选择LDA模型的主题数量
此示例显示了如何确定潜在Dirichlet分配(LDA)模型的合适数量的主题。
要确定适当数量的主题,您可以将LDA模型的拟合优度与不同数量的主题进行比较。您可以通过计算一组文档的复杂度来评估LDA模型的拟合优度。复杂度表示模型对一组文档的描述程度。较低的复杂度表示非常适合。
提取和预处理文本数据
加载示例数据factoryReports.csv包含出厂报告,包括每个事件的文本描述和分类标签。从字段中提取文本数据描述.
文件名=“factoryreports.csv”; 数据=可读性(文件名,“文本类型”,“字符串”);textdata = data.description;
使用函数标记和预处理文本数据PreprocessText.在此示例结束时列出。
文档=预处理文本(textData);文档(1:5)
ans=5×1标记文档:6个标记:项目偶尔卡住扫描仪滑阀7个标记:响亮的嘎嘎声传来装配机活塞4个标记:切断电源启动设备3个标记:油炸电容器装配机3个标记:混合器跳闸保险丝
随机留出10%的文件进行验证。
numdocuments = numel(文件);cvp = cvpartition(numfocuments,“坚持”,0.1); 文件应变=文件(cvp.培训);文件验证=文件(cvp.测试);
从培训文档创建一个单词袋式模型。删除总共出现超过两次的单词。删除包含没有单词的任何文件。
bag=bagOfWords(documentsTrain);bag=删除常用词(bag,2);bag=删除空文档(bag);
选择主题的数量
我们的目标是选择一系列主题,与其他数量的主题相比,这些主题可以最大程度地减少困惑。这不是唯一的考虑因素:适合更多主题的模型可能需要更长的时间才能收敛。要查看折衷的效果,请计算拟合优度和拟合时间。如果最佳主题数量较高,则y您可能希望选择一个较低的值以加快拟合过程。
为主题数量的一系列值拟合一些LDA模型。比较测试文件中各模型的拟合时间和复杂度。困惑是这个问题的第二个输出logp.功能。要获得第二个输出而不将第一个输出分配给任何东西,请使用~象征拟合时间是最短的时间连续启动上次迭代的值。此值位于历史结构FitInfoLDA模型的财产。
要更快拟合,请指定'求解'成为'Savb'。若要抑制详细输出,请设置'verbose'到0.这可能需要几分钟才能运行。
numtopicsRange = [5 10 15 20 40];对于i = 1:numel(numtopicsrange)numtopics = numtopicsrange(i);mdl = fitlda(袋子,numtopics,...'求解','Savb',...'verbose',0);[~,validationComplexity(i)]=logp(mdl,documentsValidation);timePassed(i)=mdl.FitInfo.History.TimesRunStart(end);终止
显示绘图中每个主题数量的困惑和经过的时间。在左轴上绘制困惑,在右轴上绘制经过的时间。
图yyaxis.左边绘图(numTopicsRange、ValidationComplexity、,'+ - ')ylabel(“验证困惑”)yyaxis.正当绘图(numTopicsRange、TIMEASED、,“o-”)ylabel(“经过时间的时间”) 传奇([“验证困惑”“经过时间的时间”],'地点','东南')Xlabel(“主题数量”)
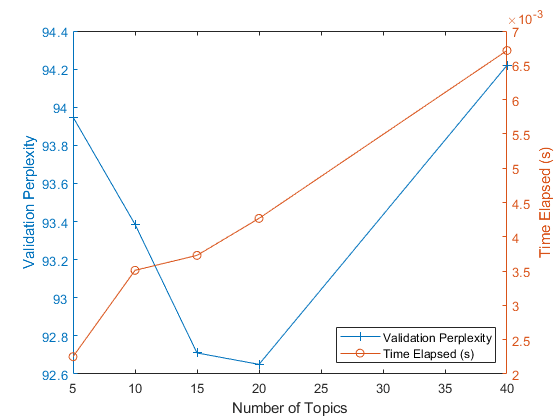
该图表明,拟合一个包含10-20个主题的模型可能是一个不错的选择。与具有不同主题数的模型相比,复杂度较低。使用该解算器,这么多主题的运行时间也是合理的。使用不同的解算器,您可能会发现增加主题数可以获得更好的拟合,但拟合效果不理想模型需要更长的时间才能收敛。
示例预处理功能
功能PreprocessText.,按顺序执行以下步骤:
使用将文本数据转换为小写
降低.使用
令人畏缩的鳕文.使用擦除标点符号
侵蚀.使用删除停止词列表(如“and”、“of”和“the”)
Removestopwords..使用删除包含2个或更少字符的单词
removeshortwords..使用删除包含15个或更多字符的单词
removeLongWords.使用的单词释放
正常化森林.
功能文档= preprocessText(TextData)%将文本数据转换为小写。CleanTextData =较低(TextData);%标记文本。文档=标记化文档(cleanTextData);%擦除标点符号。文件=侵蚀(文件);%删除停止词列表。文件=删除文字(文件);%用2个或更少的字符删除单词,以及15或更大的单词% 人物。文档= RemoveShortwords(文件,2);文件= removelongwords(文件,15);%把这些词用柠檬语法化。文档= addpartofspeechdetails(文件);文档= rangerizewords(文档,“风格”,“引理”);终止
另见
addpartofspeechdetails.|巴格沃兹|巴格沃兹|侵蚀|菲特尔达|阿尔达莫代尔|logp.|正常化森林|删除空文档|删除常用词|removeLongWords|removeshortwords.|Removestopwords.|令人畏缩的鳕文
相关话题
您还可以从以下列表中选择一个网站:
