logp.
LDA模型的文件对数概率和拟合优度
语法
描述
例子
计算文档Log-Probabilities
要重现本例中的结果,请设置RNG.来'默认'.
RNG('默认')
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
使用袋式模型使用bagOfWords.
袋= bagOfWords(文档)
单词:[" fairrest " "creatures" "desire"…NumWords: 3092 NumDocuments: 154
拟合具有20个主题的LDA模型。要抑制verbose输出,请设置“详细”为0。
numTopics = 20;mdl = fitlda(袋、numTopics、“详细”,0);
计算培训文档的文档日志概率,并在直方图中显示它们。
logProbabilities = logp (mdl、文档);图直方图(logProbabilities)包含(“日志概率”)ylabel(“频率”)标题(“文档日志概率”)
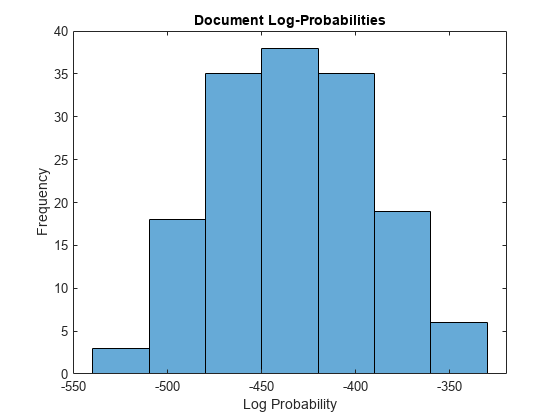
识别日志概率最低的三个文档。低日志概率可能表明该文档可能是一个异常值。
[~, idx] = (logProbabilities)进行排序;idx (1:3)
ans =3×1146年19日65年
文档(idx (1:3))
ans = 3x1 tokenizedDocument: 76 token:可怜的灵魂中心有罪的地球地球叛军力量数组为何你松遭受缺乏绘画外墙壁昂贵的同性恋为什么大量成本短期租赁你你衰落的豪宅花费蠕虫继承者过量吃了你的费用你发现最后的灵魂住在仆人的损失让松加重你商店买神出卖时间,用渣渣喂富,你会喂死吗?吞噬时间冲你狮子的爪子使地球吞噬自己的甜蜜育摘下敏锐的牙齿凶猛的老虎嘴燃烧longlivd凤凰血使高兴难过的季节你舰队只要你必swiftfooted宽世界褪色糖果禁止你十恶不赦的犯罪o雕刻你的小时喜欢公平的眉毛也画线你的古董笔你的课程无污点的允许beautys pattern succeeding men yet thy worst old time despite thy wrong love shall verse ever live young 73 tokens: brass nor stone nor earth nor boundless sea sad mortality oersways power rage shall beauty hold plea whose action stronger flower o shall summers honey breath hold against wrackful siege battering days rocks impregnable stout nor gates steel strong time decays o fearful meditation alack shall times best jewel times chest lie hid strong hand hold swift foot back spoil beauty forbid o none unless miracle might black ink love still shine bright
从单词计数矩阵计算文档日志概率
加载示例数据。sonnetscounts.mat包含一个字数矩阵和Precosencesed版本的Shakespeare Sonnets的相应词汇。
负载sonnetscounts.mat尺寸(计数)
ans =1×2154 3092
拟合具有20个主题的LDA模型。
numTopics = 20;numTopics mdl = fitlda(计数)
初始主题分配在0.2274秒内采样。===================================================================================== |迭代|每个时间|相对|训练|主题|主题||| iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.01 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.03 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.04 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.04 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.03 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.04 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.04 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl = ldaModel with properties: NumTopics: 20 WordConcentration: 1 TopicConcentration: 5 corpustopic概率:[0.0500 0.0500 0.0500 0.0500 0.0500…词汇:["1" "2" "3" "4" "5"…TopicOrder: 'initial-fit-probability'
计算培训文档的文档日志概率。指定为每个文档绘制500个样本。
numSamples = 500;logProbabilities = logp (mdl计数,...“NumSamples”, numSamples);
用直方图显示文档日志概率。
图直方图(logProbabilities)包含(“日志概率”)ylabel(“频率”)标题(“文档日志概率”)
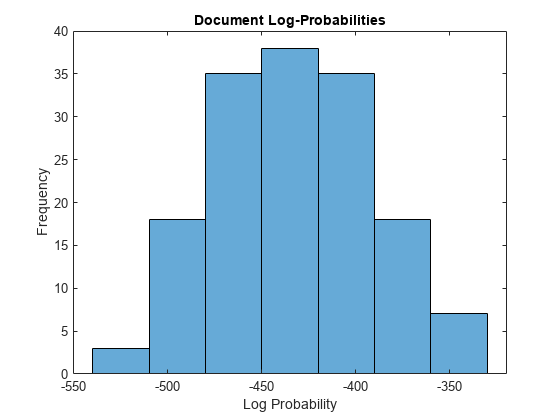
用最低的日志概率标识三个文档的索引。
[~, idx] = (logProbabilities)进行排序;idx (1:3)
ans =3×1146年19日65年
比较拟合优度
比较两个LDA模型的拟合优度,通过计算一个保留的测试文档集的复杂度。
要重现结果,请设置RNG.来'默认'.
RNG('默认')
加载示例数据。该文件sonnetsPreprocessed.txt包含了经过预处理的莎士比亚十四行诗。该文件每行包含一首十四行诗,单词之间用空格分隔。将文本从sonnetsPreprocessed.txt,将文本以换行符分割为文档,然后标记文档。
文件名=“sonnetsPreprocessed.txt”;str = extractFileText(文件名);textData =分裂(str,换行符);文件= tokenizedDocument (textData);
随机留出10%的文档用于测试。
numDocuments =元素个数(文件);本量利= cvpartition (numDocuments,“坚持”, 0.1);documentsTrain =文档(cvp.training);documentsTest =文档(cvp.test);
从培训文档创建一个单词袋式模型。
袋= bagOfWords (documentsTrain)
单词:[" fairmost " "creatures" "desire"…NumWords: 2909 NumDocuments: 139
将包含20个主题的LDA模型拟合到词袋模型中。要抑制verbose输出,请设置“详细”为0。
numTopics = 20;mdl1 = fitlda(袋子,numtopics,“详细”,0);
查看有关型号适合的信息。
mdl1。FitInfo
ans =结构体字段:TerminationStatus:“log-likelihood的相对容忍度已满足。”NumIterations: 26 NegativeLogLikelihood: 5.6915e+04 Perplexity: 742.7118 Solver:“cgs”历史:[1x1 struct]
计算保持测试集的困惑。
[〜,ppl1] = logp(mdl1,documentstest)
ppl1 = 781.6078
将包含40个主题的LDA模型与词袋模型相匹配。
numTopics = 40;numTopics mdl2 = fitlda(袋,“详细”,0);
查看有关型号适合的信息。
mdl2。FitInfo
ans =结构体字段:TerminationStatus:“log-likelihood的相对容忍度已满足。”NumIterations: 37 NegativeLogLikelihood: 5.4466e+04 Perplexity: 558.8685 Solver:“cgs”历史:[1x1 struct]
计算保持测试集的困惑。
[~, ppl2] = logp (mdl2 documentsTest)
ppl2 = 808.6602
较低的困惑表明,该模型可能更适合保留的测试数据。
输入参数
输出参数
算法
的logp.使用迭代pseudo-count描述的方法
参考
瓦拉赫、汉娜·M、伊恩·默里、鲁斯兰·萨拉赫丁诺夫和大卫·米米诺。“主题模型评价方法”。在第26届机器学习国际年会论文集, 1105 - 1112页。ACM, 2009年。哈佛大学
您还可以从以下列表中选择一个网站:
