创建代理定制的强化学习算法
这个例子展示了如何创建一个自定义代理自己的自定义强化学习算法。这样做允许您利用下面的内置功能的强化学习工具箱™软件。
在本例中,您定制的强化训练循环转化为一个自定义代理类。加强定制火车上循环的更多信息,见训练强化学习策略使用自定义训练循环。有关编写定制代理类的更多信息,请参阅创建自定义强化学习代理。
解决随机发生器再现性的种子。
rng (0)
创建环境
创造同样的训练环境中使用训练强化学习策略使用自定义训练循环的例子。环境是一个cart-pole平衡环境与离散的行动空间。创建环境使用rlPredefinedEnv函数。
env = rlPredefinedEnv (“CartPole-Discrete”);
从环境中提取观测和操作规范。
obsInfo = getObservationInfo (env);actInfo = getActionInfo (env);
获得观测的数量(numObs)和行为(numAct)。
numObs = obsInfo.Dimension (1);numAct =元素个数(actInfo.Elements);
这个环境的更多信息,请参阅负载预定义的控制系统环境。
定义政策
强化学习策略在本例中是一个相关联行为随机政策。它是由一个深层神经网络,其中包含表示fullyConnectedLayer,reluLayer,softmaxLayer层。这个网络输出为每个离散行动在当前观测概率。的softmaxLayer确保表示输出概率值在[0,1],所有概率之和为1。
为演员创造深层神经网络。
actorNetwork = [featureInputLayer numObs,“归一化”,“没有”,“名字”,“状态”)fullyConnectedLayer(24日“名字”,“fc1”)reluLayer (“名字”,“relu1”)fullyConnectedLayer(24日“名字”,“取得”)reluLayer (“名字”,“relu2”)fullyConnectedLayer (2“名字”,“输出”)softmaxLayer (“名字”,“actionProb”));
创建一个使用一个演员表示rlStochasticActorRepresentation对象。
actorOpts = rlRepresentationOptions (“LearnRate”1 e - 3,“GradientThreshold”1);演员= rlStochasticActorRepresentation (actorNetwork,…obsInfo actInfo,“观察”,“状态”,actorOpts);
自定义代理类
定义您的自定义代理,首先创建一个类的一个子类rl.agent.CustomAgent类。这个例子的定制代理类中定义CustomReinforceAgent.m。
的CustomReinforceAgent类有下面的类定义,这表明代理类名称和相关的抽象代理。
classdefCustomReinforceAgent < rl.agent.CustomAgent
定义你的代理必须指定以下:
代理的属性
构造函数
评论家表示,估计折现长期奖励(如果需要学习)
演员表示,选择一个行动基于当前观测(如果需要学习)
需要代理的方法
可选代理方法
代理的属性
在属性部分的类文件,指定用于创建和培训代理任何必要的参数。
的rl.Agent.CustomAgent类已经包含了属性代理示例时间(SampleTime)和行动和观测规范(ActionInfo和ObservationInfo分别)。
自定义增强剂定义以下额外的代理属性。
属性%的演员表示演员%代理选项选项%经验缓冲ObservationBuffer ActionBuffer RewardBuffer结束属性(访问=私人)%培训工具计数器NumObservation NumAction结束
构造函数
要创建定制代理,您必须定义一个构造函数。构造函数执行以下操作。
和观测规范定义了行动。创建这些规范的更多信息,请参阅
rlNumericSpec和rlFiniteSetSpec。集代理属性。
调用抽象基类的构造函数。
定义了样本时间在仿真软件环境(需要训练)。万博1manbetx
例如,CustomREINFORCEAgent构造函数定义操作和观察空间基于输入演员表示。
函数obj = CustomReinforceAgent(演员,选项)% CUSTOMREINFORCEAGENT构建自定义代理% = CUSTOMREINFORCEAGENT代理(演员、期权)创建自定义%加强代理rlStochasticActorRepresentation演员%和结构的选择。选择字段:% - DiscountFactor% - MaxStepsPerEpisode%(必需)调用抽象类的构造函数。obj = obj@rl.agent.CustomAgent ();obj。ObservationInfo = Actor.ObservationInfo;obj。ActionInfo = Actor.ActionInfo;%(仿真软件所需环境)注册样品时万博1manbetx间。%为MATLAB环境,使用1。obj。SampleTime = 1;%(可选)注册演员和代理的选择。演员= setLoss(演员,@lossFunction);obj。演员=演员;obj。选择=选项;%(可选)缓存数量的观察和操作。obj。NumObservation = prod (obj.ObservationInfo.Dimension);obj。NumAction = prod (obj.ActionInfo.Dimension);%(可选)初始化缓冲和计数器。重置(obj);结束
构造函数集演员的损失函数使用一个函数句柄表示lossFunction作为当地的一个函数实现CustomREINFORCEAgent.m。
函数损失= lossFunction(政策、lossData)政策={1}政策;%创建行动指示矩阵。batchSize = lossData.batchSize;Z = repmat (lossData.actInfo.Elements ', 1, batchSize);actionIndicationMatrix = lossData.actionBatch (:,) = = Z;%调整折扣返回政策的规模。G = actionIndicationMatrix。* lossData.discountedReturn;G =重塑(G,大小(政策);%轮任何政策价值低于每股收益,每股收益。政策(政策< eps) =每股收益;%计算损失。损失=总和(G。*日志(政策),“所有”);结束
所需的功能
创建一个定制的强化学习代理必须定义以下实现功能。
getActionImpl——评估代理政策和选择一个代理在模拟。getActionWithExplorationImpl——评估政策和选择一个行动探索在训练。learnImpl——代理学习如何从当前的经验
在您自己的代码中调用这些函数,使用包装器方法的抽象基类。例如,电话getActionImpl,使用getAction。包装器方法有相同的输入和输出参数的实现方法。
getActionImpl函数
的getActionImpl函数是用来评估你的代理政策和选择一个行动时模拟代理使用sim卡函数。这个函数必须有以下签名,obj是代理对象,观察目前的观察,行动是选择的行动。
函数Action = getActionImpl (obj,观察)
对于自定义增强剂,你选择一个行动通过调用getAction函数为参与者表示。离散rlStochasticActorRepresentation生成一个离散分布的观察和操作从这个样品分布。
函数Action = getActionImpl (obj,观察)%计算使用政策在当前操作%的观察。Action = getAction (obj.Actor、观察);结束
getActionWithExplorationImpl函数
的getActionWithExplorationImpl函数选择一个行动时使用探索模型的代理培训代理使用火车函数。使用此函数可以实现勘查技术,如epsilon-greedy勘查或添加高斯噪声。这个函数必须有以下签名,obj是代理对象,观察目前的观察,行动是选择的行动。
函数Action = getActionWithExplorationImpl (obj,观察)
对于自定义增强剂,getActionWithExplorationImpl功能是一样的getActionImpl。默认情况下,随机演员总是探索,也就是说,他们总是选择一个行动基于概率分布。
函数Action = getActionWithExplorationImpl (obj,观察)%计算使用探索政策考虑到一个动作当前观测%。%加强:随机演员总是默认探索%(样本概率分布)Action = getAction (obj.Actor、观察);结束
learnImpl函数
的learnImpl函数定义了代理如何从当前的经验学习。这个函数实现了自定义学习算法更新代理的政策参数和选择一个行动和探索下一个状态。这个函数必须有以下签名,obj是代理对象,经验是当前代理经验,行动是选择的行动。
函数Action = learnImpl (obj,经验)
代理经验是细胞数组经验={状态、动作、奖励、nextstate结束}。在这里:
状态是当前观测。行动是当前的行动。这是不同的输出参数行动为下一个状态,它是一种行动。奖励是当前的奖励。nextState是下一个观测。结束是一个逻辑标志,指示训练集是完整的。
自定义增强剂,重复步骤2到7的定制培训循环训练强化学习策略使用自定义训练循环。你省略步骤1,8,9,因为你将使用内置的火车函数来训练你的代理。
函数Action = learnImpl (obj,经验)%定义代理学习如何从一个经验,这是一个%单元阵列使用以下格式。%的经验={观察、行动、奖励、nextObservation结束}%重置缓冲初的一集。如果obj。计数器< 2 resetBuffer (obj);结束%从经验中提取数据。奥林匹克广播服务公司={1}经验;Action ={2}经历;奖励={3}经验;NextObs ={4}经验;结束={5}经验;%保存数据缓冲区。obj.ObservationBuffer (:,:, obj.Counter) =观察{1};obj.ActionBuffer (:,:, obj.Counter) ={1}行动;obj.RewardBuffer (:, obj.Counter) =奖励;如果~结束%为下一个状态选择一个行动。Action = getActionWithExplorationImpl (obj NextObs);obj。Counter = obj。计数器+ 1;其他的%从情景数据。%收集数据的缓冲区。BatchSize = min (obj.Counter obj.Options.MaxStepsPerEpisode);ObservationBatch = obj.ObservationBuffer (:: 1: BatchSize);ActionBatch = obj.ActionBuffer (:: 1: BatchSize);RewardBatch = obj.RewardBuffer (:, 1: BatchSize);%计算贴现未来的回报。BatchSize DiscountedReturn = 0 (1);为t = 1: BatchSize G = 0;为k = t: BatchSize G = G + obj.Options。DiscountFactor ^(前提)* RewardBatch (k);结束DiscountedReturn (t) = G;结束%组织数据传递损失函数。LossData。batchSize = batchSize;LossData。actInfo = obj.ActionInfo;LossData。行动Batch = ActionBatch; LossData.discountedReturn = DiscountedReturn;%的梯度计算的损失%的演员参数。ActorGradient =梯度(obj.Actor @lossFunction,…{ObservationBatch}, LossData);%更新演员参数使用梯度计算。obj。演员=优化(obj.Actor ActorGradient);%重置计数器。obj。Counter = 1;结束结束
可选功能
可选地,您可以定义您的代理是如何重置通过指定的培训resetImpl与下面的函数签名功能,obj是代理对象。
函数resetImpl (obj)
使用此功能,您可以设置代理知道或随机条件前培训。
函数resetImpl (obj)%(可选)定义如何重置之前培训/代理resetBuffer (obj);obj。Counter = 1;结束
还可以定义其他辅助函数根据需要自定义代理类。例如,定义一个自定义加强代理resetBuffer函数重新初始化每个训练集的初体验缓冲区。
函数resetBuffer (obj)%初始化所有经验缓冲区。obj。ObservationBuffer = 0 (obj.NumObservation 1 obj.Options.MaxStepsPerEpisode);obj。ActionBuffer = 0 (obj.NumAction 1 obj.Options.MaxStepsPerEpisode);obj。obj.Options.MaxStepsPerEpisode RewardBuffer = 0 (1);结束
创建自定义代理
一旦你定义了你的定制代理类,在MATLAB工作区中创建一个实例。创建自定义增强剂,首先指定代理选项。
选项。MaxStepsPerEpisode = 250;选项。DiscountFactor = 0.995;
然后,使用选项和前面定义的演员表示,构造函数调用自定义代理。
代理= CustomReinforceAgent(演员、期权);
火车定制代理
使用以下选项配置培训。
设置培训持续最多5000集,每集持续最多250步。
终止培训达到的最大数量集后或当奖励在100集平均达到240的值。
有关更多信息,请参见rlTrainingOptions。
numEpisodes = 5000;aveWindowSize = 100;trainingTerminationValue = 240;trainOpts = rlTrainingOptions (…“MaxEpisodes”numEpisodes,…“MaxStepsPerEpisode”options.MaxStepsPerEpisode,…“ScoreAveragingWindowLength”aveWindowSize,…“StopTrainingValue”,trainingTerminationValue);
火车代理使用火车函数。培训这个代理是一个计算密集型的过程需要几分钟才能完成。节省时间在运行这个例子中,加载一个pretrained代理设置doTraining来假。训练自己代理,集doTraining来真正的。
doTraining = false;如果doTraining%培训代理。trainStats =火车(代理,env, trainOpts);其他的%负载pretrained代理的例子。负载(“CustomReinforce.mat”,“代理”);结束

模拟定制代理
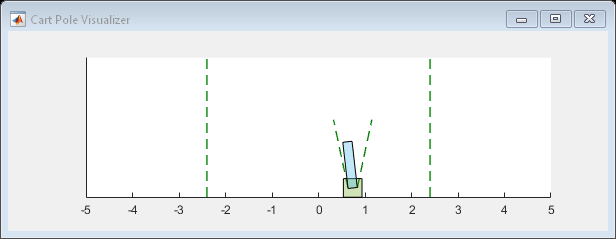
支持环境的可视化,这是每次更新的环境一步函数被调用。
情节(env)
验证培训代理的性能,模拟在cart-pole环境。代理模拟更多的信息,请参阅rlSimulationOptions和sim卡。
simOpts = rlSimulationOptions (“MaxSteps”,options.MaxStepsPerEpisode);经验= sim (env,代理,simOpts);