主要内容
rlMDPEnv
为强化学习创建马尔可夫决策过程环境
描述
马尔可夫决策过程(MDP)是一个离散时间随机控制过程。它提供了一个数学框架,用于在结果部分随机,部分受决策者控制的情况下建模决策。MDP对于研究使用强化学习解决的优化问题非常有用。使用rlMDPEnv在MATLAB中创建强化学习的Markov决策过程环境®.
性质
目标函数
getActionInfo |
从强化学习环境或代理获取行动数据规范 |
获取观测信息 |
从强化学习环境或代理获取观察数据规范 |
模拟 |
在指定环境中模拟经过培训的强化学习代理 |
火车 |
在特定环境中培训强化学习代理 |
验证环境 |
验证自定义强化学习环境 |
例子
创建网格世界环境
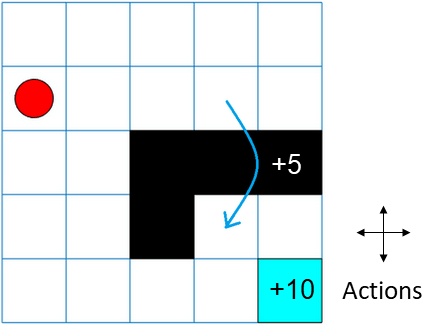
对于这个例子,考虑一个5×5网格世界,其规则如下:
以边界为界的五乘五网格世界,有4种可能的行动(北=1,南=2,东=3,西=4)。
代理从单元格[2,1](第二行,第一列)开始。
如果代理在单元格[5,5](蓝色)处达到终端状态,则该代理将获得+10奖励。
环境包含从[2,4]单元到[4,4]单元的特殊跳跃,奖励为+5。
该试剂被细胞[3,3]、[3,4]、[3,5]和[4,3](黑细胞)中的障碍物阻断。
所有其他行为将获得-1奖励。
首先,创建一个网格世界使用createGridWorld作用
GW=createGridWorld(5,5)
GW=GridWorld,属性为:GridSize:[5]CurrentState:[1,1]“状态:[25x1字符串]操作:[4x1字符串]T:[25x25x4双精度]R:[25x25x4双精度]障碍状态:[0x1字符串]终端状态:[0x1字符串]
现在,设置初始、终端和障碍物状态。
GW.CurrentState='[2,1]';GW.终端状态='[5,5]';GW.ObstacleStates=["[3,3]";"[3,4]";"[3,5]";"[4,3]"];
更新障碍状态的状态转移矩阵,并设置障碍状态的跳跃规则。
更新障碍物(GW)GW.T(状态2idx(GW,"[2,4]"),:,:)=0;GW.T(state2idx(GW,"[2,4]"),state2idx(GW,"[4,4]"),:) = 1;
接下来,在奖励转移矩阵中定义奖励。
nS=努美尔(吉瓦州);nA=努美尔(GW.行动);GW.R=-1*个(nS,nS,nA);GW.R(州2Idx(GW,"[2,4]"),state2idx(GW,"[4,4]"),:) = 5; GW.R(:,状态2Idx(GW,GW.终端状态),:)=10;
现在,使用rlMDPEnv使用创建网格世界环境的步骤网格世界对象吉瓦.
环境=rlMDPEnv(GW)
env=rlMDPEnv,属性为:模型:[1x1 rl.env.GridWorld]ResetFcn:[]
可以使用情节作用
地块(环境)

在R2019a中引入
您还可以从以下列表中选择网站: