resubloss.
重新提交分类损失
描述
例子
输入参数
更多关于
分类损失
分类损失函数测量分类模型的预测不准确性。当你在许多模型中比较同一类型的损失时,损失越低表明预测模型越好。
考虑以下场景。
L.是加权平均分类损失。
N是样本大小。
二进制分类:
yj是被观察的类标签。软件将其编码为-1或1,表示负类或正类(或中第一类或第二类)
Classnames.分别属性)。F(Xj)为观察(行)的阳性分类评分j预测数据的X.
mj=yjF(Xj)为分类观察的分类评分j进入对应的课程yj.正值mj表明正确的分类,对平均损失贡献不大。负的mj指出错误的分类,并对平均损失有很大的贡献。
对于支持多类分类的算法(即,万博1manbetxK.≥3):
yj*是向量K.- 1个零,1在对应于真实的,观察类的位置yj.例如,如果第二个观察的真正类是第三类和K.= 4, 然后y2*= [0 0 1 0]'.类的顺序对应于
Classnames.输入模型的属性。F(Xj)为长度K.用于观察的班级分数向量j预测数据的X.分数的顺序与表中班级的顺序相对应
Classnames.输入模型的属性。mj=yj*'F(Xj).因此,mj是模型对真实的、观察到的类所预测的标量分类分数。
观察的重量j是W.j.该软件将观察权重标准化,使得它们总和到相应的先前类概率。该软件还规范化了现有概率,因此它们总和为1.因此,
给定此场景,下表描述了支持的损失函数,可以使用万博1manbetx“LossFun”名称值对参数。
| 损失函数 | 的价值LossFun |
方程 |
|---|---|---|
| 二项异常 | 'binodeviance' |
|
| 十进制错误分类率 | “classiferror” |
是与具有最大分数的类对应的类标签。一世{·}是指示函数。 |
| 叉损失 | “crossentropy” |
加权交叉熵损失是
的权重 被标准化为总和N而不是1。 |
| 指数损失 | “指数” |
|
| 铰链的损失 | “枢纽” |
|
| Logit损失 | 'logit' |
|
| 最小的误分类成本 | 'Mincost' |
该软件计算加权最小期望分类成本使用这一程序的观察j= 1,…,N.
最小期望误分类代价损失的加权平均值为
如果使用默认成本矩阵(其元素值为0对于正确分类和1个不正确的分类),则 |
| 二次损失 | “二次” |
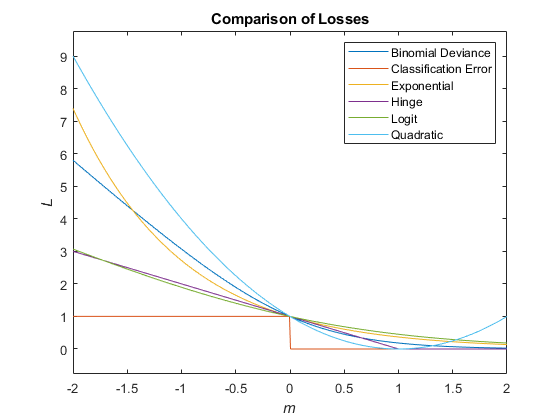
这个数字比较的损失函数(除了“crossentropy”和'Mincost'超过分数m一个观察。一些函数被归一化通过点(0,1)。
算法
resubloss.根据对应的值计算分类损失损失对象的功能(Mdl).对于特定于模型的描述,请参阅损失函数参考页下表。
| 模型 | 分类模型对象(Mdl) |
损失目标函数 |
|---|---|---|
| 广义添加剂模型 | ClassificationGAM |
损失 |
| K.最近的邻居模型 | ClassificationKNN |
损失 |
| 朴素贝叶斯模型 | ClassificationNaiveBayes |
损失 |
| 神经网络模型 | ClassificationneuralKetwork. |
损失 |
| 万博1manbetx支持向量机的一类和二值分类 | ClassificationSVM |
损失 |
扩展功能
也可以看看
你也可以从以下列表中选择一个网站:
