Sbioparameterci.
计算估计参数的置信区间(需要)统计和机器学习工具箱)
描述
词=sbioparameterci(fitResults)fitResults一NLINResults对象或OptimResults对象返回的斯比奥菲特作用词是一个参数置信区间对象,该对象包含计算的置信区间。
词=sbioparameterci(fitResults,名称、值)名称、值对论点。
例子
计算估算PK参数和模型预测的置信区间
加载数据
加载样本数据以适应。数据存储为带有变量的表身份证件,时间,中央数控和外围设备.该合成数据表示在输注剂量为三个个体后在八个不同时间点测量的血浆浓度的时间过程。
清楚的全部的负载data10_32r.mat.gdata = groupeddata(数据);gdata.properties.varifeUldeUnits = {'',“小时”,“毫克/升”,“毫克/升”}斯比奥特雷利斯(格达塔,“身份证”,“时间”,{“CentralConc”,“PeripheralConc”},“标记”,'+',...'linestyle',“没有”);

创建模型
创建一个两室模型。
pkmd=PKModelDesign;pkc1=添加隔间(pkmd,“中央”);pkc1.DosingType=“输液”;pkc1.清除类型=“线性间隙”;pkc1。HA.sResponseVariable = true; pkc2 = addCompartment(pkmd,“外围设备”);模型=构造(PKMD);configset = getConfigset(型号);configset.compileOptions.unitConversion = true;
定义剂量
确定输液剂量。
剂量=sbiodose('剂量','targetname','药物_Central'); dose.StartTime=0;剂量.量=100;剂量率=50;剂量单位='毫克';剂量时间单位=“小时”;剂量率单位=“毫克/小时”;
定义参数
定义要估计的参数。为每个参数设置参数边界。除了这些显式边界外,参数转换(如log、logit或probit)还施加隐式边界。
响应映射={'taxCentral = CentralConc',“药物外设=外设浓度”};paramstoestimate = {'日志(中央)',的日志(外围),“12”,‘中央图书馆’}; estimatedParam=estimatedInfo(参数估计,...'初始值',[1 1 1 1],...'界限',[0.1 3;0.1 10;0 10;0.1 2];
适合模型
执行未加工的拟合,即每个患者的一组估计参数。
unpooledFit = sbiofit(模型、gData responseMap estimatedParam,剂量,“汇集”,假);
执行一个集合拟合,即对所有患者进行一组估计参数。
pooledfit = sbiofit(模型,gdata,respectemap,估计仙人,剂量,“汇集”,真正的);
计算估计参数的置信区间
计算非制冷拟合中每个估计参数的95%置信区间。
ciparamunpooled = sbioparameterci(undooledfit);
显示结果
以表格格式显示置信区间。有关每个估计状态含义的详细信息,请参阅参数置信区间估计状态.
CI2表(未冷却的CIP)
1.7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7表表表表表表表表表表表表表表表表表表表表表表表表表表名称估计名称估计估计估计估计估计估计估计估计估计估计估计估计量量量量量量估计量估计量估计量估计量估计量估计量(1 1 1 1 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7表表表表表表表表表表表表表表表表表表{'Q12'}1.5629 0.83143 2.3551高斯0.05约束1{'Q12'}0.47159 0.20093 0.80247高斯0.05约束1{'Cl_Central'}0.52898 0.44842 0.60955高斯0.05可估计2{'Central'}1.8322 1.7893 1.8751高斯0.05成功2{'Peripheral'}5.3368 3.9133 6.7602高斯0.05成功2{'Q12'}0.27641 0.2093 0.34351高斯0.05成功2{'Cl_Central'}0.86034 0.80313 0.91755高斯0.05成功3{'Central'}1.6657 1.5818 1.7497高斯0.05成功3{'Peripheral'}5.5632 4.7557 6.3708高斯0.05成功3{'Q12'}0.78361 0.65581 0.91142高斯0.05成功3{'Cl_Central'}1.0233 0.96375 1.0828高斯0.05成功
绘制置信区间。如果置信区间的估计状态为成功,它被绘制成蓝色(第一种默认颜色)。否则,它将被绘制成红色(第二种默认颜色),这表明可能需要进一步研究拟合参数。若置信区间为难能可贵,然后该函数绘制一条带中心十字的红线。如果有任何转换参数的估计值为0(对于对数变换)和1或0(对于probit或logit变换),则不会绘制这些参数估计值的置信区间。要查看颜色顺序,请键入获取(groot,'defaultaxescolorder').
组从左到右的显示顺序与它们在列表中的显示顺序相同groupname对象的属性,用于标记x轴。y标签是转换后的参数名称。
情节(Ciparamunpooled)

计算集合拟合的置信区间。
CiParamPoolled=sbioparameterci(pooledFit);
显示置信区间。
CI2表格(合并)
4.7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7 7表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表表池{'Peripheral'}2.687 0.89848 4.8323高斯0.05约束池{'Q12'}0.44956 0.11445 0.85152高斯0.05约束池{'Cl_Central'}0.78493 0.59222 0.97764高斯0.05可估计
绘制置信区间。组名被标记为“pooled”,以表明这种匹配。
情节(ciParamPooled)

将所有置信区间结果绘制在一起。缺省情况下,每个参数估计的置信区间绘制在单独的轴上。垂直线组群体的置于参数估计的置信区间以共同拟合计算。
ciAll=[CiParamUnpololed;CiParamPoolled];绘图(ciAll)

您还可以使用“分组”布局,在一个轴上按参数估计值分组绘制所有置信区间。
情节,“布局”,“分组”)

在此布局中,您可以指向每个置信区间的中心标记,以查看组名。每个估计的参数由垂直黑线分开。垂直虚线群体的参数估计的置信区间,其在共同拟合中计算。原始拟合中定义的参数界限由方括号标记。注意由于参数变换导致的y轴上的不同尺度。例如,Y轴的12个在线性范围内,但中央是对数尺度的,因为它是对数变换。
计算模型预测的置信区间
计算模型预测的95%置信区间,即使用估计参数的模拟结果。
%为了合身CipredPoolled=sbiopredictionci(pooledFit);%为非制冷的适合ciPredUnpooled = sbiopredictionci (unpooledFit);
绘制模型预测的置信区间
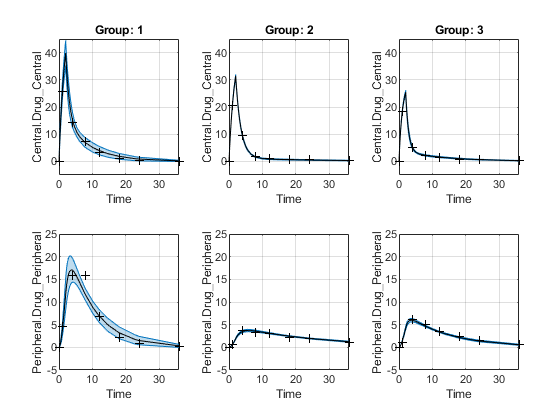
每个组的置信区间在单独的列中绘制,并且每个响应被绘制在单独的行中。受面临限制的置信区间以红色绘制。不受边界限制的置信区间以蓝色绘制。
情节(Cipredpooled)

情节(ciPredUnpooled)
输入参数
输出参数
更多关于
工具书类
[1]沃尔德,A。“关于观察人数大的几个参数的统计假设的测试。”美国数学学会学报.(3), 2003, pp. 426-482。
[2] 有界参数的调整置信区间行为遗传学第42(6)条,2012年,第886-898页。
[3] 检验复合假设的似然比的大样本分布数学统计数据.9(1),1938年,第60-62页。
扩展功能
在R2017b中引入
您还可以从以下列表中选择网站: