比较LDA解决者
这个例子展示了如何通过比较模型的拟合优度和拟合时间来比较潜在的Dirichlet分配(LDA)求解器。
导入文本数据
使用arXiV API从数学论文中导入一组摘要和类别标签。属性指定要导入的记录数量importSize变量。请注意,arXiV API一次只能查询1000篇文章,并且请求之间需要等待。
importSize = 50000;
导入第一组记录。
url =“https://export.arxiv.org/oai2?verb=ListRecords”+...“集=数学”+...“&metadataPrefix = arXiv”;选择= weboptions (“超时”, 160);代码= webread (url选项);
解析返回的XML内容并创建一个数组htmlTree包含记录信息的对象。
树= htmlTree(代码);子树= findElement(树,“记录”);元素个数(子树)
迭代地导入更多的记录块,直到达到所需的数量,或者没有更多的记录。要继续从您离开的位置导入记录,请使用resumptionToken属性。要遵守arXiV API施加的速率限制,在使用暂停函数。
而numel(subtrees) < importSize subtreeResumption = finelement (tree,“resumptionToken”);如果isempty (subtreeResumption)打破结束resumptionToken = extractHTMLText (subtreeResumption);url =“https://export.arxiv.org/oai2?verb=ListRecords”+..." &resumptionToken = "+ resumptionToken;暂停(20)code = webread(url,options);树= htmlTree(代码);子树=[子树;findElement(树,“记录”));结束
提取和预处理文本数据
从解析的HTML树中提取摘要和标签。
找到“<文摘>”元素使用findElement函数。
subtreesAbstract = htmlTree ("");为subtreesAbstract(i) = findElement(subtrees(i)),“抽象”);结束
属性从包含摘要的子树中提取文本数据extractHTMLText函数。
textData = extractHTMLText (subtreesAbstract);
随机留出30%的文件进行验证。
numDocuments =元素个数(textData);本量利= cvpartition (numDocuments,“坚持”, 0.1);textDataTrain = textData(培训(cvp));textDataValidation = textData(测试(cvp));
使用该函数对文本数据进行标记和预处理preprocessText在本例的最后列出。
documentsTrain = preprocessText (textDataTrain);documentsValidation = preprocessText (textDataValidation);
从培训文档中创建词汇袋模型。删除总出现次数不超过两次的单词。删除任何不含文字的文档。
袋= bagOfWords (documentsTrain);袋= removeInfrequentWords(袋,2);袋= removeEmptyDocuments(袋);
对于验证数据,从验证文档创建一个单词包模型。您不需要从验证数据中删除任何单词,因为任何没有出现在拟合的LDA模型中的单词都会被自动忽略。
validationData = bagOfWords (documentsValidation);
拟合和比较模型
对于每个LDA求解器,拟合一个包含40个主题的模型。为了在相同的坐标轴上绘制结果时区分求解器,请为每个求解器指定不同的直线属性。
numTopics = 40;解决= [“研究生院理事会”“真空断路”“cvb0”“savb”];lineSpecs = [“+ -”“* - - - - - -”“x -”“啊——”];
使用每个求解器拟合LDA模型。对于每个求解器,指定初始主题浓度1,每通过一次数据验证模型一次,不拟合主题浓度参数。使用的数据FitInfo拟合LDA模型的性质,绘制验证复杂度和经过的时间。
默认情况下,随机求解器使用1000个小批量,每10次迭代验证一次模型。对于这个求解器,要在每次数据通过时验证模型一次,请将验证频率设置为装天花板(numObservations / 1000),在那里numObservations为培训数据中的文档数。对于其他求解器,将验证频率设置为1。
对于随机求解器未评估验证复杂度的迭代,随机求解器报告验证复杂度南在FitInfo财产。要绘制验证复杂度,请从报告值中删除nan。
numObservations = bag.NumDocuments;数字为I = 1:numel(solvers) solver = solvers(I);lineSpec = lineSpecs(我);如果解算器= =“savb”numIterationsPerDataPass =装天花板(numObservations / 1000);其他的numIterationsPerDataPass = 1;结束mdl = fitlda(袋、numTopics、...“规划求解”解算器,...“InitialTopicConcentration”, 1...“FitTopicConcentration”假的,...“ValidationData”validationData,...“ValidationFrequency”numIterationsPerDataPass,...“详细”, 0);历史= mdl.FitInfo.History;timeElapsed = history.TimeSinceStart;validationPerplexity = history.ValidationPerplexity;%去除nan。idx = isnan (validationPerplexity);timeElapsed (idx) = [];validationPerplexity (idx) = [];情节(timeElapsed validationPerplexity lineSpec)在结束持有从包含(“时间运行(s)”) ylabel (“验证困惑”ylim([0 inf])图例(求解器)
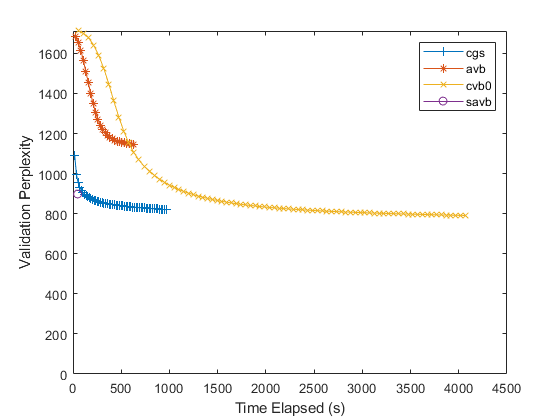
对于随机求解器,只有一个数据点。这是因为这个解算器只传递一次输入数据。要指定更多的数据传递,请使用“DataPassLimit”选择。批处理解决程序(“研究生院理事会”,“真空断路”,“cvb0”),要指定用于适合模型的迭代次数,请使用“IterationLimit”选择。
更低的验证困惑意味着更好的匹配。通常,解决“savb”和“研究生院理事会”迅速地收敛到一个很好的匹配。的解算器“cvb0”可能收敛得更好,但收敛的时间要长得多。
为FitInfo财产,fitlda函数根据每个文档主题概率的最大似然估计,从文档概率估计验证复杂度。这通常计算起来更快,但可能比其他方法不准确。或者,使用logp函数。这个函数计算更精确的值,但运行时间更长。举一个例子,说明如何使用logp,请参阅从单词计数矩阵计算文档日志的概率.
预处理功能
这个函数preprocessText执行以下步骤:
使用标记文本
tokenizedDocument.使使用的词义化
normalizeWords.删除标点符号使用
erasePunctuation.删除使用停止词的列表(如“and”,“of”和“the”)
removeStopWords.删除使用2个或更少字符的单词
removeShortWords.删除超过15个字符的单词
removeLongWords.
函数文件= preprocessText (textData)标记文本。文件= tokenizedDocument (textData);将单词义化。= addPartOfSpeechDetails文件(文档);文档= normalizeWords(文档,“风格”,“引理”);%擦掉标点符号。= erasePunctuation文件(文档);删除一个停止词列表。= removeStopWords文件(文档);%删除2个或更少的单词,以及15个或更大的单词%字符。文件= removeShortWords(文件,2);= removeLongWords文档(文档、15);结束
另请参阅
addPartOfSpeechDetails|bagOfWords|erasePunctuation|fitlda|ldaModel|logp|normalizeWords|removeEmptyDocuments|removeInfrequentWords|removeLongWords|removeShortWords|removeStopWords|tokenizedDocument|wordcloud
相关的话题
你也可以从以下列表中选择一个网站:
