このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
ロバスト回帰を使用した外れ値の影響の低減
ロバスト線形回帰を使用して,線形回帰モデルの外れ値の影響を減らすことができます。このトピックでは,ロバスト回帰について定義し,それを使用して線形モデルにあてはめる方法を示し,結果を標準近似と比較します。fitlmを名前と値のペアの引数“RobustOpts”と共に使用して,ロバスト回帰モデルにあてはめることができます。または,robustfitを使用して,単にロバスト回帰係数パラメーターを計算できます。
ロバスト回帰を使用する理由
ロバスト線形回帰は,標準の線形回帰よりも外れ値の影響を受けにくくなります。標準の線形回帰では,通常の最小二乗近似を使用して,応答データを1つ以上の係数をもつ予測子データに関連付けるモデルパラメーターを計算します(詳細については,多変量回帰モデルの推定を参照してください)。残差を二乗するとこれらの極値データ点の影響を増幅することになるため,結果として,外れ値が近似に大きく影響します。線形回帰モデルとはで説明した標準線形回帰を使用するモデルは,観測された応答において誤差が正規分布するというような,ある仮定に基づきます。誤差の分布が非対称または外れ値になる傾向がある場合,モデルの仮定は無効になり,パラメーターの推定,信頼区間,その他の計算された統計量が信頼できなくなります。
ロバスト回帰では,反復的に再重み付けした最小二乗と呼ばれる方法を使用して,各データ点に重みを割り当てます。この方法では,狭い部分のデータでの大きな変化に対して感度が低くなります。結果として,ロバスト線形回帰は,標準の線形回帰よりも外れ値の影響を受けにくくなります。
反復的に再重み付けした最小二乗
重み付き最小二乗では,近似プロセスに追加のスケール係数としての重みを含めて,近似を向上させます。重みは,各応答値が最終的なパラメーター推定にどの程度影響するかを決定します。品質が低いデータ点(たとえば,外れ値)は,近似への影響が少なくなければなりません。重み<年代pan class="inlineequation">w<年代ub>我を計算するには,テューキーの二重平方関数などの定義済みの重み関数を使用できます(その他のオプションについては,fitlmの名前と値のペアの引数“RobustOpts”を参照)。
“反復的に再重み付けした最小二乗”<年代pan class="emphasis">のアルゴリズムは自動的かつ反復的に重みを計算します。アルゴリズムは初期化時に各データ点に等しい重みを割り当て,通常の最小二乗を使用してモデル係数を推定します。アルゴリズムは各反復で,前の反復においてモデル予測から遠かった点にはより小さな重みが与えられるように,重み<年代pan class="inlineequation">w<年代ub>我を計算します。次に,アルゴリズムは重み付き最小二乗を使用してモデル係数bを計算します。係数推定の値が指定した許容誤差内に収束すると,反復が停止します。このアルゴリズムは,最小二乗法を使用してデータの大部分にあてはまる曲線を求めると同時に,外れ値の影響を最小限に抑えようとします。
詳細は,反復的に再重み付けした最小二乗の手順を参照してください。
標準およびロバスト最小二乗近似の結果の比較
この例では,関数fitlmでロバスト回帰を使用する方法を示し,ロバスト近似と標準の最小二乗近似の結果を比較します。
摩尔データを読み込みます。先頭の5列に予測子データがあり,6列目に応答データが含まれています。
负载<年代pan style="color:#A020F0">摩尔X =摩尔(:1:5);: y =摩尔(6);
最小二乗線形モデルをデータにあてはめます。
mdl = fitlm (X, y)
mdl =线性回归模型:y ~ 1 + x1 + x2 + x3 + x4 + x5Estimate SE tStat pValue ___________ __________ _________ ________ (Intercept) -2.1561 0.91349 -2.3603 0.0333 x1 - 9.1160e -06 0.00051835 -0.017385 0.98637 x2 0.0013159 0.0012635 1.0415 0.31531 x3 0.0001278 7.6902e-05 1.6618 0.11876 x4 0.0078989 0.014 0.6421 0.58154 x5 0.00014165 7.3749e-05 1.9208 0.07536520、误差自由度:14均方根误差:0.262 r平方:0.811,校正r平方:0.743 F-statistic vs. constant model: 12, p-value = 0.000118
名前と値のペアの引数“RobustOps”を使用して,ロバスト線形モデルをデータにあてはめます。
mdlr = fitlm (X, y,<年代pan style="color:#A020F0">“RobustOpts”,<年代pan style="color:#A020F0">“上”)
mdlr =线性回归模型(稳健拟合):y ~ 1 + x1 + x2 + x3 + x4 + x5Estimate SE tStat pValue __________ __________ ________ ________ (Intercept) -1.7516 0.86953 -2.0144 0.063595 x1 1.7006e-05 0.00049341 0.034467 0.97299 x2 0.00088843 0.0012027 0.7387 0.47229 x3 0.00015729 7.3202e-05 2.1487 0.049639 x4 0.0060468 0.013326 0.45375 0.65696 x5 6.8807e-05 7.0201e-05 0.98015 0.3436520、误差自由度:14均方根误差:0.249 r平方:0.775,校正r平方:0.694 F-statistic vs. constant模型:9.64,p-value = 0.000376
2つのモデルの残差を視覚的に調べます。
tiledlayout(1、2)nexttile plotResiduals (mdl,<年代pan style="color:#A020F0">“概率”)标题(<年代pan style="color:#A020F0">“线性适应”) nexttile plotResiduals (mdlr<年代pan style="color:#A020F0">“概率”)标题(<年代pan style="color:#A020F0">健壮的适合的)
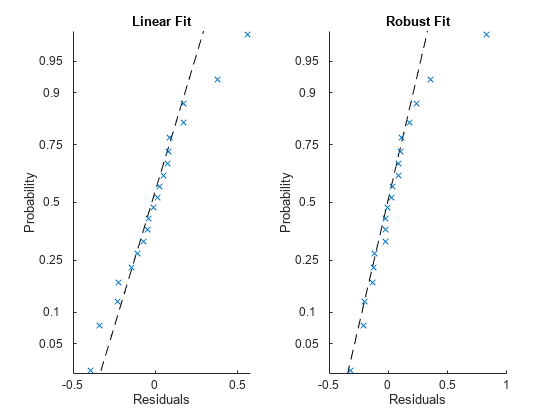
ロバスト近似の残差(プロットの右半分)は直線に近く,顕著な外れ値が1つのみあります。
外れ値のインデックスを見つけます。
离群值=找到(isoutlier (mdlr.Residuals.Raw))
离群值= 1
ロバスト近似の観測値の重みをプロットします。
图b = bar(mdlr.Robust.Weights);b.FaceColor =<年代pan style="color:#A020F0">“平”;b.CData(例外:)=(。5 0 5);xticks(1:长度(mdlr.Residuals.Raw))包含(<年代pan style="color:#A020F0">“观察”) ylabel (<年代pan style="color:#A020F0">“重量”)标题(<年代pan style="color:#A020F0">‘强健’符合重量)
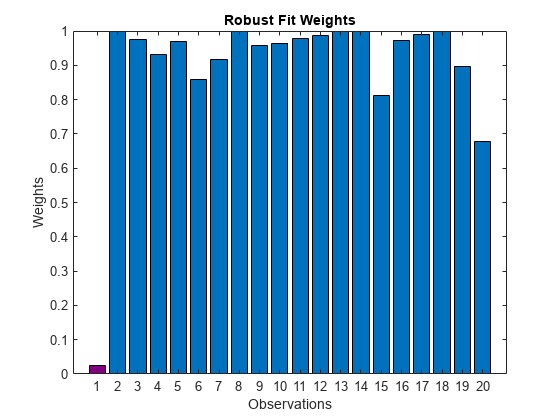
ロバスト近似の外れ値の重み(紫色のバー)は,他の観測値の重みよりもはるかに小さい値です。
反復的に再重み付けした最小二乗の手順
反復的に重み付けした最小二乗アルゴリズムは,次の手順に従います。
重みの初期推定から始めて,重み付き最小二乗でモデルをあてはめます。
調整済み残差を計算します。調整済み残差は次によって与えられます。
ここで,<年代pan class="inlineequation">r<年代ub>我は通常の最小二乗残差,<年代pan class="inlineequation">h<年代ub>我は最小二乗近似のてこ比値です。てこ比による残差の調整では,最小二乗近似に大きな影響を与える,高いてこ比のデータ点の重みを小さくします(ハット行列とてこ比を参照)。
残差を標準化します。標準化された調整済み残差は次によって与えられます。
ここでKは調整定数,は
s =疯狂/ 0.6745によって与えられる誤差項の標準偏差の推定値です。疯了は,残差の中央値に対する残差の中央絶対偏差です。定数0.6745は推定を正規分布に対して不偏にします。予測子データ行列Xにp個の列がある場合,中央値を計算するときに,最小のものからp個の絶対偏差が除外されます。uの関数としてロバストな重み<年代pan class="inlineequation">w<年代ub>我を計算します。たとえば,二重平方重みは次によって与えられます。
ロバスト回帰係数bを推定します。重みによって、パラメーター推定 b の式は次のように変更されます。
ここでWは対角重み付け行列,Xは予測子データ行列,yは応答ベクトルです。
次の重み付き最小二乗誤差を推定します。
ここで,<年代pan class="inlineequation">w<年代ub>我は重み,<年代pan class="inlineequation">y<年代ub>我は観測応答,<年代pan class="inlineequation">ŷ<年代ub>我は近似応答,<年代pan class="inlineequation">r<年代ub>我は残差です。
近似が収束するか,最大反復回数に達すると,反復が停止します。そうでない場合は2番目の手順に戻って,最小二乗近似の次の反復を実行します。
参考
fitlm|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">robustfit|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">LinearModel|<年代pan itemscope itemtype="//www.tianjin-qmedu.com/help/schema/MathWorksDocPage/SeeAlso" itemprop="seealso">plotResiduals
関連するトピック
选择网站
选择一个网站,在那里获得翻译的内容,并看到当地的活动和优惠。根据您的位置,我们建议您选择:<年代trong class="recommended-country">.
选择<年代pan class="recommended-country">网站你也可以从以下列表中选择一个网站:
