grpstats
汇总统计按组安排
句法
描述
statarray= grpstats (TBL,组变量)TBL由分组变量的中指定的值或变量确定组变量。
如果只有一个分组变量,则有一排
statarray对于分组变量的每个值。grpstats通过出现的顺序进行排序的组(如果分组变量是一个字符向量或标量串),在上升的数字顺序(如果该分组变量是数字),或在水平的订单(如果分组变量是分类)。如果
组变量是一个字符串数组或包含多个分组的变量名,或列数的向量字符向量的单元阵列,然后有一排statarray对于每个观测到的分组变量值的唯一组合。grpstats排序由所述第一分组变量的值,则该第二分组的变量,等等的基团。如果任何变量
TBL(比在规定的其他组变量)不是数字或逻辑数组,则必须使用名称-值对参数指定要计算的数字和逻辑变量的名称或列号,DataVars。
statarray= grpstats (TBL,组变量,whichstats)whichstats。
手段= grpstats (X,组)X由分组变量或变量的值来确定,组。的行手段对应的分组变量值。
如果只有一个分组变量,则有一排
手段对于分组变量的每个值。grpstats通过出现的顺序进行排序的组(如果分组变量是一个字符向量或标量串),在上升的数字顺序(如果该分组变量是数字),或在水平的订单(如果分组变量是分类)。如果
组是一个字符串数组或分组变量的单元阵列,然后有一排手段对于每个观测到的分组变量值的唯一组合。grpstats排序由所述第一分组变量的值,则该第二分组的变量,等等的基团。如果
X是一个矩阵,然后手段是具有相同的列数为一个矩阵X。的每一列手段具有用于相应的列的组的装置X。
[返回中指定的汇总统计类型的组值的列向量或数组stats1,…, statsN] = grpstats(X,组,whichstats)whichstats。
[规定了信心和预测区间的显着性水平。stats1,…, statsN] = grpstats(X,组,whichstats“阿尔法”,α)
例子
按组组织的数据集数组汇总统计信息
加载样本数据。
加载('医院')
数据集的数组医院有100个观测和7个变量。
创建仅变量的数据集阵列性别,年龄,重量,抽烟者。
DSA =医院(:,{'性别',“年龄”,“重量”,“吸烟者”});
性别是具有级别的名义数组吗男和女。的变量年龄和重量有数值,和抽烟者有逻辑值。
计算平均值的数字和逻辑阵列,年龄,重量,抽烟者,通过在水平分组性别。
statarray = grpstats (dsa),'性别')
statarray =性别GroupCount mean_Age mean_Weight mean_Smoker女女53 37.717 130.47 0.24528男男47 38.915 180.53 0.44681
statarray是一个数据集阵列具有两行,对应于水平性别。GroupCount是每个组中的观测值的数量。手段年龄,重量,抽烟者,通过分组性别,被给予平均年龄,mean_Weight,mean_Smoker。
计算的均值年龄和重量中的值分组抽烟者。
statarray = grpstats (dsa),“吸烟者”,“的意思是”,'DataVars'{“年龄”,“重量”})
statarray =吸烟者GroupCount mean_Age mean_Weight 0假66 37.97 149.91 1真34 38.882 161.94
在这种情况下,不是所有的变量DSA(不包括分组变量,抽烟者)是数字或逻辑阵列;变量性别是标称阵列。当输入数据集数组中不是所有的变量是数字或逻辑阵列,您必须指定您使用要计算汇总统计变量DataVars。
计算最小和最大重量,值的组合进行分组性别和抽烟者。
statarray = grpstats(DSA,{'性别',“吸烟者”},{“最小值”,“马克斯”},...'DataVars',“重量”)
statarray =性别吸烟者GroupCount min_Weight max_Weight Female_0女性假40 111 147 Female_1女真13 115 146 Male_0男性假26 158 194 Male_1男真21 164 202
有两个独特的值抽烟者和两个层次性别,总共的值的四种可能的组合:女性不吸烟者(Female_0),女性吸烟者(Female_1),男性非吸烟者(Male_0),与男性吸烟者(Male_1)。
指定输出列的名称。
statarray = grpstats(DSA,{'性别',“吸烟者”},{“最小值”,“马克斯”},...'DataVars',“重量”,'VarNames'{'性别',“吸烟者”,...'GroupCount','LowestWeight',“HighestWeight”})
性别吸烟组计数最低体重最高体重女性0女性假40 111 147女性1女性真13 115 146男性0男性假26 158 194男性1男性真21 164 202
汇总统计数据集阵列不进行分组
加载样本数据。
加载('医院')
数据集的数组医院有100个观测和7个变量。
创建仅变量的数据集阵列年龄,重量,抽烟者。
DSA =医院(:,{“年龄”,“重量”,“吸烟者”});
的变量年龄和重量有数值,和抽烟者有逻辑值。
计算的平均值,最小值和最大值的数值和逻辑阵列,年龄,重量,抽烟者,没有分组。
statarray = grpstats(DSA,[],{“的意思是”,“最小值”,“马克斯”})
statarray = GroupCount mean_Age MIN_AGE MAX_AGE mean_Weight所有100 38.28 25 50 154 min_Weight max_Weight mean_Smoker min_Smoker max_Smoker全部111 202 0.34假真
观察名所有表明所有的观测DSA被用来计算汇总统计。
组用于在矩阵使用一个或多个分组变量
加载样本数据。
加载('carsmall')
所有的变量都可供100辆汽车进行测量。起源原产地是每个汽车(法国,德国,意大利,日本,瑞典,美国或)的国家。气瓶有三个独特的价值观,4,6,8指示在每节车厢的气缸数。
计算平均值的加速度,由原籍国进行分组。
手段= grpstats(加速度,产地)
手段=6×114.4377 18.0500 15.8867 16.3778 16.6000 15.5000
手段是平均加速度的6×1向量,每个值对应一个原产国。
计算平均值的加速度,由产地和气缸数的两个国家进行分组。
手段= grpstats(加速度,{来源,气缸})
手段=10×117.0818 16.5267 11.6406 18.0500 15.9143 15.5000 16.3375 16.7000 16.6000 15.5000
有分组变量值,因为18个可能的组合起源具有6个唯一值和气瓶有3个独特的价值观。只有可能的组合10出现在数据,所以手段是对应于值的观察到的组合组装置的10×1向量。
返回组名称与各组的平均加速度一起。
[装置,GRPS] = grpstats(加速度,{来源,气缸},{“的意思是”,'的gname'})
手段=10×117.0818 16.5267 11.6406 18.0500 15.9143 15.5000 16.3375 16.7000 16.6000 15.5000
GRPS =10X2单元{'美国'}{‘4’}{‘美国’}{‘6’}{‘美国’}{' 8 '}{“法国”}{‘4’}{‘日本’}{‘4’}{‘日本’}{‘6’}{“德国”}{‘4’}{“德国”}{‘6’}{“瑞典”}{‘4’}{“意大利”}{' 4 '}
输出GRPS显示10个观察到的变量值分组组合。例如,法国生产的4缸汽车的平均加速度是18.05。
多个汇总统计矩阵有组织的集团
加载样本数据。
加载carsmall
变量加速度被测量为100辆汽车。变量起源原产地是每个汽车(法国,德国,意大利,日本,瑞典,美国或)的国家。
返回原籍国分组的最小和最大加速度。
[grpMin,grpMax,GRP] = grpstats(加速度,产地,{“最小值”,“马克斯”,'的gname'})
grpMin =6×18.0000 15.3000 13.9000 12.2000 15.7000 15.5000
grpMax =6×122.2000 21.9000 18.2000 24.6000 17.5000 15.5000
GRP =6x1的细胞{ 'USA'} { '法国'} { '日本'} { '德国'} { '瑞典'} { '意大利'}
加速度最低的样车是美国制造,加速度最高的样车是德国制造。
剧情预测区间为一个新的观察各组
加载样本数据。
加载('carsmall')
变量重量被测量为100辆汽车。变量Model_Year有三个独特的价值观,70,76,82,对应于模型1970年,1976年,和1982年。
计算每个车型年的平均重量和90%的预测区间。
(意味着,pred, grp) = grpstats(体重、Model_Year...{“的意思是”,“predci”,'的gname'},'Α',0.1);
情节误差线显示平均体重和90%的预测区间,在品牌年度区分。与组名称标记水平轴。
ngrps =长度(GRP);组的数量%errorbar((1:ngrps)”,手段,预解码值(:,2)-means)XLIM([0.5 3.5])组(GCA,'XTICK',1:ngrps,“xticklabel”,GRP)标题('90%的预测区间按年权重”)

区组手段和置信区间
加载样本数据。
加载('carsmall')
的变量加速度和重量是100辆汽车测量的加速度和权重值。变量气瓶在每节车厢的气缸数。变量Model_Year有三个独特的价值观,70,76,82,对应于模型1970年,1976年,和1982年。
绘制平均加速,通过分组气瓶,有95%的置信区间。
grpstats(加速度,缸,0.05)

ans =3×116.6706 16.4765 11.6406
对汽车的平均加速度与8个柱面比为4个或6缸汽车显著更低。
绘制平均加速度和重量,分组气瓶和95%置信区间。缩放重量由1000个值,以便手段重量和加速度是大小相同的顺序。
grpstats((加速度、重量/ 1000),缸,0.05)

ans =3×216.6706 2.3726 16.4765 3.1255 11.6406 3.9703
汽车的平均重量随气缸数的增加而增加,平均加速度随气缸数的增加而减少。
Plot平均加速,分组的两气瓶和Model_Year。指定95%的置信区间。
grpstats(加速度,{缸,Model_Year},0.05)
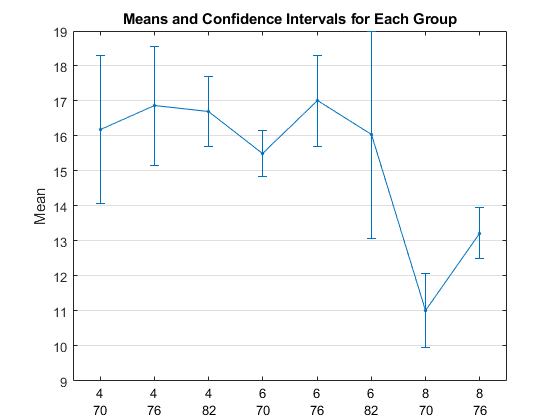
ans =8×116.1875 16.8667 16.7036 15.5000 17.0000 16.0333 11.0217 13.2222
有因为有三个独特值分组变量值9层可能的组合气瓶和三个唯一的值Model_Year。情节不显示与模型1982年8缸车,因为该数据不包括这一组合。
在1976年由8缸汽车的平均加速度大于在1970年由8缸汽车的平均加速度显著大。
输入参数
输出参数
算法
grpstats对待为NaNS作为缺失值,并计算概要统计之前,从所述输入数据中删除。grpstats忽略空组名称。
选择功能
MATLAB®包括函数groupsummary,这也将返回组总结,当你与表工作的建议。
扩展功能
之前介绍过的R2006a
您也可以从以下列表中选择网站:
