主要内容
萨莫代尔
潜在语义分析(LSA)模型
描述
潜在语义分析(LSA)模型发现文档及其包含的单词之间的关系。LSA模型是一种降维工具,可用于在高维单词计数上运行低维统计模型。如果该模型使用n-grams包模型进行拟合,则软件将n-grams视为单个单词。
创建
使用Fitlsa.功能。
特性
对象功能
使改变 |
将文档转换为低维空间 |
例子
拟合LSA模型
将潜在语义分析模型适合一系列文件。
加载示例数据。文件十四行诗预处理.txt包含Precrocessed版本的莎士比亚的十四行诗。该文件每行包含一个十四行诗,单词由空格分隔。从中提取文本十四行诗预处理.txt,将文本拆分为换行符的文档,然后授权文档。
filename =.“十四行诗预处理.txt”;str = inthelfiletext(filename);textdata = split(str,newline);文档= tokenizeddocument(textdata);
使用创建一个单词包模型Bagofwords.。
BAG = BAGOFWORDS(文件)
BAG =具有属性的BagofWords:Counts:[154x3092双]词汇:[“最公平”“生物”“欲望”......] Numwords:3092 NumFocuments:154
适合20个组件的LSA模型。
numComponents=20;mdl=fitlsa(袋子,numComponents)
MDL = Lsamodel具有属性:NumComponents:20个组件重量:[2.7866E + 03 515.5889 443.6428 316.6428 316.4191 ......] DocumentCores:[154x20 Double] Wordcores:[3092x20双]词汇:[“最公平”“生物”“欲望”......] featuretrentryengexponent:2
使用LSA模型将新文档转换为较低的维度空间。
newdocuments = tokenizeddocument([“什么名字?任何其他名字的玫瑰都会闻起来。”“如果音乐是爱的食物,那就继续演奏吧。”]);dscores=转换(mdl、新文档)
数据核=2×200.1338 0.1623 0.1680 -0.0541 -0.2464 -0.0134 -0.2604 -0.0205 0.1127 0.0627 0.3311 -0.2327 0.1689 -0.2695 0.0228 0.1241 0.1198 0.2535 -0.0607 0.0305 0.2547 0.5576 -0.0095 0.5660 -0.0643 -0.1236 0.0082 0.0522 -0.0690 -0.0330 0.0385 0.0803 -0.0373 0.0384 -0.00050.1943 0.0207 0.0278 0.0101 -0.0469
计算文档相似度
从某些文本数据创建一个单词袋式模型。
str=[“早餐,我喜欢火腿,鸡蛋和培根。”“我有时会跳过早餐。”“晚餐吃鸡蛋和火腿。”];文档=令授权鳕(str);bag = bagofwords(文件);
拟合包含两个组件的LSA模型。将特征强度指数设置为0.5。
NumComponents = 2;指数= 0.5;mdl = fitlsa(袋子,num components,......'featureestrengthexponent',指数)
mdl=lsaModel,属性:NumComponents:2个组件权重:[16.2268 4.0000]文档分数:[3x2 double]WordScores:[14x2 double]词汇:[“我”喜欢“火腿”…]功能强度分量:0.5000
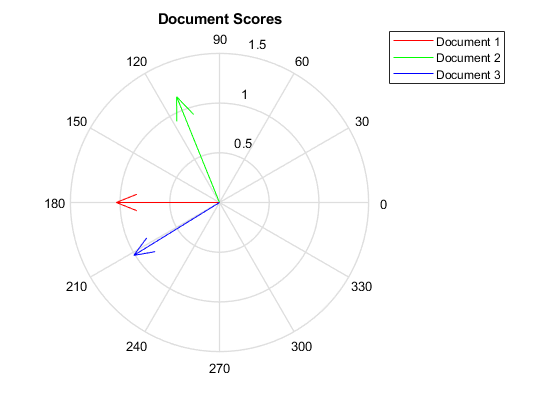
使用以下公式计算文档得分向量之间的余弦距离:Pdist..查看矩阵中的距离D.使用方形。D(i,j)表示文档之间的距离一世和j。
dscores = mdl.documentscores;距离= pdist(Dscores,'余弦');D=正方形(距离)
D=3×30 0.6244 0.1489 0.6244 0 1.1670 0.1489 1.1670 0
通过在指南针图中绘制文档分数向量,可视化文档之间的相似性。
数字罗盘(双核(1,1)、双核(1,2),'红色的')持有在…上罗盘(Dscores(2,1),Dscores(2,2),“绿色”)指南针(DScores(3,1),Dscores(3,2),“蓝色”)持有关标题(“文档分数”)传奇([“文件1”“文件2”“文件3”],“位置”那“最好的方向”)
也可以看看
在R2017B中介绍
您还可以从以下列表中选择网站:
