長短期記憶ネットワクを使用したecg信号の分類
この例では生理网2017年挑战からの心拍心電図(ECG)データを深層学習と信号処理を使用して分類する方法を示します。特に,この例では長短期記憶ネットワ,クと時間-周波数解析を使用します。
GPUおよび并行计算工具箱™を使用してこのワークフローの再現と高速化を行う例については,長短期記憶ネットワクをgpu高速化と組み合わせて使用したecg信号の分類を参照してください。
はじめに
心电图は,人の心臓の電気的活動を一定期間記録します。医師はecgを使用して,患者の心拍が正常か正常でないかどうかを視覚的に検出します。
心房細動AFibは,心臓の上部室,心房が下部室,心室と連携せずに脈打っているときに発生する不規則な心拍の一種です。
この例では,PhysioNet 2017挑战赛[1]、[2]、[3.]からのecgデ,タを使用します。これは,https://physionet.org/challenge/2017/で入手できます。データは,300 Hzでサンプリングされ,専門家の手によって次の4つの別々のクラスに分けられた,一連の心电图信号で構成されています。正常(N), AFib (A),その他の律動(O),およびノ` `ズを含む録音(~)。この例では,深層学習を使用して分類プロセスを自動化する方法を説明します。手順として,AFibの兆候を示す信号から正常な心电图信号を識別できるバイナリ分類器を調査します。
長短期記憶(LSTM)ネットワークは,シーケンスおよび時系列のデータの学習に適した再帰型ニューラルネットワーク(RNN)の一種です。LSTMネットワクは,シケンスのタムステップ間の長期的な依存関係を学習できます。LSTM層(lstmLayer(深度学习工具箱))では順方向の時間系列を確認でき,双方向のLSTM層(bilstmLayer(深度学习工具箱))では順方向と逆方向の両方の時間系列を確認できます。この例では,双方向のLSTM層を使用します。
この例では,人工知能(ai)の問題を解く際にデ,タ中心の手法を使用することの利点を示します。生データを使用してLSTMネットワークに学習させる最初の試行では,標準以下の結果しか得られません。抽出した特徴を使用して同じモデルア,キテクチャに学習させると,分類性能が大幅に改善されます。
学習プロセスを高速化するには,gpuを使用するマシン上でこの例を実行します。マシンにGPUと并行计算工具箱™がある場合は,MATLAB®は学習にGPUを自動で使用します。それ以外ではCPUを使用します。
デ,タの読み込みおよび確認
ReadPhysionetDataスクリプトを実行して生理网网络サイトからデータをダウンロードし,適切な形式の心电图信号を含む垫ファイル(PhysionetData.mat)を生成します。デ,タのダウンロ,ドには数分かかる場合があります。PhysionetData.matが現在のフォルダ,に既に存在していない場合のみスクリプトを実行する条件ステ,トメントを使用します。
如果~ isfile (“PhysionetData.mat”) ReadPhysionetData结束负载PhysionetData
読み込み操作ではワクスペスに2の変数,信号と标签が追加されます。信号はECG信号を保持するcell配列です。标签は対応する信号のグラウンドトゥルスラベルを保持する分类配列です。
信号(1:5)
ans =5×1单元格数组{1×9000 double} {1×9000 double} {1×18000 double} {1×9000 double} {1×18000 double}
标签(1:5)
ans =5×1分类N N N a a
関数总结を使用して,デ,タに含まれるAFib信号と正常な信号の数を確認します。
总结(标签)
A 738n5050
信号長のヒストグラムを生成します。ほとんどの信号は9000サンプルの長さです。
L = cellfun(@length,Signals);h =直方图(L);xticks (0:3000:18000);xticklabels (0:3000:18000);标题(“信号长度”)包含(“长度”) ylabel (“数”)

各クラスから1の信号のセグメントを可視化します。通常の心拍は規則的に起こりますが,AFib心拍は不規則な間隔で起こります。さらにAFib心拍信号はP波が欠落することがよくあります。P波は,QRS正常な心拍信号では群の前に脈を打ます。正常な信号のプロットではp波とQRS群が示されます。
normal =信号{1};aFib =信号{4};Subplot (2,1,1) plot(normal)标题(“正常的节奏”xlim([4000,5200]) ylabel(“振幅(mV)”)文本(4330、150、“P”,“HorizontalAlignment”,“中心”)文本(4370、850、“QRS”,“HorizontalAlignment”,“中心”) subplot(2,1,2) plot(aFib)标题(心房纤维性颤动的xlim([4000,5200]) xlabel(“样本”) ylabel (“振幅(mV)”)

学習用デ,タの準備
学習中に,関数trainNetworkはデ,タをミニバッチに分割します。関数は、その後、同じミニバッチ内の信号にパディングや切り捨てを行い、すべて同じ長さになるようにします。パディングや切り捨てをしすぎると、ネットワークのパフォーマンスにマイナスの影響が出ることがあります。これは、ネットワークが追加または削除された情報に基づいて信号を誤って解釈することがあるためです。
過度なパディングや切り捨てを防ぐため,関数segmentSignalsをecg信号に適用してすべてが9000サンプルの長さになるようにします。関数は9000サンプル未満の信号を無視します。信号が9000サンプルを超える場合,segmentSignalsはできるだけ多くの9000サンプルのセグメントに分割し,残っているサンプルは無視します。18500年たとえばサンプルの信号は,2つの9000サンプルの信号になり,残りの500サンプルは無視されます。
[信号,标签]= segmentSignals(信号,标签);
配列信号の最初の5つの要素を表示し,各エントリが9000サンプルの長さになっていることを確認します。
信号(1:5)
ans =5×1单元格数组{1×9000 double} {1×9000 double} {1×9000 double} {1×9000 double} {1×9000 double}
1番目の試行:生の信号デ,タを使用した分類器の学習
分類器を設計するには,前のセクションで生成した生の信号を使用します。分類器に学習させるための学習セットと新しいデータに対して分類器の精度をテストするためのテストセットに信号を分割します。
関数总结を使用して,AFib信号と通常の信号の比率が718:4937(約1:7)であることを示します。
总结(标签)
A 718 n 4937
約7/8の信号が正常であるため,分類器は単純にすべての信号を正常として分類することで高い精度が達成できる,と学習することがあります。このバイアスを回避するには,データセットのAFib信号を複製することでAFibデータを拡張して,正常な信号とAFib信号とを同じ数にします。一般にオーバーサンプリングと呼ばれるこの複製は,深層学習で使用されるデータ拡張の1つの形式です。
信号をそれらのクラスに従って分割します。
afibX =信号(标签==“一个”);afibY = Labels(标签==“一个”);normalX =信号(标签==“N”);normalY = Labels(标签==“N”);
次に,dividerandを使用して,各クラスからタ,ゲットを学習セットとテストセットにランダムに分割します。
[trainIndA,~,testIndA] = diverand (718,0.9,0.0,0.1);[trainIndN,~,testIndN] = dividerand(4937,0.9,0.0,0.1);XTrainA = afibX(trainIndA);YTrainA = afibY(trainIndA);XTrainN = normalX(trainIndN);YTrainN = normalY(trainIndN);XTestA = afibX(testIndA);YTestA = afibY(testIndA);XTestN = normalX(testIndN);YTestN = normalY(testIndN);
こうして,646のAFib信号と4443の正常な信号が学習用となります。各クラスの信号の数を同じにするには,最初の4438の正常な信号を使用してから,repmatを使用して最初の634のAFib信号を7回繰り返します。
テスト用には,72のAFib信号と494の正常な信号があります。最初の490の正常な信号を使用してから,repmatを使用して最初の70のAFib信号を7回繰り返します。既定の設定では,隣り合う信号がすべて同じラベルにならないように,ニューラルネットワークは学習前にデータをランダムにシャッフルします。
XTrain = [repmat(XTrainA(1:634),7,1);XTrainN (1:4438)];YTrain = [repmat(YTrainA(1:634),7,1);YTrainN (1:4438)];XTest = [repmat(XTestA(1:70),7,1);XTestN (1:490)];YTest = [repmat(YTestA(1:70),7,1);YTestN (1:490);];
正常な信号とAFib信号の分布はこうして,学習セットとテストセットの両方で等しく釣り合います。
总结(YTrain)
A 4438 n 4438
总结(欧美)
A 490 n 490
LSTMネットワ,クア,キテクチャの定義
LSTMネットワクは,シケンスデタのタムステップ間の長期的な依存関係を学習できます。この例では,双方向のLSTM層bilstmLayerを使用し,シ,ケンスを順方向および逆方向の両方で確認します。
入力信号がそれぞれ1次元であるため,入力サイズがサイズ1のシーケンスになるように指定します。出力サ恭顺器出力サ恭顺器ズが100の双方向恭顺器層を指定し,シ恭顺器ケンスの最後の要素を出力します。このコマンドは双方向のLSTM層に対し,入力時系列の100の特徴へのマッピングを指示し,その後全結合層への出力を準備します。最後に,サイズが2の全結合層を含めることによって2個のクラスを指定し,その後にソフトマックス層と分類層を配置します。
层= [...sequenceInputLayer (1) bilstmLayer (100“OutputMode”,“最后一次”) fullyConnectedLayer(2) softmaxLayer分类层
2”BiLSTM BiLSTM与100个隐藏单元3”全连接2全连接层4”Softmax Softmax 5”分类输出crossentropyex
次に,分類器の学習オプションを指定します。“MaxEpochs”を10に設定してネットワ,クが学習デ,タから10個のパスを作れるようにします。150年の“MiniBatchSize”は,ネットワ,クに一度に150の学習信号の確認を指示します.0.01の“InitialLearnRate”は,学習プロセスを加速させます。1000年の“SequenceLength”は,一度に確認するデータ量が多すぎてマシンがメモリ不足にならないように信号をより小さな塊に分割します。”GradientThreshold’を1に設定して,勾配が大きくなりすぎないようにして学習プロセスを安定化させます。“阴谋”を“训练进步”として指定し,反復回数の増大に応じた学習の進行状況のグラフィックスを示すプロットを生成します。“详细”を假に設定し,プロットで示されるデ,タに対応する表出力を非表示にします。この表を表示する場合は,“详细”を真正的に設定します。
この例では,適応モ,メント推定(adam)ソルバ,を使用します。亚当•はLSTMなどのRNNでは,既定のモーメンタム項付き確率的勾配降下法(个)ソルバーよりもパフォーマンスにおいて優れています。
选项= trainingOptions(“亚当”,...“MaxEpochs”10...“MiniBatchSize”, 150,...“InitialLearnRate”, 0.01,...“SequenceLength”, 1000,...“GradientThreshold”, 1...“ExecutionEnvironment”,“汽车”,...“阴谋”,“训练进步”,...“详细”、假);
LSTMネットワ,クの学習
trainNetworkを使用し,指定した学習オプションと層のア,キテクチャでLSTMネットワ,クに学習させます。学習セットが大きいため,学習プロセスには数分かかる場合があります。
net = trainNetwork(XTrain,YTrain,图层,选项);

学習の進行状況プロットの一番上のサブプロットには,学習精度,つまり各ミニバッチの分類精度が表示されます。学習が正常に進行すると,この値は通常100%へと増加します。一番下のサブプロットには,学習損失,まり各ミニバッチの交差エントロピ損失が表示されます。学習が正常に進行すると,この値は通常ゼロへと減少します。
学習が収束しない場合,プロットは上方または下方の特定の方向に向かわず,値と値の間で振動する場合があります。この振動は学習精度が向上せず,学習損失が減少していないことを意味します。この状況は学習の最初から発生することもありますし,学習精度においてまずいくらか改善された後でプロットが停滞してしまうこともあります。多くの場合,学習オプションを変更するとネットワ,クが収束できるようになります。MiniBatchSizeが減少したり,InitialLearnRateが減少したりすると,学習時間が長くなることがありますが,ネットワ,クの学習を改善できます。
分類器の学習精度は約50% ~ 60%約で振動し,10エポックの最後で,既に学習に数分間かかっています。
学習精度とテスト精度の可視化
学習精度を計算します。これは学習した信号に対する分類器の精度を表します。まず,学習デ,タを分類します。
trainPred = category (net,XTrain,“SequenceLength”, 1000);
分類問題において,混同行列は真の値が既知である一連のデータに対する分類パフォーマンスの可視化に使用されます。ターゲットクラスは信号のグラウンドトゥルースラベルで,出力クラスはネットワークによって信号に割り当てられるラベルです。座標軸のラベルはAFib (A)と正常(N)のクラスラベルを表します。
confusionchartコマンドを使用して,テストデ,タ予測に対する全体の分類精度を計算します。真陽性率と偽陽性率を行要約に表示するため,“row-normalized”として“RowSummary”を指定します。また,陽性の予測値と偽発見率を列要約に表示するため,“column-normalized”として“ColumnSummary”を指定します。
LSTMAccuracy = sum(trainPred == YTrain)/ nummel (YTrain)*100
LSTMAccuracy = 61.7283
图confusionchart (YTrain trainPred,“ColumnSummary”,“column-normalized”,...“RowSummary”,“row-normalized”,“标题”,“LSTM困惑表”);

テストデ,タを同じネットワ,クで分類します。
testPred =分类(net,XTest,“SequenceLength”, 1000);
テスト精度を計算して,混同行列で分類性能を可視化します。
LSTMAccuracy = sum(testPred == YTest)/ nummel (YTest)*100
LSTMAccuracy = 66.2245
图confusionchart(欧美、testPred“ColumnSummary”,“column-normalized”,...“RowSummary”,“row-normalized”,“标题”,“LSTM困惑表”);

2番目の試行:特徴抽出によるパフォ,マンスの改善
デ,タからの特徴抽出によって,分類器の学習精度とテスト精度を向上させることができます。抽出する特徴を決定するために,この例では,スペクトログラムなどの時間——周波数イメージを計算するアプローチを適応させて,それらを使用して畳み込みニューラルネットワーク(CNN)に学習させます[4]、[5]。
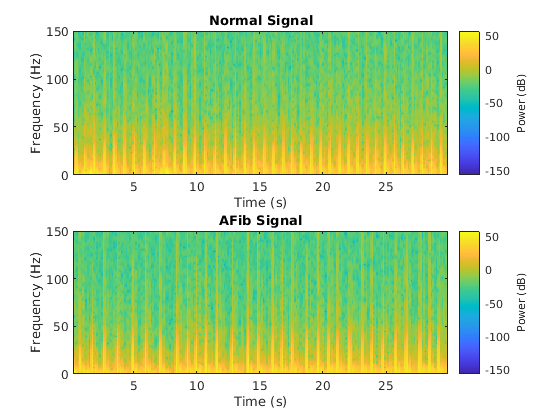
各タ@ @プの信号のスペクトログラムを可視化します。
Fs = 300;图次要情节(2,1,1);pspectrum(正常,fs,的谱图,“TimeResolution”, 0.5)标题(“正常信号”次要情节(2,1,2);pspectrum (aFib fs,的谱图,“TimeResolution”, 0.5)标题(“AFib信号”)
この例では,CNNの代わりにLSTMを使用するため,1次元信号に作用するようにアプローチを変換することが重要です。時間-周波数(tf)モ.メントはスペクトログラムから情報を抽出します。各モ,メントは1次元の特徴として使用し,lstmに入力することができます。
時間領域の次の2のtf。
瞬時周波数 (
instfreq)スペクトルエントロピ(
pentropy)
関数instfreqは,パワ,スペクトログラムの最初のモ,メントとして信号の時間依存周波数を推定します。関数は時間枠上の短時間フ,リエ変換を使用してスペクトログラムを計算します。この例では,関数は255個の時間枠を使用します。関数の時間出力は,時間枠の中心に対応します。
各タ@ @プの信号の瞬時周波数を可視化します。
[instFreqA,tA] = instfreq(aFib,fs);[instFreqN,tN] = instfreq(normal,fs);图次要情节(2,1,1);情节(tN, instFreqN)标题(“正常信号”)包含(“时间(s)”) ylabel (瞬时频率的次要情节(2,1,2);instFreqA情节(tA)标题(“AFib信号”)包含(“时间(s)”) ylabel (瞬时频率的)

cellfunを使用して,学習セットとテストセットの各セルに関数instfreqを適用します。
instfreqTrain = cellfun(@(x)instfreq(x,fs)',XTrain,“UniformOutput”、假);instfreqTest = cellfun(@(x)instfreq(x,fs)',XTest,“UniformOutput”、假);
スペクトルエントロピ,は,信号のスペクトルがどの程度スパ,キ,でフラットであるかを計測します。正弦波の和などのスパキスペクトルの信号はスペクトルエントロピが低くなります。ホワ@ @トノ@ @ズなどのフラットスペクトルの信号はスペクトルエントロピ@ @が高くなります。関数pentropyは,パワ,スペクトログラムに基づいてスペクトルエントロピ,を推定します。瞬時周波数推定の場合と同様に,pentropyでは255個の時間枠を使用してスペクトログラムを計算します。関数の時間出力は,時間枠の中心に対応します。
各タ▪▪プの信号のスペクトルエントロピ▪▪を可視化します。
[pentropyA,tA2] = pentropy(aFib,fs);[pentropyN,tN2] = pentropy(normal,fs);图子图(2,1,1)图(tN2,pentropyN)标题(“正常信号”) ylabel (“谱熵”) subplot(2,1,2) plot(tA2,pentropyA)标题(“AFib信号”)包含(“时间(s)”) ylabel (“谱熵”)

cellfunを使用して,学習セットとテストセットの各セルに関数pentropyを適用します。
pentropyTrain = cellfun(@(x)pentropy(x,fs)',XTrain,“UniformOutput”、假);pentropyTest = cellfun(@(x)pentropy(x,fs)',XTest,“UniformOutput”、假);
新しい学習セットとテストセットの各セルが2次元,つまつり2の特徴をもつように特徴を連結します。
XTrain2 = cellfun(@(x,y)[x;y],instfreqTrain,pentropyTrain,“UniformOutput”、假);XTest2 = cellfun(@(x,y)[x;y],instfreqTest,pentropyTest,“UniformOutput”、假);
新しい入力の形式を可視化します。各セルには既に,1の9000サンプル長の信号は含まれまていません。ここでは2の255サンプル長の特徴が含まれます。
XTrain2 (1:5)
ans =5×1单元格数组{2×255 double} {2×255 double} {2×255 double} {2×255 double} {2×255 double}
デ,タの標準化
瞬時周波数とスペクトルエントロピ,の平均値には,ほぼ1桁の差があります。さらに,瞬時周波数の平均値はLSTMには高すぎるため効果的に学習することができない可能性があります。平均値が大きくて値の範囲が広いデータに対してネットワークが近似される場合,入力量が大きいとネットワークの学習と収束の速度が低下します[6]。
意思是(instFreqN)
Ans = 5.5615
意思是(pentropyN)
Ans = 0.6326
学習セットの平均値と標準偏差を使用して学習セットとテストセットを標準化します。標準化,。
XV = [XTrain2{:}];mu = mean(XV,2);sg = std(XV,[],2);XTrainSD = XTrain2;XTrainSD = cellfun(@(x)(x-mu)./sg,XTrainSD,“UniformOutput”、假);XTestSD = XTest2;XTestSD = cellfun(@(x)(x-mu)./sg,XTestSD,“UniformOutput”、假);
標準化した瞬時周波数とスペクトルエントロピ,の平均値を表示します。
instFreqNSD = XTrainSD{1}(1,:);pentropyNSD = XTrainSD{1}(2,:);意思是(instFreqNSD)
Ans = -0.3211
意思是(pentropyNSD)
Ans = -0.2416
LSTMネットワ,クア,キテクチャの変更
信号にはそれぞれ2つの次元があるため,入力シーケンスサイズに2を指定してネットワークアーキテクチャを変更する必要があります。出力サ恭顺器出力サ恭顺器ズが100の双方向恭顺器層を指定し,シ恭顺器ケンスの最後の要素を出力します。サイズが2の全結合層を含めることによって2個のクラスを指定し,その後にソフトマックス層と分類層を配置します。
层= [...sequenceInputLayer (2) bilstmLayer (100“OutputMode”,“最后一次”) fullyConnectedLayer(2) softmaxLayer分类层
2 " BiLSTM BiLSTM带100个隐藏单元3 "全连接2 "全连接层4 " Softmax Softmax 5 "分类输出
学習オプションを指定します。エポックの最大回数を30に設定すると,ネットワークが学習データから30個のパスを作れるようになります。
选项= trainingOptions(“亚当”,...“MaxEpochs”30岁的...“MiniBatchSize”, 150,...“InitialLearnRate”, 0.01,...“GradientThreshold”, 1...“ExecutionEnvironment”,“汽车”,...“阴谋”,“训练进步”,...“详细”、假);
時間-周波数の特徴を使用したLSTMネットワクの学習
trainNetworkを使用し,指定した学習オプションと層のア,キテクチャでLSTMネットワ,クに学習させます。
net2 = trainNetwork(XTrainSD,YTrain,layers,options);

学習精度が大きく改善しています。交差エントロピの損失は0に近くなっています。さらに,tfモ,メントが生のシ,ケンスより短いため,学習に必要な時間が短くなっています。
学習精度とテスト精度の可視化
更新したLSTMネットワ,クを使用して学習デ,タを分類します。混同行列として分類性能を可視化します。
trainPred2 = category (net2,XTrainSD);LSTMAccuracy = sum(trainPred2 == YTrain)/ nummel (YTrain)*100
LSTMAccuracy = 83.5962
图confusionchart (YTrain trainPred2,“ColumnSummary”,“column-normalized”,...“RowSummary”,“row-normalized”,“标题”,“LSTM困惑表”);

テストデ,タを更新したネットワ,クで分類します。混同行列をプロットして,テスト精度を調べます。
testPred2 = category (net2,XTestSD);LSTMAccuracy = sum(testPred2 == YTest)/ nummel (YTest)*100
LSTMAccuracy = 80.1020
图confusionchart(欧美、testPred2“ColumnSummary”,“column-normalized”,...“RowSummary”,“row-normalized”,“标题”,“LSTM困惑表”);

まとめ
この例では,分類器をビルドし,LSTMネットワークを使用して心电图信号の心房細動を検出する方法を示します。手順では,オーバーサンプリングを使用して,大半が健康な患者で構成される母集団の中で異常な状態を検出しようとするときに発生する分類バイアスを回避します。生の信号デ,タを使用したLSTMネットワ,クの学習では良い分類精度は得られません。各信号で2つの時間——周波数モーメントの特徴を使用してネットワークに学習させると,分類性能は大幅に改善されて学習時間も短くなります。
参考文献
[1]基于短单导联心电图记录的房颤分类:2017年心脏病学挑战赛中的物理网络/计算。https://physionet.org/challenge/2017/
[2] Clifford, Gari,刘成宇,Benjamin Moody, Li-wei H. Lehman, Ikaro Silva, Qiao Li, Alistair Johnson和Roger G. Mark。“从短单导联心电图记录中进行房颤分类:2017年心脏病学挑战赛中的物理网络计算。”心脏病学计算(雷恩:IEEE)。Vol. 44, 2017, pp. 1-4。
[3]戈德伯格,a.l., L. A. N.阿马拉尔,L.格拉斯,J. M.豪斯多夫,P. Ch.伊万诺夫,R. G.马克,J. E.米耶图斯,G. B.穆迪,c . k。彭先生和斯坦利先生。PhysioBank, PhysioToolkit,和PhysioNet:复杂生理信号新研究资源的组成部分循环.Vol。2000年6月13日,101,第23期,第e215-e220页。http://circ.ahajournals.org/content/101/23/e215.full
庞斯,乔迪,托马斯·利迪,泽维尔·塞拉。音乐驱动的卷积神经网络实验。第十四届基于内容的多媒体索引国际研讨会.June 2016。
[5]王,D。“深度学习重塑助听器,”IEEE频谱《中国经济》2017年3月第3期,第32-37页。doi: 10.1109 / MSPEC.2017.7864754。
布朗利,杰森。如何在Python中为长短期记忆网络缩放数据. 2017年7月7日。https://machinelearningmastery.com/how-to-scale-data-for-long-short-term-memory-networks-in-python/.
参考
関数
instfreq|pentropy|trainingOptions(深度学习工具箱)|trainNetwork(深度学习工具箱)|bilstmLayer(深度学习工具箱)|lstmLayer(深度学习工具箱)
関連するトピック
- 長短期記憶ネットワ,ク(深度学习工具箱)
您也可以从以下列表中选择一个网站: