主要内容
变换
将文档转换为低维空间
句法
描述
例子
将文档转换为LSA语义空间
加载示例数据。文件sonnetspreprocessed.txt.txt.包含Precrocessed版本的莎士比亚的十四行诗。该文件每行包含一个十四行诗,单词由空格分隔。从中提取文本sonnetspreprocessed.txt.txt.,将文本拆分为换行符的文档,然后授权文档。
filename =.“sonnetsPreprocessed.txt”;str =提取文件(文件名);textdata = split(str,newline);文档= tokenizeddocument(textdata);
创建一个词袋模型使用Bagofwords..
BAG = BAGOFWORDS(文件)
BAG =具有属性的BagofWords:Counts:[154x3092双]词汇:[“最公平”“生物”“欲望”......] Numwords:3092 NumFocuments:154
适合20个组件的LSA模型。
numCompnents = 20;numCompnents mdl = fitlsa(袋)
MDL = Lsamodel具有属性:NumComponents:20个组件重量:[2.7866E + 03 515.5889 443.6428 316.6428 316.4191 ......] DocumentCores:[154x20 Double] Wordcores:[3092x20双]词汇:[“最公平”“生物”“欲望”......] featuretrentryengexponent:2
使用变换将前10个文档转换为LSA模型的语义空间。
dscores =变换(mdl、文档(1:10))
dscores =10×205.6059 -1.8559 0.9286 -0.7086 -0.4652 -0.8340 0.6751 0.0611 0.2268 1.9320 -0.7289 -1.0864 0.7131 -0.0571 -0.3401 0.0940 -0.4406 1.7507 -1.1534 0.1785 7.3069 -2.3578 1.8359 -2.3442 -1.5776 -2.0310 0.7948 1.3411 -1.1700 1.8839 0.0883 0.4734 -1.1244 0.67951.3585 -0.0247 0.3627 -0.5414 -0.0272 -0.0114 7.1056 -2.3508 -2.8837 -1.0688 -0.3462 -0.6962 0.0334 -0.0472 0.4916 0.6496 -1.1959 -1.0171 -0.4020 1.2953 -0.4583 0.5984 -0.3890 1.1780 0.6413 0.6575 8.6292 -3.0471 -0.8512 -0.4356 -0.30550.4671 -1.4219 -0.8454 -0.8270 0.4122 2.2082 -1.1770 1.7775 -2.2344 -2.7813 1.4979 0.7486 -2.0593 0.6376 1.0721 1.0434 1.7490 0.8703 -2.2315 -1.1221 0.2848 -2.0522 -0.6975 1.7191 -0.2852 0.8879 0.9950 -0.5555 0.8842 -0.0360 1.0050 0.4158 0.5061 0.9602 0.4672 6.8358-2.0806 -3.3798 -1.0452 -0.2075 2.0970 -0.4477 0.2080 0.9532 1.6203 0.6653 0.0036 1.0825 0.6396 -0.2154 -0.0794 0.7108 1.8007 -4.0326 -0.3872 2.3847 0.3923 -0.4323 -1.5340 0.4023 -1.0396 -1.0326 0.3776 0.2101 -1.0944 -0.7513 -0.2894 0.4303 0.1864 0.4922 0.4844 0.5191 -0.2378 0.9528 0.4817 3.7925 -0.3941 -4.4610 -0.4930 0.4651 0.3404 -0.5493 0.1470 0.5065 0.2566 0.3394 -1.1529 -0.0391 -0.8800 -0.4712 0.9672 0.5457 -0.3639 -0.3085 0.5637 4.6522 0.7188 -1.1787 -0.8996 0.3360 0.4531 -0.1935 0.3328 -0.8640 -1.6679 -0.8056 -2.1993 0.1808 0.0163 -0.9520 -0.8982 0.6603 3.6451 1.2412 1.9621 8.8218 -0.8168 -2.5101 1.1197 -0.8673 -1.2336 0.0768 0.1943 -0.7629 -0.1222 0.3786 1.1611 0.2326 0.3415 -0.3327 -0.3792 1.7554 0.2526 -2.1574 -0.0193
将文档转换为LDA主题混合物
在此示例中重现结果,设置rng到“默认”.
rng (“默认”)
加载示例数据。文件sonnetspreprocessed.txt.txt.包含Precrocessed版本的莎士比亚的十四行诗。该文件每行包含一个十四行诗,单词由空格分隔。从中提取文本sonnetspreprocessed.txt.txt.,将文本拆分为换行符的文档,然后授权文档。
filename =.“sonnetsPreprocessed.txt”;str =提取文件(文件名);textdata = split(str,newline);文档= tokenizeddocument(textdata);
创建一个词袋模型使用Bagofwords..
BAG = BAGOFWORDS(文件)
BAG =具有属性的BagofWords:Counts:[154x3092双]词汇:[“最公平”“生物”“欲望”......] Numwords:3092 NumFocuments:154
适合具有五个主题的LDA模型。
numTopics = 5;numTopics mdl = fitlda(袋)
初始主题分配在0.102958秒内采样。===================================================================================== |迭代|每个时间|相对|训练|主题|主题||| iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.00 | | 1.212e+03 | 1.250 | 0 | | 1 | 0.01 | 1.2300e-02 | 1.112e+03 | 1.250 | 0 | | 2 | 0.02 | 1.3254e-03 | 1.102e+03 | 1.250 | 0 | | 3 | 0.01 | 2.9402e-05 | 1.102e+03 | 1.250 | 0 | =====================================================================================
mdl = ldamodel具有属性:numtopics:5个字复制:1个主题:1.2500 CorpustopicProbability:[0.2000 0.2000 0.2000 0.2000 0.2000 0.2000] DocumentTopicProbabilitience:[154x5双]主题点:[3092x5双]词汇:[“公平”“生物”......是主题订单:'初始合适概率'fitinfo:[1x1 struct]
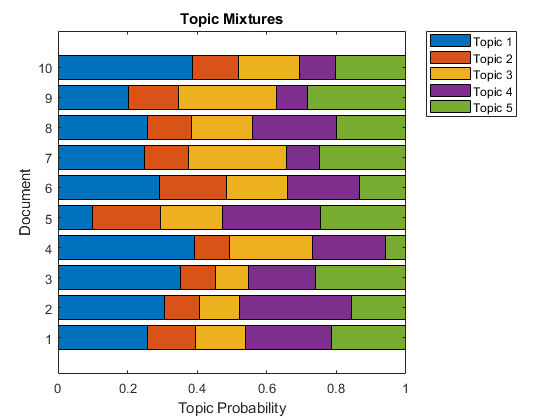
使用变换将文档转换为主题概率的向量。您可以使用堆叠的条形图可视化这些混合物。查看前10个文件的主题混音。
主题模糊=变换(MDL,文档(1:10));图Barh(主题模拟,'堆积') xlim([0 1]) title(“主题混音”)包含(“主题概率”) ylabel (“文档”) 传奇(“主题”+字符串(1:numTopics),“位置”那“东北朝”)
将单词计数矩阵转换为LDA主题混音
加载示例数据。sonnetsCounts.mat包含一个单词计数矩阵和相应的词汇预处理版本的莎士比亚十四行诗。
加载sonnetsCounts.mat大小(数量)
ans =.1×2154 3092
适合20个主题的LDA模型。在此示例中重现结果,设置rng到“默认”.
rng (“默认”)numtopics = 20;mdl = fitlda(计数,numtopics)
初始主题分配在0.13535秒内采样。===================================================================================== |迭代|每个时间|相对|训练|主题|主题||| iteration | change in | perplexity | concentration | concentration | | | (seconds) | log(L) | | | iterations | ===================================================================================== | 0 | 0.03 | | 1.159e+03 | 5.000 | 0 | | 1 | 0.05 | 5.4884e-02 | 8.028e+02 | 5.000 | 0 | | 2 | 0.04 | 4.7400e-03 | 7.778e+02 | 5.000 | 0 | | 3 | 0.03 | 3.4597e-03 | 7.602e+02 | 5.000 | 0 | | 4 | 0.03 | 3.4662e-03 | 7.430e+02 | 5.000 | 0 | | 5 | 0.03 | 2.9259e-03 | 7.288e+02 | 5.000 | 0 | | 6 | 0.03 | 6.4180e-05 | 7.291e+02 | 5.000 | 0 | =====================================================================================
mdl = ldamodel具有属性:numtopics:20字复制:1个题复杂:5个主张:5 CorpustopicProbability:[0.0500 0.0500 0.0500 0.0500 0.0500 ...] DocumentTopicProbability:[154x20双]主题页:[3092x20双]词汇:[“1”“2”“3“”4“”5“......]主题订单:'初始适合概率'fitinfo:[1x1 struct]
使用变换将文档转换为主题概率的向量。
主题模糊=转换(MDL,Counts(1:10,:))
topicMixtures =10×200.0167 0.0035 0.1645 0.0977 0.0433 0.0833 0.0987 0.0033 0.0299 0.0234 0.0033 0.0345 0.0235 0.0958 0.0667 0.0519 0.0833 0.0300 0.0711 0.0544 0.0116 0.0044 0.0033 0.0033 0.0431 0.0053 0.0145 0.0421 0.0971 0.0033 0.0040 0.1632 0.1784 0.0937 0.0683 0.0398 0.0954 0.0037 0.0293 0.0482 0.01078 0.0064 0.06120.0036 0.0176 0.0036 0.0464 0.0906 0.1169 0.0888 0.1115 0.1180 0.0607 0.0055 0.0962 0.2403 0.0033 0.0296 0.1613 0.0164 0.0955 0.0163 0.0045 0.0415 0.0404 0.0342 0.0176 0.0417 0.0642 0.0033 0.0676 0.0341 0.0341 0.0948 0.0038 0.01099 0.0187 0.0560 0.01045 0.0356 0.0668 0.1196 0.0038 0.0931 0.06260.0445 0.0035 0.1167 0.0034 0.0446 0.0583 0.1268 0.01135 0.0034 0.0047 0.0993 0.0909 0.0582 0.0308 0.0887 0.0856 0.0034 0.1720 0.0764 0.0090 0.0180 0.0325 0.1213 0.0036 0.0036 0.0505 0.0472 0.0348 0.0477 0.0039 0.0038 0.0122 0.0041 0.0036 0.1605 0.1487 0.0465 0.0043 0.0033 0.1248 0.0033 0.0299 0.0033 0.01699 0.06950.0033 0.0039 0.0620 0.0833 0.0040 0.0700 0.0033 0.1479 0.0033 0.0433 0.0412 0.0387 0.0555 0.0165 0.0166 0.0433 0.0033 0.0038 0.0048 0.0033 0.0473 0.0474 0.1290 0.1107 0.0089 0.0112 0.0167 0.1555 0.2423 0.0040 0.0362 0.0035 0.1117 0.0304 0.0034 0.1248 0.0439 0.0340 0.0168 0.0714 0.0034 0.0214 0.0056 0.0449 0.1438 0.0036 0.0290 0.0980 0.0304
输入参数
输出参数
在R2017B中介绍
你也可以从以下列表中选择一个网站:
