训练类人助行器
这个例子展示了如何使用Simscape多体™ 并使用遗传算法(需要全局优化工具箱许可证)或强化学习(需要深度学习工具箱™ 和强化学习工具箱™ 许可证)。
仿人步行器模型
此示例基于人形机器人模型。您可以通过输入sm_进口_类人_urdf在MATLAB®命令提示符中。机器人的每只腿的前部髋关节、膝盖和脚踝都有扭矩驱动的旋转关节。每只手臂的前部和矢状肩部都有两个被动旋转关节。在模拟过程中,模型感知接触力、躯干的位置和方向、关节状态和向前位置。figu在不同层次上重新显示Simscape多体模型。


接触建模
模型使用空间接触力块以模拟脚与地面之间的接触。为了简化接触和加速模拟,使用红色球体表示机器人脚的底部。有关详细信息,请参阅使用联系人代理来模拟联系人.
联合控制员
该模型使用基于刚度的反馈控制器来控制每个关节[1]。将关节建模为具有相关刚度的一阶系统(K)阻尼(B),可以将其设置为使关节行为严重阻尼。当设定值为 与当前关节位置不同 :
.
可以改变弹簧设定点 获取反馈响应以移动关节。该图显示了控制器的Simulink模型。万博1manbetx
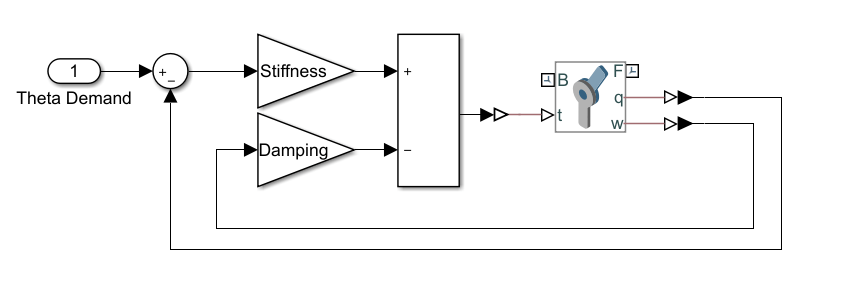
仿人步行训练
本例的目标是训练仿人机器人行走,您可以使用各种方法训练机器人。算例说明了遗传算法和强化学习方法。
步行目标函数
这个例子使用一个目标函数来评估不同的行走方式。模型给出了一个奖励( )在每个时间步:
在这里:
-前进速度(秒)
-耗电量(处罚)
-垂直位移(处罚)
-侧向位移(处罚)
:权重,表示奖励函数中每个项的相对重要性
此外,不摔倒也会得到奖励。
因此,总报酬( )对于步行试验而言:
在这里
是模拟终止的时间。您可以在中更改奖励权重sm_类人机器人_步行者_rl_参数剧本当达到模拟时间或机器人摔倒时,模拟终止。坠落的定义是:
机器人下降到0.5米以下。
机器人横向移动超过1米。
机器人躯干旋转超过30度。
遗传算法训练
要优化机器人的行走,可以使用遗传算法。遗传算法基于模仿生物进化的自然选择过程来解决优化问题。遗传算法特别适用于目标函数不连续、不可微、随机或高度非线性的问题。对于e信息,见ga(全局优化工具箱).

该模型将每个关节的角度需求设置为重复模式,类似于自然界中的中心模式生成器[2]。重复模式产生一个开环控制器。信号的周期性是步态周期,即完成一整步所需的时间。在每个步态周期内,信号在不同的角度需求值之间切换。理想情况下,仿人机器人对称行走,并且控制右腿每个关节的模式模式生成器的目标是确定每个关节的最佳控制模式,并使行走目标函数最大化。
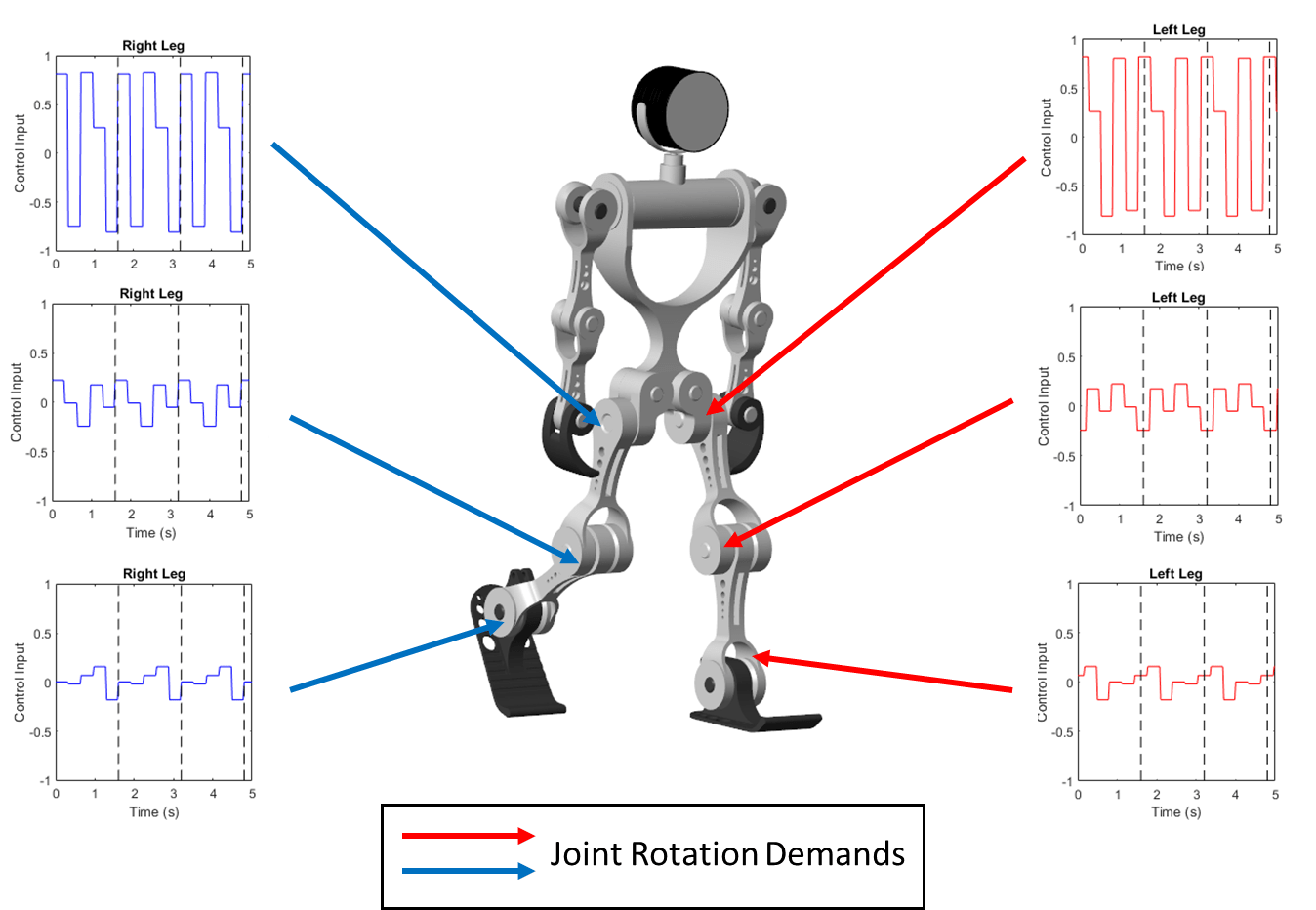
要使用遗传算法训练机器人,请打开仿人步行火车默认情况下,本例使用预训练的仿人步行器。要训练仿人步行器,请设置火车行者到符合事实的.
强化学习训练
或者,您也可以使用深度确定性策略梯度(DDPG)强化学习代理来训练机器人。DDPG代理是一个学习代理,它计算一个使长期回报最大化的最优策略。DDPG代理可用于具有连续动作和状态的系统。有关DDPG代理的详细信息,请参阅RLDDPG试剂(强化学习工具箱).

要使用强化学习训练机器人,请打开sm_类人步行火车默认情况下,本例使用预训练的仿人步行器。要训练仿人步行器,请设置火车行者到符合事实的.
工具书类
[1] 卡尔维拉姆、卡尔·T、托马斯·席诺尔、斯蒂芬·贝尔、斯蒂芬妮·里希特和佩特拉·詹森·奥斯曼。“将神经前馈引入机械弹簧:生物学如何在肢体控制中利用物理学。”生物控制论92,第4号(2005年4月):229-40。https://doi.org/10.1007/s00422-005-0542-6.
[2] 姜山,程俊石,陈佳萍。“基于多目标遗传算法的仿人机器人步行中心模式发生器设计”,年诉讼。2000年IEEE/RSJ智能机器人和系统国际会议(IROS 2000)(分类号00CH37113),3:1930-35。高松,日本:IEEE,2000年。https://doi.org/10.1109/IROS.2000.895253.
另见
相关话题
您还可以从以下列表中选择网站:
