evaluateSemanticSegmentation
评估对地面实况语义分割数据集
句法
描述
例子
输入参数
dsResults-预测像素标签
数据存储|PixelLabelDatastore宾语|PixelLabelImageDatastore|数据存储对象的单元数组
从语义分割所得的预测像素标签,指定为数据存储或数据存储的对象的单元阵列。dsResults可以是返回分类图像的任何数据存储,例如PixelLabelDatastore要么pixelLabelImageDatastore。该读(dsResults)必须返回一个分类数组、单元格数组或表。如果读函数返回一个多列单元格数组或表,第二列必须包含分类数组。
dsTruth-地面真实像素标签
PixelLabelDatastore宾语|单元阵列的PixelLabelDatastore对象
地面真值像素标签,指定为数据存储或数据存储对象的单元数组。dsResults可以是返回分类图像的任何数据存储,例如PixelLabelDatastore要么pixelLabelImageDatastore。使用读(dsTruth)必须返回一个分类数组、单元格数组或表。如果读函数返回一个多列单元格数组或表,第二列必须包含分类数组。
名称-值对的观点
指定可选的逗号分隔的对名称,值参数。名称参数名和价值是对应的值。名称必须出现在引号内。可以按任意顺序指定多个名称和值对参数名1,值1,...,NameN,值N。
指标= evaluateSemanticSegmentation (pxdsResults pxdsTruth,“指标”,“bfscore”)只计算每个类,每个图像,并且整个数据集的平均值BF得分。
“指标”-细分指标
“所有”(默认)|向量的字符串
分割度量semanticSegmentationMetrics要计算,指定为逗号分隔的对“指标”和一个弦向量。参数中指定了哪些变量DataSetMetrics,ClassMetrics,ImageMetrics表来计算。ConfusionMatrix和NormalizedConfusionMatrix无论被计算的值的“指标”。
| 价值 | 描述 | 聚合数据集度量 | 图片公制 | 类指标 |
|---|---|---|---|---|
“所有” |
评估所有语义分割指标。 | 所有的聚集数据集度量 | 所有图像指标 | 所有类指标 |
“准确性” |
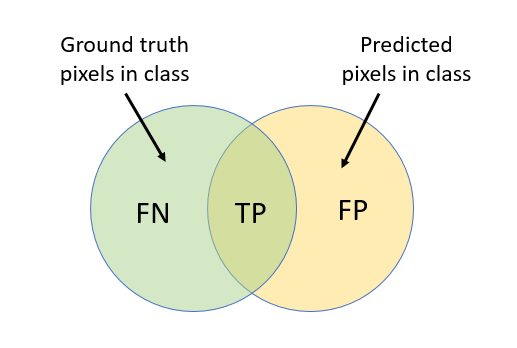
准确度表示为每个类正确识别像素的百分比。如果你想知道如何以及每类正确地识别像素,可以使用精度指标。
类精度是一个类似于全局精度的简单度量,但是它可能会产生误导。例如,将所有像素标记为“car”,会给“car”类一个完美的分数(尽管对其他类不是这样)。使用类的准确性,在conjuction与IoU更完整的评估分割结果。 |
MeanAccuracy |
MeanAccuracy |
准确性 |
“bfscore” |
边界F1(BF)轮廓匹配得分指示如何预测边界每个类对准与真正的边界。如果你想有一个指标,往往关联更好地与比欠条度量人的定性评估使用BF得分。
有关更多信息,请参见 |
MeanBFScore |
MeanBFScore |
MeanBFScore |
“全球精确度” |
|
GlobalAccuracy |
GlobalAccuracy |
没有一个 |
“借据” |
交叉点上接头(IOU),也被称为Jaccard相似系数,是最常用的度量。如果你想有一个统计精度测量的是惩罚误报使用欠条度量。
有关更多信息,请参见 |
MeanIoU |
MeanIoU |
期票 |
“加权-IOU” |
每个类的平均IOU,通过在类的像素的数目进行加权。使用本标准,如果图像有不成比例的大小班,以减少错误的小班总质量分数的影响。 | WeightedIoU |
WeightedIoU |
没有一个 |
例子:度量= evaluateSemanticSegmentation(pxdsResults,pxdsTruth, '指标',[ “全球精度”, “IOU”])计算数据集、图像和类的全局精度和IoU指标。
数据类型:串
“详细”-标志来显示评估进展
1(默认)|0
标志在命令窗口显示评价进展信息,指定为逗号分隔的一对组成的“详细”,要么1(真正的)或0(假)。
显示的信息包括一个进度条,经过时间,估计的剩余时间,及数据集的度量。
例子:度量= evaluateSemanticSegmentation(pxdsResults,pxdsTruth, '冗长',0)计算分割指标,但不显示进度信息。
数据类型:合乎逻辑
输出参数
参考
[1] Csurka,G.,D. Larlus,和F. Perronnin。“什么是语义分割了很好的评价措施?”英国机器视觉会议记录, 2013,第32.1-32.11页。
扩展功能
介绍了在R2017b
你也可以从以下列表中选择一个网站:
