主要内容
拟合非参数分布的帕累托尾
此示例显示如何使用Pareto Teats将非参数概率分布适合对数据进行采样,以平滑尾部的分布。
步骤1。生成样本数据。
生成包含更多异常的异常值的示例数据,从标准正态分布中预期。
rng (“默认”)%的再现性left_tail = -exprnd(1,10,1);Right_tail = Exprnd(5,10,1);中心= Randn(80,1);data = [left_tail;中心; right_tail];
数据包含标准正态分布的80%值,从指数分布的均值为5%,均值为-1的指数分布,10%。与标准的正态分布相比,指数值更可能是异常值,特别是在上部尾部。
步骤2.适用于数据的概率分布。
适合正态分布和一个T.将数据按位置比例尺分布,并绘制图进行直观比较。
probplot(数据);p = fitdist(数据,'tlocationscale');h = probplot(gca,p);套(H,'颜色'那'r'那'linestyle'那' - ');标题(“概率图”) 传奇('普通的'那“数据”那't位置级'那“位置”那'se')
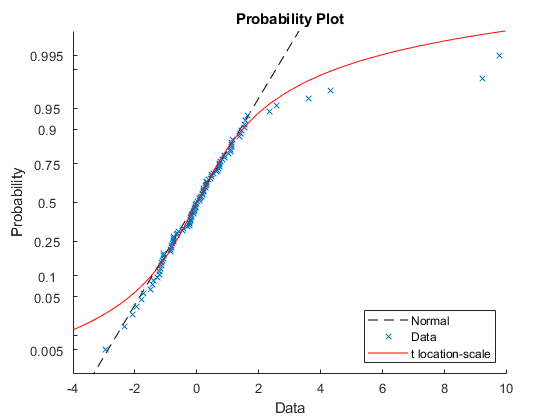
两种分布似乎都在中心位置吻合得很好,但无论是正态分布还是T.位置级分配非常适合尾部。
步骤3.生成经验分布。
获得更好的合适,使用ecdf.基于样本数据生成经验CDF。
图ecdf(数据)
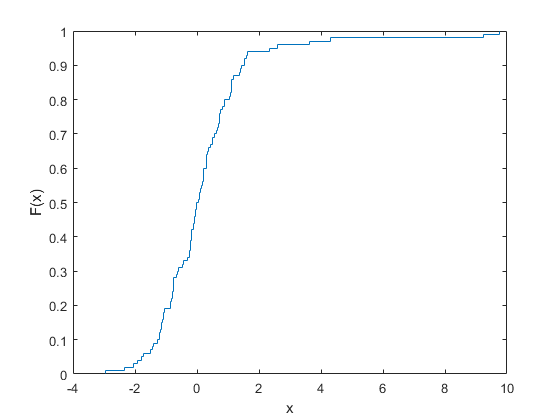
实证分布提供了完美的契合,但异常值使尾部非常离散。使用反转方法的来自该分布产生的随机样本可以包括例如近4.33和9.25附近的值,但之间没有值。
步骤4.使用帕累托尾部配合分布。
用Paretotails.为了为中间80%的数据产生经验CDF,并将广义帕吻曲面分布到下10%。
pfit = paretotails(数据,0.1,0.9)
pfit =分段分布与3段负无穷到< x < -1.24623 (0 < p < 0.1):低尾巴,加仑日(-0.334156,0.798745)-1.24623 < x < 1.48551 (0.1 < p < 0.9):插值经验提供1.48551 < x <正(0.9 < p < 1):上尾巴,加仑日(1.23681,0.581868)
获得更好的合适,Paretotails.通过在样本中心拼接ECDF或内核分布,并在尾部中平滑通用帕匹官分布(GPDS)来拟合分布。用Paretotails.去创造Paretotails.概率分布对象。您可以访问有关适合的信息,并使用对象对对象进行进一步计算Paretotails.目的。例如,您可以评估CDF或从分发中生成随机数。
第5步。计算并绘制cdf。
计算并绘制安装的CDFParetotails.分配。
x = -4:0.01:10;plot(x,cdf(pfit,x))
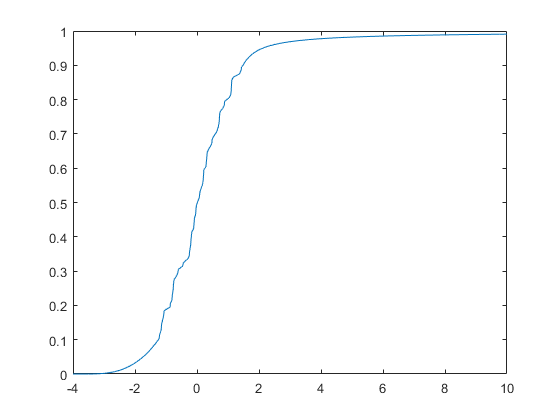
这Paretotails.CDF与数据密切合适,但在尾部比在步骤3中产生的ECDF更平滑。
也可以看看
相关的话题
您还可以从以下列表中选择一个网站:
