非参数和经验概率分布
概述
在某些情况下,您无法使用参数分布准确地描述数据样本。相反,必须从数据估计概率密度函数(PDF)或累积分布函数(CDF)。统计和机器学习工具箱™提供了几种选项,用于从样本数据估计PDF或CDF。
内核分布
一种内核分布生成一个非参数概率密度估计,使其适应数据,而不是选择一个具有特定参数形式的密度并估计参数。该分布由核密度估计器定义,平滑函数决定用于生成pdf的曲线形状,以及控制生成的密度曲线的平滑度的带宽值。
与直方图类似,核分布利用样本数据构建一个函数来表示概率分布。但与直方图不同的是,直方图将值放入离散的箱子中,核分布对每个数据值的分量平滑函数进行求和,从而产生一个平滑的、连续的概率曲线。下图显示了由同一样本数据生成的直方图和核分布的可视化比较。
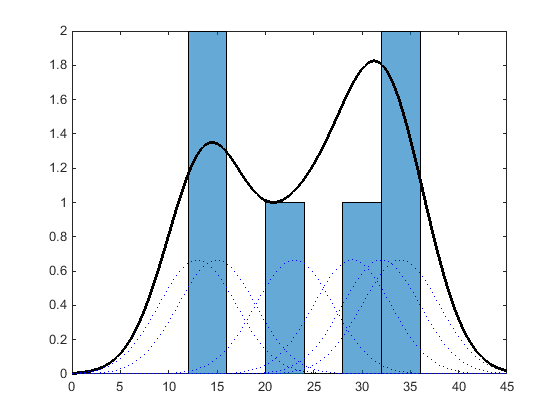
直方图代表通过建立箱并将每个数据值放置在适当的箱中来表示概率分布。由于该箱数量方法,直方图产生离散概率密度函数。这可能不适合某些应用程序,例如从拟合分布生成随机数。
或者,内核分布通过为每个数据值创建单独的概率密度曲线来构建概率密度函数(PDF),然后求解平滑曲线。该方法为数据集创建一个平滑,连续的概率密度函数。
有关内核发行版的更多通用信息,请参见内核分布.有关如何使用内核发行版的信息,请参见使用KernelDistribution对象和ksdensity.
经验累积分布函数
经验累积分配功能(ecdf)通过对样本中的每种观察分配相同的概率来估计随机变量的CDF。由于这种方法,ECDF是一种离散的累积分布函数,可以在ECDF和样本数据的分布之间创建精确匹配。
以下绘图显示了由标准正态分布产生的20个随机数的ECDF的视觉比较,以及标准正态分布的理论CDF。圆圈表示在每个样本数据点计算的ECDF的值。通过每个圆脉通过每个圆的虚线表示ECDF,尽管ECDF不是连续功能。实线显示了标准正态分布的理论CDF,其中绘制了样本数据中的随机数。
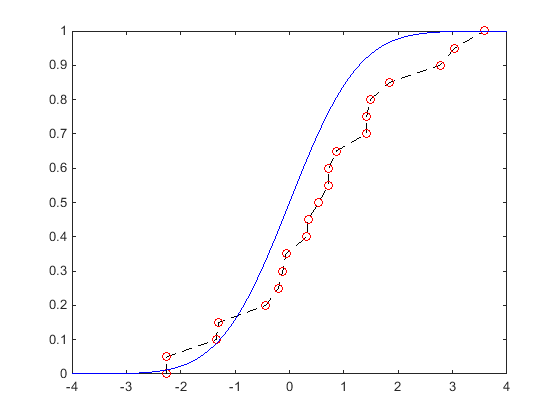
ecdf在形状上与理论的cdf相似,尽管它不是完全匹配的。相反,ecdf与示例数据是完全匹配的。ecdf是一个离散函数,并且不是平滑的,特别是在数据稀疏的尾部。你可以平滑分发帕累托尾巴, 使用Paretotails.功能。
分段线性分布
一种分段线性分布通过计算每个单独点的CDF值来估计样本数据的整体CDF,然后将这些值线性连接成一条连续的曲线。
以下绘图显示了基于医院患者重量测量的样本的分段线性分布的CDF。圆圈代表每个单独的数据点(重量测量)。通过每个数据点的黑线表示样本数据的分段线性分配CDF。
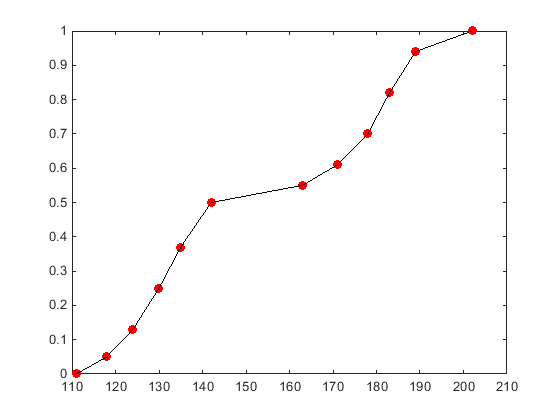
一个分段线性分布线性连接的cdf值计算在每个样本数据点,形成一个连续的曲线。相比之下,一个经验累积分布函数建造使用ecdf函数产生一个离散的cdf。例如,由ecdf生成的随机数只能包含X值包含在原始样本数据中。由分段线性分布产生的随机数可以包括任何X样本数据的较低边界之间的值。
因为分段线性分配CDF由样本数据中包含的值构成,所以得到的曲线通常不流畅,尤其是数据可能稀疏的尾部。你可以平滑分发帕累托尾巴, 使用Paretotails.功能。
有关如何处理分段线性分布的信息,请参见使用PiecewiseLinearDistribution对象。
帕累托尾巴
帕累托尾部使用一种分段的方法,通过平滑分布的尾部来改善非参数cdf的拟合。你可以装下内核分布那经验提供或者用户定义的估计器到中间数据值,然后适合广义帕累托分布曲线到尾巴。当样品数据在尾部稀疏时,该技术特别有用。
以下绘图显示了包含20个随机数的数据样本的经验CDF(ECDF)。实线代表ECDF,虚线表示具有Pareto尾部的经验CDF,适用于数据的下部和高度。圆圈表示数据的下层和较高的数据的边界。
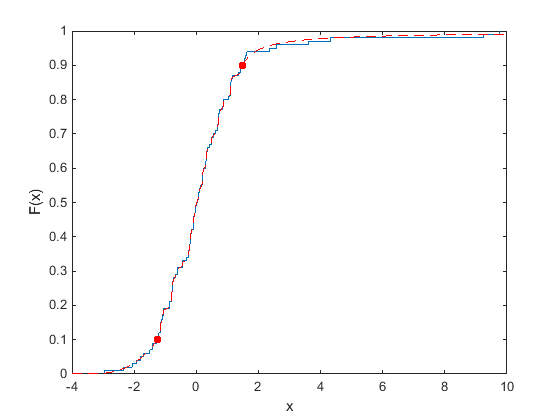
将帕累托尾部拟合到样本数据的上下10%,使得尾部的cdf更平滑,因为尾部的数据是稀疏的。有关使用帕累托尾的更多信息,请参见Paretotails..
三角分布
一种三角分布提供了当有限样本数据可用时的概率分布的简单表示。这个连续分布由下限、峰值位置和上限参数化。这些点是线性连接,以估计pdf的样本数据。您可以使用数据的平均值、中值或模式作为峰值位置。
下图显示了从0到5的10个整数的随机样本的三角形分布pdf。下限为样本数据中最小的整数,上限为最大的整数。该图的峰值位于样本数据中的模态,或最常出现的值。
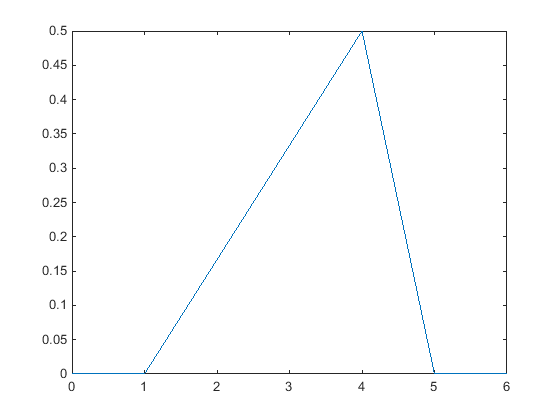
当样本数据有限时,模拟和项目管理等业务应用程序有时会使用三角分布来创建模型。有关更多信息,请参见三角分布.
也可以看看
相关的话题
你也可以从以下列表中选择一个网站:
