创建自定义网格世界环境
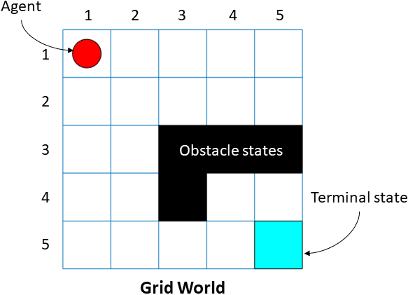
网格世界是一个二维的、基于单元的环境,在这个环境中,代理从一个单元开始,向终端单元移动,同时收集尽可能多的奖励。网格世界环境有助于应用强化学习算法,为网格上的代理发现最优路径和策略,以最少的移动达到最终目标。
强化学习工具箱™ 用于创建自定义MATLAB®您自己的应用程序的网格世界环境。创建一个自定义网格世界环境:
创建网格世界模型。
配置网格世界模型。
使用网格世界模型创建您自己的网格世界环境。
网格世界模型
可以使用创建自己的栅格世界模型createGridWorld作用创建网格时指定网格大小网格世界模型对象。
这个网格世界对象具有以下属性。
| 所有物 | 只读 | 描述 | ||||||
|---|---|---|---|---|---|---|---|---|
网格大小 |
对 | 栅格世界的尺寸,显示为M-借-N数组,这里,M表示网格行数和N是网格列的数目。 |
||||||
当前状态 |
没有 | 代理的当前状态的名称,以字符串形式指定。可以使用此属性设置代理的初始状态。代理总是从单元开始 代理从 |
||||||
州 |
对 | 包含网格世界状态名称的字符串向量。例如,对于2×2栅格世界模型 GW.国家=["[1,1]";"[2,1]";"[1,2]";"[2,2]"]; |
||||||
行动 |
对 | 包含代理可以使用的可能操作列表的字符串向量。可以在创建栅格世界模型时使用 GW=createGridWorld(m,n,移动) 具体说明
|
||||||
T |
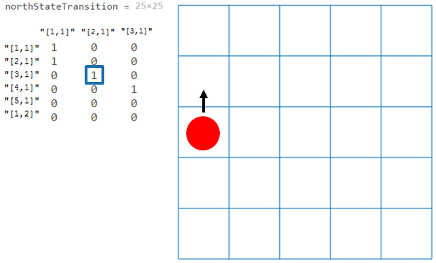
没有 | 状态转移矩阵,指定为三维数组。
例如,考虑一个5×5确定的网格世界对象 NorthStateTransformation=GW.T(:,:,1)
从上图可以看出 |
||||||
R |
没有 | 奖励转移矩阵,指定为三维数组。 报酬转移矩阵
设置 |
||||||
ObstacleStates |
没有 |
黑色单元格是障碍状态,您可以使用以下语法指定它们: GW。ObstacleStates = [“[3 3]”;"[3,4]";"[3,5]";"[4,3]"]; 有关工作流示例,请参见在基本网格世界中训练强化学习代理. |
||||||
TerminalStates |
没有 |
GW.TerminalStates=“[5,5]”; 有关工作流示例,请参见在基本网格世界中训练强化学习代理. |

网格世界环境
您可以使用创建马尔可夫决策过程(MDP)环境rlMDPEnv从上一步的网格世界模型。MDP是一个离散时间随机控制过程。它提供了一个数学框架,用于在结果部分随机和部分在决策者控制下的情况下建模决策。代理使用网格世界环境对象rlMDPEnv与栅格世界模型对象交互的步骤网格世界.
有关详细信息,请参阅rlMDPEnv和在基本网格世界中训练强化学习代理.
另见
createGridWorld|rlMDPEnv|rlPredefinedEnv
相关的话题
您还可以从以下列表中选择网站: