularization”,L2调节化,...“MaxEpochs”numEpochs,...“MiniBatchSize”miniBatchSize,...“LearnRateSchedule”,“分段”,...“LearnRateDropFactor”learnRateDropFactor,...“LearnRateDropPeriod”learnRateDropPeriod,...“梯度衰减因子”,梯度衰减因子,...“SquaredGradientDecayFactor”,平方半径衰减因子,...“情节”,“训练进步”);
注:降低成本小批量值来控制训练时的内存使用。
列车模型
您可以通过设置溺爱论据符合事实的. 如果你训练网络,你可以使用CPU或GPU。使用GPU需要并行计算工具箱™ 以及支持CUDA®的NVIDIA®GPU。有关详细信息,请参阅GPU支万博1manbetx持情况(并行计算工具箱)。否则,请加载预训练网络。
doTraining=false;如果溺爱%使用trainNetwork功能在dsTrain数据存储上训练网络。[net, info] = trainNetwork(dsTrain,lgraph,options);其他的%加载预训练的网络。装载(“pointnetplusTrained.mat”,“净”);终止
线段天线点云
网络在下采样点云上进行训练。要在测试点云上执行分段,首先对测试点云进行下采样,类似于如何对训练数据进行下采样。在此下采样测试点云上执行推断,以计算预测标签。插值预测标签,以获得密集点云上的预测标签。
定义numNearestNeighbors和半径为密集点云中的每个点在下采样点云中查找最近点,并有效执行插值。
numNearestNeighbors=20;半径=0.05;
阅读完整的测试点云。
lasReader=lasFileReader(完整文件(testDataFolder,“5080_54470.拉斯维加斯”));[pc, attr] = readPointCloud (lasReader“属性”,“分类”);LabelsDensetTarget=属性分类;%仅选择已标记的数据。pc=select(pc,LabelsDensetTarget~=0);labelsDenseTarget=labelsDenseTarget(labelsDenseTarget~=0);%初始化预测标签labelsDensePred = 0(大小(labelsDenseTarget));
根据计算非重叠栅格的数量gridSize,限制和YLimits点云的一部分。
numGridsX=圆形(diff(pc.XLimits)/gridSize(1));numGridsY=圆形(diff(pc.YLimits)/gridSize(2));[~,edgex,edgesY,indx,indy]=历史计数2(pc.Location(:,1),pc.Location(:,2),...[numGridsX,numGridsY],“XBinLimits”,pc.XLimits,“YBinLimits”, pc.YLimits);印第安纳州= sub2ind ([numGridsX numGridsY], indx,印第安纳·琼斯);
迭代所有非重叠网格并使用语义词组F功能。
对于num=1:numGridsX*numGridsY idx=ind==num;ptclouddensed=select(pc,idx);labeldensed=labeldensetarget(idx);%使用本示例附带的helperDownsamplePoints函数作为%支万博1manbetx持文件,用于从%密集点云。ptCloudSparse=helperDownsamplePoints(ptCloudDense,...labelsDense numPoints);%绘制稠密点云和稀疏点的空间范围%的云一样。限制=[ptclouddensel.XLimits;ptclouddensel.YLimits;ptclouddensel.ZLimits];ptCloudSparseLocation=ptcloudsparsel.Location;ptCloudSparseLocation(1:2,:)=限制(:,1:2)”;ptcloudsparsel=pointCloud(ptCloudSparseLocation,“颜色”, ptCloudSparse。的颜色,...“强度”,ptcloud.Intensity,...“正常”,ptCloudSparse.Normal);%使用本示例附带的helperNormalizePointCloud函数%支持文万博1manbetx件,用于规范化0和1之间的点云。ptCloudSparseNormalized=helperNormalizePointCloud(ptCloudSparse);ptclouddenormalized=helperNormalizePointCloud(ptclouddensed);%使用在本文末尾定义的helperConvertPointCloud函数%例如,将点云转换为单元阵列并排列%点云的尺寸,使其与输入层兼容%网络的一部分。ptCloudSparseForPrediction=帮助转换点云(ptCloudSparseNormalized);%获取输出预测。labelsSparsePred = semanticseg (ptCloudSparseForPrediction {1},...网“输出类型”,‘uint8’);%使用本示例附带的helperInterpolate函数作为%支万博1manbetx持文件,用于计算密集点云的标签,%使用稀疏点云和在稀疏点云上预测的标签。interpolatedLabels=helperInterpolate(ptCloudDenormalized,...PTCLOUDSPARSENORMAL,标签SPARSEPRED,numNearestNeighbors,...半径,maxLabel numClasses);labelsDensePred (idx) = interpolatedLabels;终止
正在使用连接到并行池的“本地”配置文件启动并行池(parpool)(工作进程数:6)。
为了更好地可视化,请从点云数据中选择感兴趣的区域。修改中的限制投资回报率根据点云数据变化。
roi=[EDGEESX(5)EDGEESX(8)edgesY(8)edgesY(11)pc.ZLimits];索引=查找点roi(pc,roi);图;ax=pcshow(选择(pc,索引)。位置,标签显示(索引));轴关;缩放(ax,1.5);helperLabelColorbar(ax,类名);标题(“点云与检测到的语义标签重叠”);
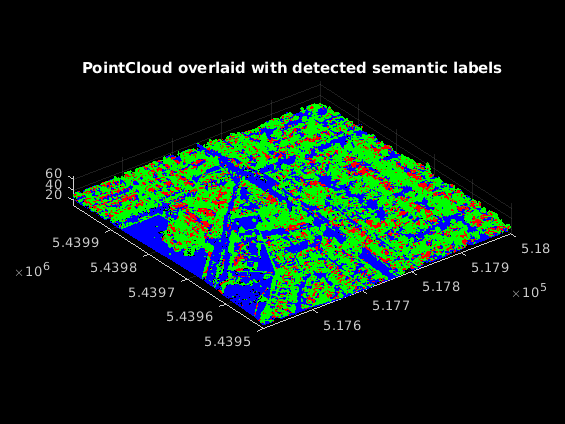
评估网络
根据测试数据评估网络性能。使用评价语义切分函数从测试集结果计算语义分段度量。目标和预测标签是预先计算的,并存储在标签深红色和labelsDenseTarget变量。
confusionMatrix=分段confusionMatrix(标签编号,...双(LabelsDensetTarget),“班级”,1:numclass);metrics=evaluateSemanticSegmentation({confusionMatrix},类名,“详细”,假);
您可以使用联合交叉(IoU)度量度量每个类的重叠量。
这个评价语义切分函数返回整个数据集、单个类和每个测试映像的度量metrics.DataSetMetrics所有物
metrics.DataSetMetrics
ans =1×4表全球准确度意味着准确度意味着权重你0.93191 0.64238 0.52709 0.88198
数据集指标提供了网络性能的高级概述。要查看每个类对总体性能的影响,请使用度量所有物
度量
ans =8×2表精度IoU ________ _________ ground 0.98874 0.93499 vegetation 0.5948 0.81865 cars 0.61847 0.36659 trucks 0.018676 0.0070006电源线0.7758 0.6904围栏0.3753 0.21718电杆0.5741 0.28528 buildings 0.92843 0.89662
虽然总体网络性能很好,但是类的指标对于一些类来说,比如卡车表明需要更多的培训数据才能获得更好的绩效。
万博1manbetx辅助功能
这个helperLabelColorbar函数将颜色条添加到当前轴。颜色栏被格式化为使用颜色显示类名。
作用helperLabelColorbar(ax,类名)% Colormap的原始类。cmap=[0,0255];[0255,0];[255192203];[255255,0];[255,0255];[255165,0];[139,0150];[255,0,0];cmap=cmap./255;cmap=cmap(1:numel(类名),:);颜色映射(ax,cmap);%将颜色栏添加到当前图形。c=颜色条(ax);c.颜色=“w”;%将记号标签居中,并使用类名称作为记号标记。numClasses=大小(类名,1);c、 Ticks=1:1:numclass;c、 标签=类名;%删除勾号。c.TickLength = 0;终止
这个helperConvertPointCloud函数将点云转换为单元数组,并排列点云的维度,使其与网络的输入层兼容。
作用数据=helperConvertPointCloud(数据)如果~iscell(data)data={data};终止numObservations=大小(数据,1);对于i=1:numobervations tmp=data{i,1}.Location;data{i,1}=permute(tmp[1,3,2]);终止终止
工具书类
[1] Varney Nina Vijayan K. Asari和Quinn Graehling。DALES:用于语义分割的大规模航空激光雷达数据集。ArXiv: 2004.11985 (Cs,统计),2020年4月14日。https://arxiv.org/abs/2004.11985.
李毅,苏浩,列奥尼达斯·j·古巴斯。PointNet++:度量空间点集的深度层次特征学习。ArXiv:1706.02413[Cs], 2017年6月7日。https://arxiv.org/abs/1706.02413.
您还可以从以下列表中选择网站: