使用灵活的分布族生成数据
这个示例展示了如何使用Pearson和Johnson分布系统生成数据。
皮尔逊和约翰逊系统公司
中描述的使用概率分布,选择一个合适的参数分布家族来建模您的数据可以基于先天的或后验了解数据生成过程,但选择往往很困难。的皮尔逊-约翰逊系统可以使这样的选择变得不必要。每个系统都是一个灵活的参数分布家族,其中包括各种分布形状,通常可以在这两个系统中找到与您的数据很匹配的分布。
数据输入
下面的参数定义了Pearson和Johnson系统的每个成员。
这些统计数据也可以用时刻函数。Johnson系统基于这四个参数,更自然地使用分位数来描述,由分位数函数。
的pearsrnd和johnsrnd函数接受定义分布的输入参数(分别是参数或分位数),并返回相应系统中分布的类型和系数。这两个函数也从指定的分布生成随机数。
例如,加载数据carbig.mat,其中包含一个变量英里/加仑包含每辆车的汽油里程数。
负载carbig英里/加仑= MPG (~ isnan (MPG));直方图(MPG, 15)
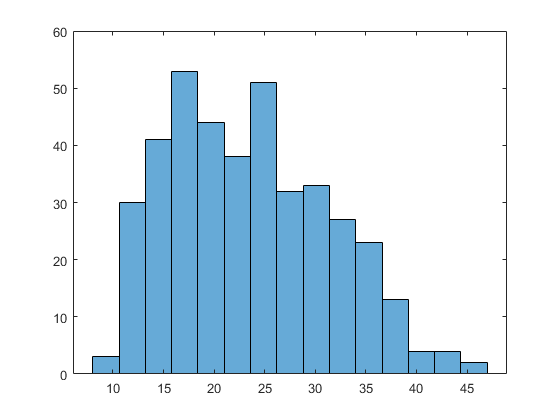
下面两部分分别用Pearson和Johnson系统的成员模拟分布。
使用皮尔逊系统生成数据
统计学家卡尔·皮尔森(Karl Pearson)设计了一个分布系统,或称分布家族,其中包括一个独特的分布,对应于均值、标准差、偏度和峰度的每一个有效组合。如果从数据中计算每个矩的样本值,就很容易在皮尔逊系统中找到匹配这四个矩的分布,并生成一个随机样本。
皮尔逊系统将七种基本分布类型嵌入到一个单一的参数框架中。它包括常见的分布,如正态分布和 分布,标准分布的简单变换,如移位和缩放的分布和逆分布,还有一种分布,iv型,它不是任何标准分布的简单变换。
对于给定的一组力矩,有一些不在系统中的分布也有相同的前四个力矩,皮尔逊系统中的分布可能与你的数据不太匹配,特别是当数据是多峰的时候。但该系统确实涵盖了广泛的分布形状,包括对称分布和偏态分布。
从皮尔逊分布中生成一个与英里/加仑数据,简单计算四个样本矩,并将其作为分布参数。
时刻= {(MPG),性病(MPG),偏态(MPG),峰度(MPG)};rng (“默认”)%的再现性[r,类型]= pearsrnd(10000年时刻{:},1);
的可选的第二个输出pearsrnd指出皮尔逊系统中哪一种分布与矩的组合相匹配。
类型
类型= 1
在这种情况下,pearsrnd已经确定数据最好用I型皮尔逊分布来描述,这是一个移位的、缩放的beta分布。
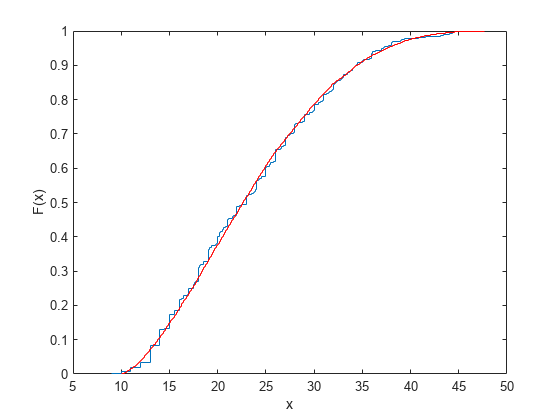
通过叠加经验累积分布函数,验证样本与原始数据相似。
ecdf (MPG);[Fi, xi] = ecdf (r);持有在;楼梯(xi, Fi,“r”);持有从
使用Johnson系统生成数据
统计学家诺曼·约翰逊(Norman Johnson)设计了一个不同的分布系统,其中还包括一个独特的分布,适用于均值、标准差、偏度和峰度的每一个有效组合。然而,由于使用分位数描述Johnson系统中的分布更为自然,因此使用该系统与使用Pearson系统是不同的。
约翰逊系统是基于一个正态随机变量的三个可能的变换,加上恒等变换。这三种非平凡的情况被称为SL,苏,某人,对应于指数、logistic和双曲正弦变换。这三个都可以写成
在哪里
是一个标准正态随机变量,
是转型,和
,
,
,
为规模和位置参数。第四个病例,SN,是恒等变换。
从约翰逊分布中生成一个样本来匹配英里/加仑数据,首先定义四个分位数,对-1.5、-0.5、0.5、1.5这四个均匀间隔的标准正态分位数进行转换。也就是说,计算累积概率为0.067、0.309、0.691和0.933的数据的样本分位数。
Probs = normcdf([-1.5 -0.5 0.5 1.5])
聚合氯化铝=1×40.0668 0.3085 0.6915 0.9332
分位数=分位数(MPG,聚合氯化铝)
分位数=1×413.0000 18.0000 27.2000 36.0000
然后将这些分位数视为分布参数。
(r1、类型)= johnsrnd(分位数,10000年,1);
的可选的第二个输出johnsrnd指示Johnson系统中的哪种分布类型匹配分位数。
类型
类型=“某人”
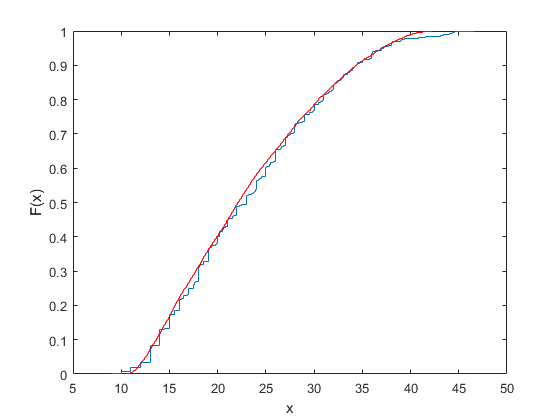
您可以通过叠加经验累积分布函数来验证该样本与原始数据相似。
ecdf (MPG);[Fi, xi] = ecdf (r1);持有在;楼梯(xi, Fi,“r”);持有从
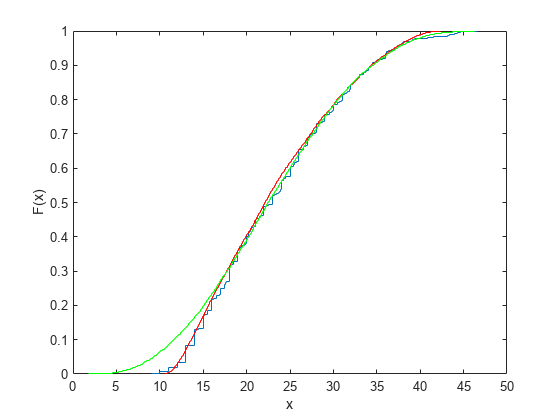
在某些应用程序中,在数据的某些区域更好地匹配分位数可能很重要。为此,您需要指定四个间隔均匀的标准正规分位数来匹配数据,而不是默认的-1.5、-0.5、0.5和1.5。例如,您可能更关心匹配右侧尾部的数据而不是左侧尾部的数据,因此您指定了强调右侧尾部的标准正规分位数。
qnorm =(-。5.25 1 1.75];聚合氯化铝= normcdf (qnorm);qemp =分位数(MPG,聚合氯化铝);r2 = johnsrnd ([qnorm;qemp), 10000, (1);
然而,虽然新样本在右尾部与原始数据匹配得更好,但在左尾部匹配得更差。
[Fj, xj] = ecdf (r2);持有在;楼梯(Fj xj,‘g’);持有从
另请参阅
你也可以从以下列表中选择一个网站:
