在云中处理大数据
这个例子说明了如何访问一个大的数据集在云中,并使用MATLAB能力大数据处理它的云团。
学习如何:
访问亚马逊云上公开的大型数据集。
查找并选择此数据集的有趣子集。
使用数据存储、长数组和并行计算工具箱在不到20分钟的时间内处理这个子集。
本例中的公共数据集是风集成国家数据集工具包,或WIND工具包[1],[2],[3],[4]的一部分。欲了解更多信息,请参阅风电整合全国数据集工具包。
要求
要运行此示例,必须在Amazon AWS中设置对集群的访问。在MATLAB中,您可以直接从MATLAB桌面在AmazonAWS中创建集群。上家选项卡,在平行菜单,选择创建和管理群集。在群集配置文件管理器,单击创建云计算集群。另外,您也可以使用MathWorks的云计算中心来创建和亚马逊的AWS访问计算集群。欲了解更多信息,请参阅开始使用云中心。
设置对远程数据的访问
在本实施例中使用的数据集是经济技术WIND工具包。它包含有从2007年大气变量沿风电测算的数据和预测的2 TB(兆兆字节),到2013年美国大陆内
技术经济风工具包可通过亚马逊网络服务在该位置s3: / / pywtk-data。它包含两个数据集:
s3: / / pywtk-data / met_data-计量数据
S3:// pywtk数据/ fcst_data- 预测数据
要在Amazon S3中使用远程数据,必须为AWS凭据定义环境变量。有关设置远程数据访问权限的详细信息,请参阅处理远程数据(MATLAB)。在下面的代码中,替换您的访问密钥ID和您的密钥使用您自己的Amazon AWS凭据。
setenv (“AWS_ACCESS_KEY_ID”,“YOUR_AWS_ACCESS_KEY_ID”);设置环境(“AWS_SECRET_ACCESS_KEY”,“YOUR_AWS_SECRET_ACCESS_KEY”);
此数据集要求您指定其地理区域,因此必须设置相应的环境变量。
setenv (“AWS_DEFAULT_REGION”,“美西2”);
要让集群中的工作人员访问远程数据,请将这些环境变量名添加到环境变量集群配置文件的属性。要编辑集群配置文件的属性,请使用集群配置文件管理器in平行>创建和管理群集。
发现大数据的子集
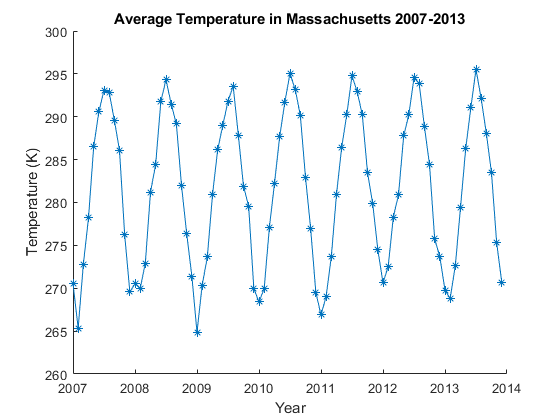
2 TB的数据集相当大。本例向您展示如何查找要分析的数据集的子集。这个例子关注的是马萨诸塞州的数据。
首先获得马萨诸塞州计量站的id,并确定包含其计量信息的文件。每个站点的元数据信息都在一个名为的文件中three_tier_site_metadata.csv。因为这个数据是小和配合在内存中,可以从MATLAB客户端访问可读性. 你可以使用可读性函数可以直接访问S3 bucket中的开放数据,而不需要编写特殊的代码。
tMetadata = readtable (“s3: / / pywtk-data / three_tier_site_metadata.csv”,...“读取变量名称”,真的,“TextType”,“字符串”);
要查明此数据集中列出了哪些状态,请使用独特的。
州=独特(tMetadata.state)
国家=50×1字符串数组”““阿拉巴马”“亚利桑那”“阿肯色”“加州”“科罗拉多”“康涅狄格”“特拉华”“特区”“佛罗里达”“格鲁吉亚”“爱达荷州”“伊利诺斯州”“印第安纳州”“爱荷华州”“堪萨斯”“肯德基”“路易斯安那州”“缅因”“马里兰”“麻省”“密歇根”“明尼苏达州”“密西西比”“密苏里”“蒙大拿”“内布拉斯加”“内华达”“新汉普郡”“新泽西”“新墨西哥”“纽约”“北卡罗来纳”“北达科塔州”“俄亥俄”“俄克拉荷马”“俄勒冈州”“宾夕法尼亚”“罗德岛”“南卡罗来纳”“南达科塔州”“田纳西”“德州”"Utah" "Vermont" "Virginia" "Washington" "West Virginia" "Wisconsin" "Wyoming"
确定哪些电台位于马萨诸塞州。
索引=tMetadata.state==“马萨诸塞州”;siteId=tMetadata{索引,“site_id”};
给定电台的数据包含在一个文件中,该文件遵循以下命名约定:S3://pywtk-data/met_data/folder/site_id.nc,其中文件夹最近的整数是小于还是等于site_id / 500。使用这个约定,构成一个文件位置每个站。
文件夹=地板(siteId / 500);fileLocations =组成(“s3://pywtk data/met_data/%d/%d.nc”、文件夹、siteId);
处理大数据
您可以使用数据存储和高大的阵列到不适合在内存访问和处理数据。在进行大数据计算,MATLAB访问远程数据的较小部分根据需要,所以你不需要下载整个数据集,同时做。高大阵列,MATLAB自动断开的数据转换成适合在存储器中用于处理更小的块。
如果你有并行计算工具箱,MATLAB可以并行处理多个块。并行化使您能够在具有本地工作线程的单个桌面上运行分析,或扩展到群集以获取更多资源。当您在与数据相同的云服务中使用集群时,数据将保留在云中,并且您可以从改进的数据传输时间中获益。将数据保存在云中也更具成本效益。这个例子在AmazonAWS的c4.8X大型机器上运行了不到20分钟,使用了18个工人。
如果在集群中使用并行池,则MATLAB将使用集群中的工作器处理这些数据。在群集中创建一个并行池。在下面的代码中,改用集群配置文件的名称。将脚本附加到池,因为并行工作器需要访问池中的帮助器函数。
p = parpool (“myAWSCluster”);
使用'myAWSCluster'配置文件启动并行池(parpool)…连接到18个工人。
addAttachedFiles (p, mfilename (“完整路径”));
用马萨诸塞州各站的计量数据创建一个数据存储。数据以网络通用数据格式(NetCDF)文件的形式存在,必须使用自定义读取函数来解释它们。在这个例子中,这个函数被命名为ncReader并读取NetCDF数据到时间表。您可以在此脚本结束探讨的内容。
dsMetrology=fileDatastore(文件位置,“ReadFcn”,@ncReader,“UniformRead”,真正的);
用数据存储中的计量数据创建一个高的时间表。
ttMetrology =高(dsMetrology)
2007年1月1日00:00:00 5.905 189.35 3.3254 1.2374 269.74 97963 2007年1月1日00:05:00 5.8898 188.77 3.2988 1.2376 269.73 97959 2007年1月1日00:10:00 5.9447 187.85 3.396.4331 182.51 4.3382 1.2382 270.3 97957::::::::::::: : : :
使用组摘要,并对生成的高表进行排序。为了提高性能,在需要数据之前,MATLAB会推迟大多数高阶操作。在这种情况下,绘制数据会触发延迟计算的计算。
meanTemperature = groupsummary (ttMetrology,“时间”,“月”,“的意思是”,“温度”);meanTemperature = sortrows (meanTemperature);
策划的结果。
图;情节(meanTemperature.mean_temperature“* - ”);ylim([260 300]);XLIM([1 12 * 7 + 1]);xticks(1:12:12 * 7 + 1);xticklabels([“2007”,“2008”,“2009年”,“2010年”,“2011年”,“2012”,“2013”,“2014”]);标题(《马萨诸塞州2007-2013年平均气温》);包含(“年”);ylabel (“温度(K)”)
许多MATLAB功能支持高大的阵列,这样你就万博1manbetx可以执行各种使用熟悉的语法大数据集的计算。有关支持的功能的更多信息,请参阅万博1manbetx万博1manbetx支持功能(MATLAB)。
定义自定义读函数
在技术经济WIND工具包中的数据被保存NetCDF文件中。定义一个定制的读取功能来读取其数据到一个时间表。有关阅读的NetCDF文件的详细信息,请参阅NetCDF文件(MATLAB)。
功能T = ncReader(文件名)读取NetCDF文件(.nc),提取数据集并保存为时间表关于NetCDF数据源%获取信息fileInfo=ncinfo(文件名);%提取变量名和数据类型varNames =字符串({fileInfo.Variables.Name});varTypes =字符串({fileInfo.Variables.Datatype});%将变量名转换为表变量的有效名称如果任何(startsWith (varNames, (“4”,“6”])) strVarNames =替换(varNames,[“4”,“6”]、[“四”,“6”]);其他的strVarNames=变量名;结束提取每个变量的长度fileLength = fileInfo.Dimensions.Length;提取初始时间戳、采样周期并创建时间轴tAttributes = struct2table (fileInfo.Attributes);开始时间= datetime (cell2mat (tAttributes.Value(包含(tAttributes.Name,“开始时间”))),“ConvertFrom”,“epochtime”);samplePeriod =秒(cell2mat(tAttributes.Value(含有(tAttributes.Name,“sample_period”))));%创建输出时间表numVars=numel(strVarNames);tableSize=[文件长度numVars];t=时间表('大小'tableSize,“变量类型”,变量类型,“VariableNames”strVarNames,“时间步”samplePeriod,“开始时间”、开始时间);用可变的数据填写时间表为k = 1:numVars t(:,k) = table(ncread(filename,varNames{k}));结束结束
参考
[1] Draxl,C.,B.M.Hodge,A.Clifton和J.McCaa。在风电整合全国数据集工具包的概述和气象验证(技术报告,NREL/TP-5000-61740)。科罗拉多州戈尔登:国家可再生能源实验室,2015年。
[2] Draxl,C.,B.M.Hodge,A.Clifton和J.McCaa。”风力集成国家数据集工具包。”应用能. 2015年第151卷,第355-366页。
[3]特大,J.,A.克利夫顿,和B. M.霍奇。功率输出的验证了WIND工具包(技术报告,NREL / TP-5D00-61714)。黄金,CO:国家可再生能源实验室,2014年
[4]李伯曼-克里宾,W., C.德拉xl,和A.克利夫顿。WIND工具包验证代码使用指南(技术报告,NREL / TP-5000-62595)。黄金,CO:国家可再生能源实验室,2014年
另请参阅
相关的例子
- 处理远程数据(MATLAB)
- 发现群集并使用群集配置文件
更多关于
- 将深度学习数据上传到云端
- 深度学习与gpu大数据并行(深度学习工具箱)
您还可以选择从下面的列表中的网站: