TD3永磁同步电机控制剂的研制
本例演示了使用双延迟深度确定性策略梯度(TD3)代理对永磁同步电机(PMSM)进行速度控制。
本例的目标是展示在PMSM系统的速度控制中,可以使用强化学习作为线性控制器(如PID控制器)的替代方案。在线性区域之外,线性控制器通常不能产生良好的跟踪性能。在这种情况下,强化学习提供了一种非线性控制选择。
加载本例的参数。
sim_data
使用这两个中较低的Ld(内部变量)和这两个中较高的Lq(内部变量)进行计算。### ### Lq被观察到低于Ld。### ###使用这两个中较低的Ld(内部变量)和这两个中较高的Lq(内部变量)进行计算。###型号:'Maxon-645106' sn: '2295588' p: 7 Rs: 0.2930 Ld: 8.7678e-05 Lq: 7.7724e-05 Ke: 5.7835 J: 8.3500e-05 B: 7.0095e-05 I_rated: 7.2600 QEPSlits: 4096 N_base: 3476 N_max: 4300 FluxPM: 0.0046 T_rated: 0.3471 PositionOffset: 0.1650 model: 'BoostXL-DRV8305' sn: 'INV_XXXX' V_dc: 24 I_trip: 10 Rds_on: 0.0020 Rshunt: 0.0070 CtSensAOffset: 2295 CtSensBOffset: 2286 CtSensCOffset: 2295 ADCGain: 1 EnableLogic: 1 invertingAmp: 1 ISenseVref: 3.3000 ISenseVoltPerAmp: 0.0700 ISenseMax: 21.4286 R_board:0.0043 CtSensOffsetMax: 2500 CtSensOffsetMin: 1500 model: 'LAUNCHXL-F28379D' sn: '123456' CPU_frequency: 200000000 PWM_frequency: 5000 PWM_Counter_Period: 20000 ADC_Vref: 3 ADC_MaxCount: 4095 SCI_baud_rate: 12000000 V_base: 13.8564 I_base: 21.4286 N_base: 3476 T_base: 1.0249 P_base: 445.3845
打开Simulin万博1manbetxk模型。
mdl =“mcb_pmsm_foc_sim_RL”;open_system (mdl)
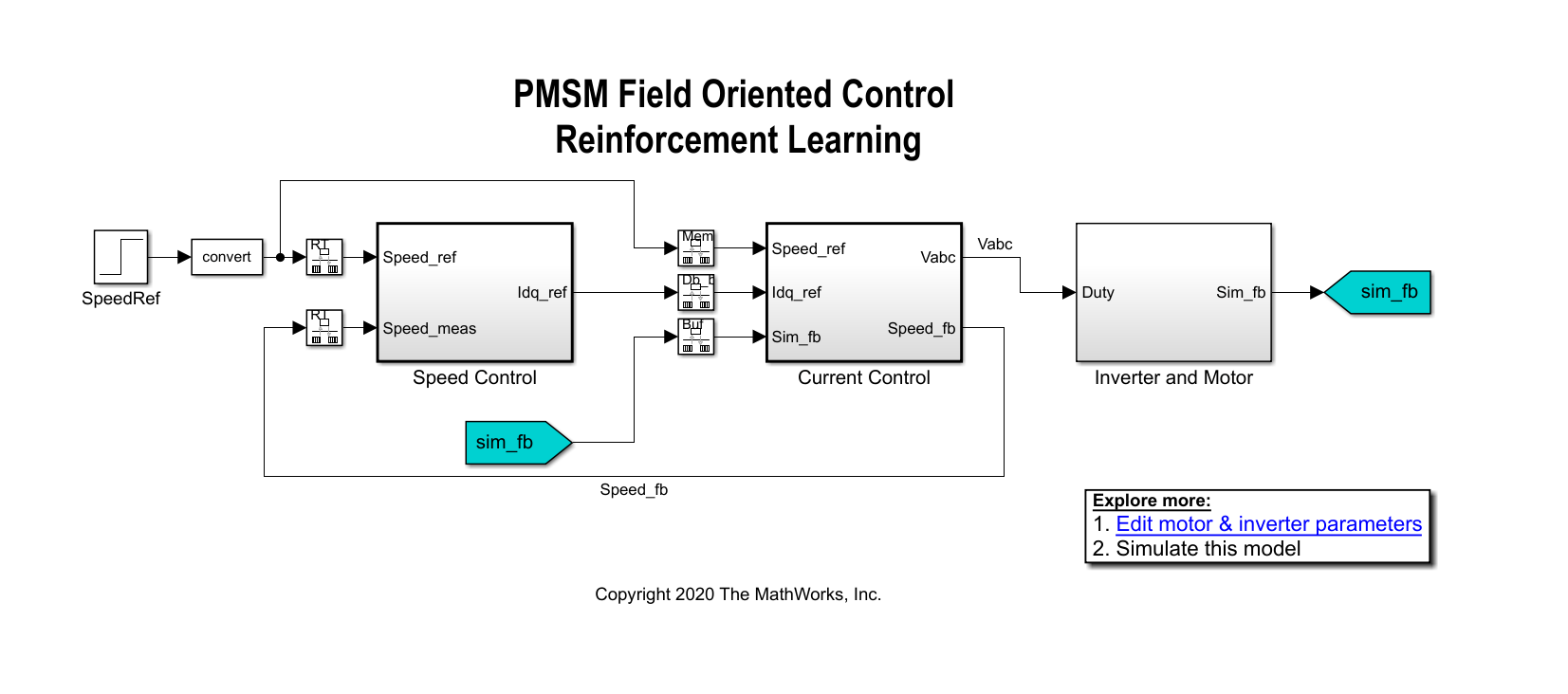
在此示例的线性控制版本中,可以在速度和电流控制环中使用PI控制器。一个外环PI控制器可以控制速度,两个内环PI控制器控制d轴和q轴电流。总体目标是跟踪参考速度中的Speed_Ref信号。本例使用强化学习代理来控制内部控制回路中的电流,而PI控制器控制外部回路。
创建环境界面
本例中的环境由PMSM系统组成,不包括作为强化学习代理的内环电流控制器。要查看强化学习代理与环境之间的接口,请打开闭环控制子系统。
open_system ('mcb_pmsm_foc_sim_RL/电流控制/控制系统/闭环控制')

强化学习子系统包含一个RL代理方块,观察向量的创建,以及奖励的计算。
对于这种环境:
观测值为外环参考速度
Speed_ref,速度反馈Speed_fb, d轴和q轴电流和误差( , , 而且 )和误差积分。代理的动作就是电压
vd_rl而且vq_rl.代理的采样时间为2e-4秒。内环控制与外环控制发生在不同的采样时间。
模拟运行5000个时间步,除非在 信号在1处饱和。
每个时间步的奖励为:
在这里, , 是常数, 为d轴电流误差, 为q轴电流误差, 动作是否来自前一个时间步,和 在模拟提前终止时等于1的标志。
为环境创建观察和行动规范。有关创建连续规范的信息,请参见rlNumericSpec.
创建观察规范。numObservations = 8;observationInfo = rlNumericSpec([numObservations 1],“数据类型”、数据类型);observationInfo。Name =“观察”;observationInfo。描述=关于误差和参考信号的信息;创建动作规格。numActions = 2;actionInfo = rlNumericSpec([numActions 1],“数据类型”、数据类型);actionInfo。Name =“vqdRef”;
使用观察和操作规范创建万博1manbetxSimulink环境接口。有关创建Simulink环境的更多信息,请参见万博1manbetxrl万博1manbetxSimulinkEnv.
agentblk =“mcb_pmsm_foc_sim_RL/电流控制/控制系统/闭环控制/强化学习/RL代理”;env = rl万博1manbetxSimulinkEnv(mdl,agentblk,observationInfo,actionInfo);
属性为此环境提供重置功能ResetFcn参数。在每一期训练开始时,resetPMSM函数中随机初始化参考速度的最终值SpeedRef阻塞到695.4 RPM (0.2 pu), 1390.8 RPM (0.4 pu), 2086.2 RPM (0.6 pu),或2781.6 RPM (0.8 pu)。
env。ResetFcn = @resetPMSM;
创建代理
本例中使用的代理是双延迟深度确定性策略梯度(TD3)代理。TD3代理在观察和行动的前提下,使用两个批评来近似长期奖励。有关TD3制剂的更多信息,请参见双延迟深度确定性策略梯度代理.
要创建评论,首先创建一个具有两个输入(观察和行动)和一个输出的深度神经网络。有关创建值函数表示的详细信息,请参见创建策略和值函数.
rng (0)%固定随机种子statePath = [featureInputLayer(numObservations,“归一化”,“没有”,“名字”,“状态”) fullyConnectedLayer (64,“名字”,“fc1”));actionPath = [featureInputLayer(numActions,“归一化”,“没有”,“名字”,“行动”) fullyConnectedLayer (64,“名字”,“取得”));commonPath = [addtionlayer (2,“名字”,“添加”) reluLayer (“名字”,“relu2”) fullyConnectedLayer (32,“名字”,“一个fc3”文件) reluLayer (“名字”,“relu3”) fullyConnectedLayer (16“名字”,“fc4”) fullyConnectedLayer (1,“名字”,“CriticOutput”));criticNetwork = layerGraph();criticNetwork = addLayers(criticNetwork,statePath);criticNetwork = addLayers(criticNetwork,actionPath);criticNetwork = addLayers(criticNetwork,commonPath);临界网络= connectLayers(临界网络,“fc1”,“添加/三机一体”);临界网络= connectLayers(临界网络,“取得”,“添加/ in2”);
使用指定的神经网络和选项创建评论家表示。您还必须为评论家指定操作和观察规范。有关更多信息,请参见rlQValueRepresentation.
criticOptions = rlRepresentationOptions(“LearnRate”1的军医,“GradientThreshold”1);critic1 = rlQValueRepresentation(criticNetwork,observationInfo,actionInfo,...“观察”, {“状态”},“行动”, {“行动”}, criticOptions);critic2 = rlQValueRepresentation(criticNetwork,observationInfo,actionInfo,...“观察”, {“状态”},“行动”, {“行动”}, criticOptions);
TD3代理根据使用参与者表示的观察结果决定采取何种操作。要创建演员,首先创建一个深度神经网络,并以类似于评论家的方式构建演员。有关更多信息,请参见rlDeterministicActorRepresentation.
actorNetwork = [featureInputLayer(numObservations,“归一化”,“没有”,“名字”,“状态”) fullyConnectedLayer (64,“名字”,“actorFC1”) reluLayer (“名字”,“relu1”) fullyConnectedLayer (32,“名字”,“actorFC2”) reluLayer (“名字”,“relu2”) fullyConnectedLayer (numActions“名字”,“行动”) tanhLayer (“名字”,“tanh1”));actorOptions = rlRepresentationOptions(“LearnRate”1 e - 3,“GradientThreshold”, 1“L2RegularizationFactor”, 0.001);actor = rlDeterministicActorRepresentation(actorNetwork,observationInfo,actionInfo,...“观察”, {“状态”},“行动”, {“tanh1”}, actorOptions);
要创建TD3代理,首先使用rlTD3AgentOptions对象。代理从最大容量2e6的经验缓冲区中随机选择大小为512的小批进行训练。使用0.995的折现因子来支持长期奖励。TD3代理人保留了演员和评论家的延时副本,称为目标演员和评论家.将目标配置为在训练期间每10个代理步骤更新一次,平滑因子为0.005。
Ts_agent = Ts;agentOptions = rlTD3AgentOptions(“SampleTime”Ts_agent,...“DiscountFactor”, 0.995,...“ExperienceBufferLength”2 e6,...“MiniBatchSize”, 512,...“NumStepsToLookAhead”, 1...“TargetSmoothFactor”, 0.005,...“TargetUpdateFrequency”10);
在训练过程中,智能体使用高斯动作噪声模型探索动作空间。属性设置噪声方差和衰减率ExplorationModel财产。噪声方差以2e-4的速率衰减,有利于训练初期的探索和后期的开发。有关噪声模型的更多信息,请参见rlTD3AgentOptions.
agentOptions.ExplorationModel.Variance = 0.05;agentOptions.ExplorationModel.VarianceDecayRate = 2e-4;agentOptions.ExplorationModel.VarianceMin = 0.001;
代理还使用高斯动作噪声模型来平滑目标策略更新。方法指定此模型的方差和衰减率TargetPolicySmoothModel财产。
agentOptions.TargetPolicySmoothModel.Variance = 0.1;agentoptions . targetpolicyysmoothmodel . variancedecayrate = 1e-4;
使用指定的参与者、评论家和选项创建代理。
agent = rlTD3Agent(actor,[critic1,critic2],agentOptions);
火车代理
要训练代理,首先指定使用的训练选项rlTrainingOptions.对于本例,使用以下选项。
每次训练不超过1000集,每集不超过1000集
装天花板(T / Ts_agent)时间的步骤。当智能体连续100次获得的平均累积奖励大于-190时停止训练。此时,代理可以跟踪参考速度。
T = 1.0;Maxepisodes = 1000;maxsteps = ceil(T/Ts_agent);trainingOpts = rlTrainingOptions(...“MaxEpisodes”maxepisodes,...“MaxStepsPerEpisode”maxsteps,...“StopTrainingCriteria”,“AverageReward”,...“StopTrainingValue”, -190,...“ScoreAveragingWindowLength”, 100);
培训代理使用火车函数。训练这个代理是一个计算密集型的过程,需要几分钟才能完成。为了在运行此示例时节省时间,请通过设置加载预训练的代理doTraining来假.要亲自训练特工,请设置doTraining来真正的.
doTraining = false;如果doTraining trainingStats = train(agent,env,trainingOpts);其他的负载(“rlPMSMAgent.mat”)结束
训练进度快照如下图所示。由于训练过程的随机性,你可以期待不同的结果。

模拟剂
为了验证训练后的智能体的性能,可以对模型进行仿真,并通过函数查看闭环性能速度跟踪范围块。
sim (mdl);
您还可以在不同的参考速度下模拟模型。中设置参考速度SpeedRef块到不同的值0.2和1.0之间的每个单位,并模拟模型再次。
set_param (“mcb_pmsm_foc_sim_RL / SpeedRef”,“后”,“0.6”) sim (mdl);
下图显示了闭环跟踪性能的示例。在这个模拟中,参考速度逐步通过695.4 rpm(每单位0.2)和1738.5 rpm (0.5 pu)的值。PI和强化学习控制器在0.5秒内跟踪参考信号的变化。
尽管该智能体被训练为跟踪每单位0.2的参考速度,而不是每单位0.5的参考速度,但它能够很好地泛化。

对应的电流跟踪性能如下图所示。探员追踪到了 而且 稳态误差小于2%的电流参考值。

另请参阅
相关的话题
您也可以从以下列表中选择一个网站: