이번역번역이지는최신내용을담고담고않습니다않습니다。최신최신내용을영문영문으로여기를클릭클릭
이진분류분류를위한위한벡터벡터
서포트벡터머신이해하기
분리가능한데이터
아이터가정확히두개의클래스를가지는는경우서포트벡터(svm)을사용할할수수。SVM은두개의클래스구분하는최적의초평면으로써으로써이터데데분류분류분류분류svm에서최적의초평면이란두두클래스간에에마진을갖는초평면을의미합니다。마진은내부데이터점이없는초평면에평행인슬래브(板)의최대너비를의미합니다。
서포트벡터는분리초평면에가장가장까운이터점점。이러한점점은슬래브의경계상에존재다음그림은이러한정의를를시각으로보여줍니다。여기서+는유형1의데이터점점을 - 는는-1의데이터점점을。

수학수학적정식:원원(原始)。아래논의는赫斯蒂,蒂巴里兰,弗里德曼[1]과克里斯蒂安尼,Shawe-Taylor[2]의설명을따릅니다。
훈련훈련이터는는점(벡터)xj와점집합의범주yj입니다。일부차원d의경우Xjεr.D.이고yj=±1입니다。초평면의방정식은다음과같습니다。
여기서βεr.D.이고b는실수입니다。
다음문제는가장적합적합.분리초평면(즉,결정경계)을정의합니다。모든데이터점(xjyj)에대해다음이성립성립||β||를최소화하는β와b를를。
서포트벡터는경계상에존재하며 을충족하는Xj입니다。
수학적편의를위해이문제는일반적으로 를최소화하는문제와동일한문제로지정됩니다。이는2차계획법문제。최적해 를통해다음과이벡터z의분류를수행할있습니다。
는분류점수이고z가결정경계로부터떨어진거리나타냅니다나타냅니다。
수학적정식화:쌍대문제(双)。쌍대2차계획법문제를것이계산량측면에서더간단합니다。쌍대쌍대문제를얻으려면얻으려면양의라그랑주αj에각제약제약조건을을값을취한후후목적함수에서
여기서는β와b에대한P.의정상점을찾습니다。L.P.의기울기를0으로설정하면다음다음됩니다됩니다。
| (1) |
L.P.에대입하면쌍대문제LD.를를됩니다。
여기서는α.j≥0에대해최대화합니다。일반일반적,많은αj는최대0입니다。쌍대문제의해에서0이아닌αj는수식1에표시된대로초평면을정의하고,αjyjXj의합으로β를반환합니다。0이아닌αj에대응하는데이터점xj$서포트벡터입니다。
0이아닌αj에대한L.D.의도함수의최적값은0입니다。이로부터다음을얻을있습니다。
특히이경우,0이아닌αj를갖는갖는이용해해에서에서값값구할수있습니다있습니다。
쌍대문제는표준2차계획법문제입니다。일례로优化工具箱™의Quadprog.(优化工具箱)솔버는이러한유형의문제에대한해를구합니다。
분리가불가능한한이터
아이터가분리초평면초평면에잘맞지않을수수이경우,svm은소프트마진(柔软边缘)을사용할할수。이는모든데이터점점은아니지만많은많은데의미을분리하는하는초평면의미의미의미
소프트소프트마진에대한대한표준적인정식화로는다음가지가있습니다。두공식모두여유변수ξj와벌점모수Ç를가집니다。
L.1- 노름(常规)문제는다음과같습니다。
조건
ξj를제곱대신여유변수로사용하면l1- 노름인것입니다。
fitcsvm의세가지솔버솔버smo.那ISDA那l1qp.는L.1- 노름문제를최소화합니다。L.2- 노름문제는다음과같습니다。
동일한제약조건이적용적용。
이러한정식화에서는C를늘리면여유변수ξj에더많은가중치가적용된다는것을알수있습니다。즉,최적화가클래스간에더엄격한분리를수행하려한다는것을알수있습니다。이와마찬가지로,C의크기가작아지면오분류에대한중요성은낮아집니다。
수학적정식화:쌍대문제(双)。더손쉬운계산방법을알아보기위해이소프트마진정식화에대한l1쌍대문제가있다가정가정해해。라그랑주승수μ.j를사용하여l1- 노름(符号)문제에대한최소화할는다음과。
여기서는β,b,양의ξj에대한L.P.의정상점을찾습니다。L.P.의기울기를0으로설정하면다음다음됩니다됩니다。
이러한방정식방정식으로부터다음쌍대문제식을바로얻을수수
이때제약제약조건은다음과。
마지막부등식0≤α.j≤C는C가상자제약조건인이유를줍니다。C는라그랑주승수αj의의허용값을을을상자내부,즉경계영역내로합니다。
b에대한기울기방정식은서포트벡터에되는0이아닌αj의세트로해b를제공합니다。
유사한방식으로大号2- 노름문제의쌍대문제를작성하고이에대한해를구할수있습니다。자세한내용은Christianini,Shawe泰勒[2](6장)을참조하십시오。
fitcsvm구현。두쌍대소프트마진문제모두2차계획법문제입니다。내부적으로,fitcsvm은문제에대한해를데사용할수있는다양한한을가집니다。
단일클래스나이진분류의경우,데이터에서예상되는이상값에대한비율(
OutlierFraction참조)을설정하지않으면디폴트솔버로순차적최소규모최적화(SMO)가사용됩니다。SMO는일련의2점최소화를통해1-노름문제를최소화합니다。최적화를수행하는동안SMO는선형제약조건 을따르고모델에편향항을명시적으로포함시킵니다。Smo는비교적빠릅니다。smo에대한자세한내용은[3]항목을참조하십시오。이진분류분류의,아이터에서에서되는이상값값에대한비율을설정하면솔버로반복단일단일단일이터(ISDA)이사용이。Smo와와가지로,ISDA는1-노름문제의해를구합니다。SMO와달리,ISDA는일련의1점최소화를통해최소하며,선형제약조건을않고,모델에편향항을명시포함포함않습니다。ISDA에에대한자세한자세한내용[4]항목을참조하십시오。
단일클래스또는이진분류의의优化工具箱라이선스를가지고있으면
Quadprog.(优化工具箱)를사용하여1-노름문제의해를구해수있습니다있습니다。Quadprog.많메모리를이사용용,높은정밀도로2차계획법의해를。자세한내용은2차계획법정의(优化工具箱)항목을참조하십시오。
커널을사용한비선형변환
일부이진분류문제의경우,명확한분류기준이되는단순한초평면이존재하지않습니다。이러한문제를위해SVM분리초평면의단순성을거의유지하는수학적접근방법의변형이존재합니다。
이접근방법은재생커널이론에서에서나온다음과같은결과사용합니다。
다음속성을갖는함수G(X1, x2)클래스가있습니다。선형공간와,다음조건에따라x를S로매핑하는함수φ가있습니다。
G (x1, x2)= <φ(X1),φ(X2)>。
내적은공간年代에서수행됩니다。
이함수클래스클래스는다음을을포함。
다항식:양의정수p에대해다음과같습니다。
G (x1, x2) = (1 + x1'X2)P.。
방사형형기저(가우스):
G (x1, x2)= exp(-∥x1-X2)∥2).
다층퍼셉트론또는시그모이드(신경망):양수p1과음수P.2에대해다음과같습니다。
G (x1, x2)= tanh(p1X1'X2+ p2).
참고
P.1과P.2의일부세트는유효한재생커널을생성하지않습니다。
fitcsvm은시그모이드커널을지원하지않습니다。대신,'骨箱'이름 - 값값의인수를사용하여시그모이드커널커널을정의하고하고할수수자세한내용은사용자지정커널을사용하여svm분류기훈련시키기항목을참조하십시오。
커널을사용하는수학적접근방법은초평면의계산방법에따라달리집니다。초평면분류의모든계산은내적만사용합니다。따라서비,선형커널에서동일한계산과해알고리즘을사용하여비선형분류기를얻을수있습니다。결과로생성되는분류기는특정공간年代에있는초곡면이지만공간年代를식별하거나검토할필요는없습니다。
서포트벡터머신사용하기
지도학습모델과마찬가지로,먼저서포트벡터머신을훈련시킨후분류기를교차검증해야합니다。훈련된머신을사용하여새데이터를분류(예측)합니다。또한,만족스러운예측정확도를얻기위해다양한SVM커널함수를사용할수있으며,이경우커널함수의모수를조정해야합니다。
SVM분류기훈련시키기
fitcsvm을사용하여svm분류기를훈련시키고필요한교차검증합니다。가장일반일반적인인구문다음과다음과다음과
svmmodel = fitcsvm(x,y,'kernelfunction','rbf',...'标准化',true,'classnames',{'negclass','posclass'});
입력값은다음과같습니다。
X- 예측변수데이터로구성구성행렬입니다(여기서각행은하나의값이고,각열은하나의예측변수임)。y- 클래스레이블로구성된배열로각행이X의행값에대응합니다。y는直言형배열,문자형배열,字符串형배열,논리형벡터또는숫자형벡터,또는문자형벡터로구성된셀형배열일수있습니다。KernelFunction- 2-클래스클래스학습의의경우디폴트값'线性'입니다。이는데이터를를초평면으로분리분리값'高斯'(또는'rbf')은단일클래스학습인경우디폴트값이며,가우스(또는방사형기저함수)커널을사용하도록지정합니다。SVM분류기를성공적으로훈련시키기위한중요한단계는적합한커널함수를선택하는것입니다。标准化- 분류기를훈련시키기전에가예측변수를표준화할지할지를나타내는플래그입니다할지여부Classnames.- 음성클래스와양성클래스간구분하거나하거나이터에에포함시킬클래스를지정지정음성음성클래스는첫번째(또는문자형배열의행),즉,'negclass'이고양성양성클래스는는두번째(또는문자형배열의행),즉,'posclass'입니다。Classnames.는y와같은데이터형이어야합니다。특히,다른분류기의성능을비교경우클래스이름을을하는이좋습니다。
결과결과로생성되는되는훈련된(SVMModel)은svm알고리즘을통해최적된모수를포함합니다。이를통해새데이터를를분류할수。
훈련을제어하는데사용할할수추가이름 - 값값fitcsvm함수도움말페이지를를참조。
SVM분류기로새데이터분류하기
预测를사용하여새데이터를분류합니다。훈련된SVM분류기(SVMModel)를사용하여새데이터를를분류하는하는구문다음과다음과다음과다음과다음과다음과
[标签,得分] =预测(SVMMODEL,NEWX);
결과로생성되는벡터标签은X의의각행에에대한분류를를分数는소프트점수로구성된n×2행렬입니다。각행은새관측값X의행에대응됩니다。첫번째열에는음성클래스로되는되는관측값점수점수가포함되고,두번째열에는양성분류되는관측값의점수점수점수됩니다의점수점수됩니다。
점수가아니라사후확률확률을추정,훈련훈련svm분류기(SVMModel)를먼저fitPosterior에전달해야합니다。이함수는점수 - 사후확률변환함수를점수에피팅합니다。구문은다음과같습니다。
scorsvmmodel = fitposterior(svmmodel,x,y);
분류기scorsvmmodel.의속성scoretransform.은은최적의변환변환함수를포함포함scorsvmmodel.을预测로로합니다。점수를반환하는,출력인수分数는음성클래스(分数의1열)또는양성클래스(分数의2열)로로되는관측값사후확률을합니다。
svm분류기조정하기
fitcsvm의“OptimizeHyperparameters”이름 - 값쌍의인수를사용하여교차검증손실을최소화하는모수값을구할수있습니다。적합한모수는'BoxConstraint'那'骨箱'那'kernelscale'那'PolynomialOrder'那'标准化'입니다。예제는베이즈최적최적화사용하여svm분류기피팅최적화하기항목을참조하십시오。또는,使用Budesopt优化交叉验证的SVM分类器에나와있는것처럼bayesopt함수를사용할수도있습니다。bayesopt함수를사용하면유연한한사용자지정지정최적화를구현할수수수bayesopt함수를사용할경우,fitcsvm함수를사용할할때는최적최적할수모수를포함하여모든모수최적화할수수수모수최적화할수수
데이터를
fitcsvm으로전달하고이름——값쌍의인수'kernelscale','auto'를설정합니다。훈련된SVM모델을SVMModel이라고한다고가정합니다。소프트웨어는발견적(启发式)절차에따라커널스케일을선택합니다。발견적절차는부표본추출을사용합니다。따라서결과를재현하려면분류기를훈련시키기전에RNG.를사용하여난수시드값을설정하십시오。분류기를
横梁로전달하여교차검증합니다。기본적으로,소프트웨어는10겹교차검증을수행합니다。교차검증된SVM모델을
Kfoldloss.로로전달하여분류분류오차추정하고유지유지svm분류기를유지하되,
'kernelscale'및'BoxConstraint'이름——값쌍의인수를조정합니다。boxconstraint.- 한가지전략은상자제약조건모수의등비수열을사용해보는것입니다。예를들어,인자10으로1E-5부터1E5.까지11개값을。boxconstraint.를늘리면서포트벡터의가줄어들수있지만,훈련시간이늘어날수도있습니다。KernelScale- 한가지전략전략은원래커널스케일로스케일링된된시그마시그마모수의등비수열을을해보는것것다음과같은방법으로이작업을수행합니다。점표기법을사용하여원래커널스케일,
ks를가져옵니다(ks = svmmodel.kernelparameters.scale.).원래커널스케일에대한새스케일링인자를사용합니다。예를들어,인자10을사용하여
ks에1E-5에서1E5.까지11개값을곱합니다。
가장낮은낮은분류오차를생성하는모델을선택선택정확도를더향상시키기모수를가로미세조정해야할있습니다。초기초기시작시작,이번에는에는1.2를사용하여하여또다른검증단계를수행합니다교차검증단계를수행
가우스커널을사용하여svm분류기를훈련시키기
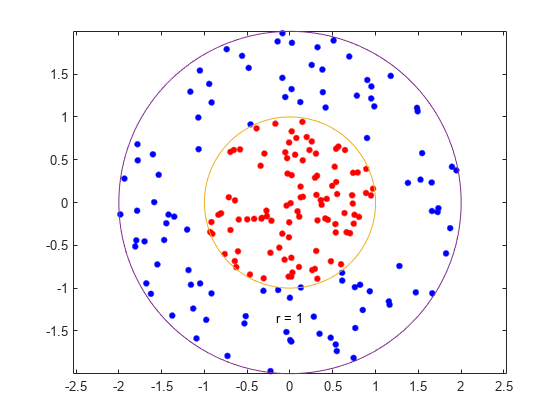
이예제에서는가우스커널함수사용하여하여분류기를생성하는방법을보여먼저,2차원단위원판내부의하나의클래스를하고반지름반지름반지름에서2까지의원환포함된또그런다음,가우스우스사형형기저함수커널사용하여이터를를기준으로분류기생성생성모델이대칭원형이기때문에디폴트선형이문제에확실히부적합합니다。상자제약조건모수를正로설정하여오분류되는훈련점이없는엄격한분류를합니다。다른커널함수는엄격한분류를제공하지못할수있으므로이러한엄격한상자제약조건에서동작하지않을수있습니다。rbf분류기가클래스를분리할수있는경우에도결과가과잉훈련될수있습니다。
반지름이1인단위원판내부에균등분포된100개의점을생성합니다。반지름R.을균등확률변수의제곱근으로생성하고,각도T.를(0, )범위에서균등하게생성하여이터점점(R.cos (T.),R.罪(T.))에배치하면됩니다。
rng (1);重复性的%r = sqrt(rand(100,1));%半径t = 2 * pi * rand(100,1);% 角度data1 = [r。* cos(t),r。* sin(t)];%要点
원환원환에균등분포된100개점을합니다。반지름이제곱근에비례하지만,이번에는1부터4사이균등분포된제곱근에비례합니다。
R2 = SQRT(3 * RAND(100,1)+1);%半径t2 = 2 * pi * rand(100,1);% 角度DATA2 = [R2 * COS(T2)中,R 2 * SIN(T2)。。];%点
점을플로팅하고,비교를위해반지름1과반지름2를사용한원플로팅합니다합니다。
图;绘图(data1(:,1),data1(:,2),'r。'那“MarkerSize”, 15)在情节(DATA2(:,1),数据2(:,2),'b。'那“MarkerSize”,15)Ezpolar(@(x)1); ezpolar(@(x)2);轴平等的抓住从
한행렬에두데이터를모두할당하고,분류벡터를생성합니다。
data3 = [data1; data2];theclass = =那些(200,1);TheClass(1:100)= -1;
KernelFunction을'rbf'로설정하고boxconstraint.를正로설정하여SVM분류기를훈련시킵니다。결정경계를플로팅하고서포트벡터에플래그를지정합니다。
%训练SVM分类器cl = fitcsvm(data3,theclass,'骨箱'那'rbf'那......'BoxConstraint',inf,“类名”,[ - 1,1]);%预测分数在网格d = 0.02;[x1grid,x2grid] = meshgrid(min(data3(:,1)):d:max(data3(:1)),......min(data3(:,2)):d:max(data3(:,2))));xgrid = [x1grid(:),x2grid(:)];[〜,得分] =预测(CL,XGRID);%绘制数据和决策边界图;h(1:2)= g箭头(data3(:,1),data3(:,2),theclass,'RB'那'。');抓住在ezpolar (@ (x) 1);h(3) =情节(data3 (cl.IsSu万博1manbetxpportVector, 1), data3 (cl.IsSupportVector, 2),'KO');轮廓(x1grid,x2grid,重塑(分数(:,2),尺寸(x1grid)),[0 0],'K');传奇(H,{'-1'那'+1'那“万博1manbetx支持向量”});轴平等的抓住从
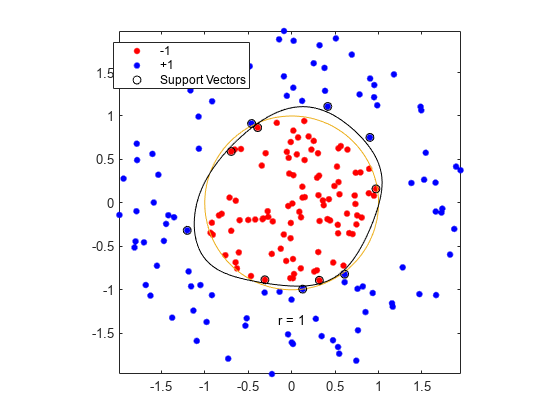
fitcsvm은반지름이1인원에가까운분류기분류기를생성。훈련아이터가무작위무작위이터라터라이발생발생하고。
디폴트모수로훈련시키는경우더근접한원형분류경계가생성되지만,이는일부훈련데이터를오분류합니다。또한,boxconstraint.의디폴트값이1이어서서포트벡터가더많이생성됩니다。
cl2 = fitcsvm(data3,theclass,'骨箱'那'rbf');[〜,scors2] =预测(CL2,XGRID);图;h(1:2)= g箭头(data3(:,1),data3(:,2),theclass,'RB'那'。');抓住在ezpolar (@ (x) 1);h(3)= plot(data3(cl2.iss万博1manbetxupportvector,1),data3(cl2.issupportvector,2),'KO');轮廓(x1grid,x2grid,重塑(scores2(:,2),大小(x1grid)),[0 0],'K');传奇(H,{'-1'那'+1'那“万博1manbetx支持向量”});轴平等的抓住从

사용자지정커널을사용하여svm분류기훈련시키기
이예제에서는아이드커널커널과사용자지정커널함수사용하여svm분류기를훈련시키고사용자지정커널커널함수를를하는을보여보여보여조정을보여보여
단위원내부임의의점으로구성된집합을생성합니다。제1사분면분면제3사분면의점은양성에속하는으로으로이블을을지정하고제제과제4照片의점은음성에속것으로이블레레지정지정지정지정지정지정
rng (1);重复性的%n = 100;每个象限点的数量%R1 = SQRT(RAND(2 * N,1));%随机半径t1 = [pi / 2 * rand(n,1);(PI / 2 * rand(n,1)+ pi)];% Q1和Q3的随机角度x1 = [r1。* cos(t1)r1。* sin(t1)];%北笛卡尔转换R2 = SQRT(RAND(2 * N,1));t2 = [pi / 2 * rand(n,1)+ pi / 2;(PI / 2 * rand(n,1)-pi / 2)];Q2和Q4的随机角度X2 = [r2.*cos(t2) r2.*sin(t2)];X = [X1;X2);%预测因子y =那些(4 * n,1);Y(2 * n + 1:结束)= -1;%的标签
데이터를플로팅합니다。
图;g箭偶(x(:,1),x(:,2),y);标题(“模拟数据散点图”)

특징공간의두행렬을입력값으로받아시그모이드커널을사용하여이입력값을그람행렬(革兰氏矩阵)로변환하는함수를작성합니다。
功能G = mysigmoid (U, V)斜率伽马和拦截c%sigmoid内核函数伽玛= 1;c = 1;g = tanh(gamma * u * v'+ c);结尾
이코드코드matlab®경로에mysigmoid.라는파일로저장합니다。
시그모이드커널커널함수사용하여svm분류기를훈련시킵니다。데이터를표준화에이좋습니다。
Mdl1 = fitcsvm(X,Y,'骨箱'那'mysigmoid'那'标准化',真正的);
Mdl1은은추정된모수모수를포함分类VM.분류기입니다。
데이터를를플로팅하고서포트벡터와결정경계를를식별식별
%在网格上计算分数d = 0.02;网格的%步长[x1Grid, x2Grid] = meshgrid (min (X (: 1)): d:马克斯(X (: 1))......min(x(:,2)):d:max(x(:,2)));xgrid = [x1grid(:),x2grid(:)];%的网格[〜,scorS1] =预测(MDL1,XGRID);%得分图;h (1:2) = gscatter (X (: 1), (:, 2), Y);抓住在h(3) =情节(X (Mdl1.IsSu万博1manbetxpportVector, 1),......x(mdl1.is万博1manbetxsupportVector,2),'KO'那“MarkerSize”,10);%支万博1manbetx持向量轮廓(x1grid,x2grid,重塑(scores1(:,2),size(x1grid)),[0 0],'K');%的决策边界标题('与决策边界的散点图') 传奇({'-1'那'1'那“万博1manbetx支持向量”},“位置”那'最好的事物');抓住从

분류의정확도를향상시키기위하여,커널모수를조정할수있습니다。이렇게하면표본내오분류율을줄일수도있지만,우선표본외오분류율을확인해야합니다。
10겹교차검증을사용하여표본외오분류율을확인합니다。
cvmdl1 = crossval(mdl1);misclass1 = kfoldloss(cvmdl1);misclass1.
MISCLASS1 = 0.1350.
표본외오분류율은13.5%입니다。
다른시그모이드함수를작성하되,γ= 0.5;를설정합니다。
功能G = mysigmoid2 (U, V)斜率伽马和拦截c%sigmoid内核函数γ= 0.5;c = 1;g = tanh(gamma * u * v'+ c);结尾
이코드코드matlab®경로에mysigmoid2.라는파일로저장합니다。
조정한시그모이드커널커널사용하여하여또svm분류기를훈련시킵니다。데이터와와결정영역을플로팅,표본외오분류율을확인。
Mdl2 = fitcsvm (X, Y,'骨箱'那'mysigmoid2'那'标准化',真正的);[~, scores2] =预测(Mdl2 xGrid);图;h (1:2) = gscatter (X (: 1), (:, 2), Y);抓住在H(3)=图(X(Mdl2.IsSuppo万博1manbetxrtVector,1),......x(mdl2.is万博1manbetxsupportVector,2),'KO'那“MarkerSize”,10);标题('与决策边界的散点图')轮廓(x1grid,x2grid,重塑(scores2(:,2),size(x1grid)),[0 0],'K');传奇({'-1'那'1'那“万博1manbetx支持向量”},“位置”那'最好的事物');抓住从CVMdl2 = crossval (Mdl2);misclass2 = kfoldLoss (CVMdl2);misclass2
misclass2 = 0.0450

시그모이드기울기를조정한,더정확한표본내피팅을이룬것것으로이며검증률검증률검증률검증률또한또한또한상상상상상상
베이즈최적최적화사용하여svm분류기피팅최적화하기
이예제예제에서fitcsvm함수와OptimizeHyperparameters이름 - 값쌍을사용하여svm분류를최적화방법방법보여줍니다。이분류분류가우스혼합모델점점를사용한한것。统计学习的要素、Hastie Tibshirani,弗里德曼(2009)의17페이지에이모델에대한설명이나와있습니다。이모델은평균과(1,0)단위분산의2차원독립정규분포로분산되고”녹색”클래스에속하는10개기준점을생성하는것으로시작합니다。또한,평균과(0,1)단위분산의2차원독립정규분포로분산되고”빨간색”클래스에속하는10개기준점도생성합니다。다음과같이각클래스(녹색과빨간색)에대해임의100개의점을생성합니다。
해당색상별로임의로균일하게분포하는기준점m을선택합니다。
평균이m이고분산이I / 5인(여기서我는2×2단위행렬임)2차원정규분포를띠는독립적인임의의점을생성합니다。이예제에서는분산I / 50을사용하여최적화의이점을더확실하게보여줍니다。
점과분류기생성하기
10개각클래스에대해기준점을생성합니다。
RNG.默认重复性的%grnpop = mvnrnd((1,0)、眼睛(2),10);redpop = mvnrnd([0, 1],眼(2),10);
기준점을표시합니다。
情节(grnpop(:,1),grnpop(:,2),'走') 抓住在情节(redpop (: 1) redpop (:, 2),'ro') 抓住从

일부빨간색기준점이녹색기준점에가깝기때문에위치만기준으로하여데이터점을분류하는것이어려울수있습니다。
각클래스에대해100개데이터점을생성합니다。
redpts =零(100,2); grnpts = redpts;为i = 1:100 gnpts(i,:) = mvnrnd(grnpop(randi(10),:),眼睛(2)* 0.02);redpts(i,:) = mvnrnd(Redpop(randi(10),:),眼睛(2)* 0.02);结尾
데이터점을표시합니다。
图绘图(GNPTS(:,1),GRNPTS(:2),'走') 抓住在情节(redpts (: 1) redpts (:, 2),'ro') 抓住从

분류를위한데이터준비준비
아이터를를한행렬행렬저장저장,각점의클래스에이블을을지정하는GRP.를생성합니다。
CDATA = [grnpts; redpts];GRP =酮(200,1);%绿色标签1,红色标签-1GRP(101:200)= -1;
교차검증준비하기
교차검증에사용할분할을설정합니다。이단계에서는최적화가각단계에사용하는훈련세트와검정세트를정합니다。
c = cvpartition (200'kfold',10);
피팅최적화하기
양호한피팅,즉교차검증손실이적은피팅을구하려면베이즈최적화를사용하도록옵션을설정하십시오。모든최적화에동일한교차검증분할C를사용합니다。
재현이가능하도록'预期改善加'수집함수를사용합니다。
opts = struct('优化器'那'Bayesopt'那“ShowPlots”,真的,'cvpartition',C,......'获取功能名称'那'预期改善加');svmmod = fitcsvm(cdata,grp,'骨箱'那'rbf'那......“OptimizeHyperparameters”那'汽车'那'hyperparameteroptimizationoptions',选择)
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| | |运行时(观察)| (estim) | | ||=====================================================================================================| | 最好1 | | 0.345 | 0.49996 | 0.345 | 0.345 | 0.00474 | 306.44 |
| 2 |最佳| 0.115 | 0.30678 | 0.115 | 0.12678 | 430.31 | 1.4864 |
|3 |接受|0.52 |0.13441 |0.115 |0.1152 |0.028415 |0.014369 |
|4 |接受|0.61 |0.387 |0.115 |0.11504 |133.94 |0.0031427 |
| 5 |接受| 0.34 | 0.2418 | 0.115 | 0.11504 | 0.010993 | 5.7742 |
|6 |最佳|0.085 |0.14416 |0.085 |0.085039 |885.63 |0.68403 |
|7 |接受|0.105 |0.26221 |0.085 |0.085428 |0.3057 |0.58118 |
|8 |接受|0.21 |0.25162 |0.085 |0.09566 |0.16044 |0.91824 |
|9 |接受|0.085 |0.16411 |0.085 |0.08725 |972.19 |0.46259 |
| 10 |接受| 0.1 | 0.2443 | 0.085 | 0.090952 | 990.29 | 0.491 |
|11 |最佳|0.08 |0.32715 |0.08 |0.079362 |2.5195 |0.291 |
|12 |接受|0.09 |0.19875 |0.08 |0.08402 |14.338 |0.44386 |
|13 |接受|0.1 |0.16585 |0.08 |0.08508 |0.0022577 |0.23803 |
|14 |接受|0.11 |0.35013 |0.08 |0.087378 |0.2115 |0.32109 |
|15 |最佳|0.07 |0.14368 |0.07 |0.081507 |910.2 |0.25218 |
|16 |最佳|0.065 |0.17852 |0.065 |0.072457 |953.22 |0.26253 |
| 17 |接受| 0.075 | 0.24059 | 0.065 | 0.072554 | 998.74 | 0.23087 |
| 18 |接受| 0.295 | 0.23305 | 0.065 | 0.072647 | 996.18 | 44.626 |
| 19 |接受| 0.07 | 0.33936 | 0.065 | 0.06946 | 985.37 | 0.27389 |
| 20 |接受| 0.165 | 0.19952 | 0.065 | 0.071622 | 0.065103 | 0.13679 |
|=====================================================================================================| | Iter | Eval客观客观| | | BestSoFar | BestSoFar | BoxConstraint | KernelScale | | |结果| | |运行时(观察)| (estim) | | || ===================================================================================================== ||21 |接受|0.345 |0.15182 |0.065 |0.071764 |971.7 | 999.01 |
|22 |接受|0.61 |0.13755 |0.065 |0.071967 |0.0010168 |0.0010005 |
|23 |接受|0.345 |0.16557 |0.065 |0.071959 |0.0010674 |999.18 |
|24 |接受|0.35 |0.12266 |0.065 |0.071863 |0.0010003 |40.628 |
|25 |接受|0.24 |0.32665 |0.065 |0.072124 |996.55 |10.423 |
|26 |接受|0.61 |0.37531 |0.065 |0.072068 |958.64 |0.0010026 |
|27 |接受|0.47 |0.20485 |0.065 |0.07218 |993.69 |0.029723 |
|28 |接受|0.3 |0.11989 |0.065 |0.072291 |993.15 |170.01 |
| 29 |接受| 0.16 | 0.26983 | 0.065 | 0.072104 | 992.81 | 3.8594 |
|30 |接受|0.365 |0.13889 |0.065 |0.072112 |0.0010017 |0.044287 |
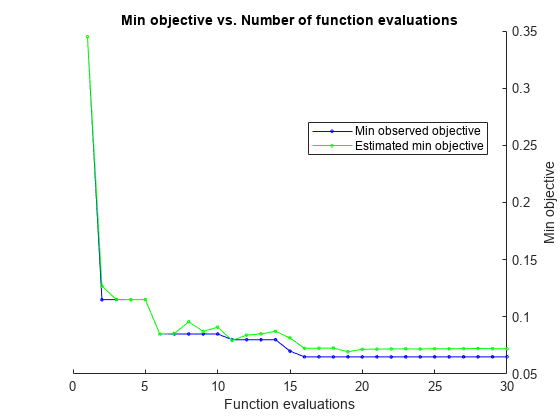
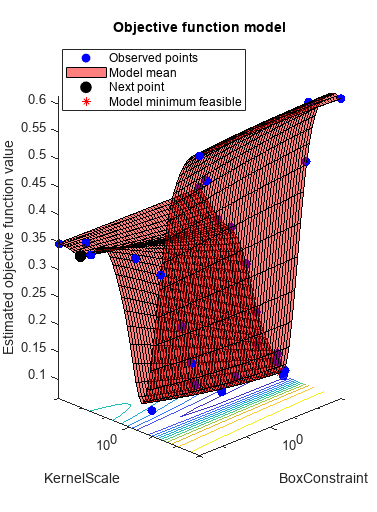
__________________________________________________________优化完成。MaxobjectiveEvaluations达到了30。总功能评价:30总的经过时间:70.975秒总目标函数评估时间:7.026最佳观察到的可行点:BoxConstraint KernelScale _____________ ___________ 953.22 0.26253观测目标函数值= 0.065估计目标函数值= 0.073726功能评估时间= 0.17852最佳估计可行点(根据型号):BoxConstraint KernelScale _____________ ___________ 985.37 0.27389估计目标函数值= 0.072112估计函数评估时间= 0.23449
svmmod = ClassificationSVM ResponseName:‘Y’CategoricalPredictors:[]类名:[1]ScoreTransform:“没有一个”NumObservations: 200 HyperparameterOptimizationResults: [1 x1 BayesianOptimization]α:[77 x1双]偏见:-0.2352 KernelParameters: [1 x1 struct] BoxConstraints: x1双[200]ConvergenceInfo: [1 x1 struct] IsSupportVector:万博1manbetx[200x1 logical] Solver: 'SMO'属性,方法
최적최적화된모델모델의손실을을
损失new = kfoldloss(fitcsvm(cdata,grp,'cvpartition',C,'骨箱'那'rbf'那......'BoxConstraint',svmmod.HyperParameterOptimationResults.xatminobjective.boxConstraint,......'kernelscale',svmmod.hyperParameterOptimationResults.xatminobjective.kernelscale)))
损失= 0.0650.
이손실은최적화결과에서관”측된목적함수값“아래에보고되는손실과동일합니다。
최적화된분류기를시각화합니다。
d = 0.02;[x1Grid, x2Grid] = meshgrid (min (cdata (: 1)): d:马克斯(cdata (: 1)),......min(cdata(:,2)):d:max(cdata(:,2)));xgrid = [x1grid(:),x2grid(:)];[〜,得分] =预测(SVMMOD,XGRID);图;h = nan(3,1);%preallocation.h(1:2)= g箭偶(CDATA(:,1),CDATA(:,2),GRP,'rg'那'+ *');抓住在h(3)= plot(cdata(svmmod.iss万博1manbetxupportvector,1),......cdata(svmmod.is万博1manbetxsupportvector,2),'KO');轮廓(x1grid,x2grid,重塑(分数(:,2),尺寸(x1grid)),[0 0],'K');传奇(H,{'-1'那'+1'那“万博1manbetx支持向量”},“位置”那'东南');轴平等的抓住从

SVM분류모델에대한사후확률영역영역플로팅
이예제에서는관측값으로구성그리드에서svm모델의사후확률예측그그리드에사후을을플로팅하는방법을보여사후확률을플로팅하면결정가분명해집니다。
피셔(Fisher)의붓꽃데이터세트를옵니다。꽃잎이와꽃잎너비를사용하여분류기를시키고데이터에서virginica종을합니다。
负载渔民类保留=〜strcmp(物种,'virginica');X = MEAS(classKeep,3:4);Y =物种(classKeep);
이데이터를사용하여svm분류기를훈련시킵니다。클래스의순서를지정하는이좋습니다。
svmmodel = fitcsvm(x,y,“类名”, {'setosa'那'versicolor'});
최적의점수변환함수를추정합니다。
rng (1);重复性的%[SvmModel,记分参数] = FitPosterior(SVMModel);
警告:类是完全分离的。最优积分后验变换是一个阶跃函数。
记分参数
记分节目=结构与字段:类型:“步骤”下行:-0.8431 Upperbound:0.6897 PositiveClassProbability:0.5000
클래스는분리가능하기때문에최적의점수변환함수는계단함수입니다。记分参数의필드下界와上行는클래스분리초평면(마진)내에서관측값에되는점수구간하한끝점과상한을을나타냅니다을을나타냅니다。어떠한훈련관측값도이마진내에속하지않습니다。새점수가구간내에있으면소프트웨어소프트웨어가대응되는관측값을양성사후확률,즉记分参数의PositiveClassProbability필드의값에할당합니다。
관측된예측변수공간에서값의그리드를정의합니다。그리드의각인스턴스에사후확률을예측합니다。
xmax = max(x);xmin = min(x);d = 0.01;[x1grid,x2grid] = meshgrid(xmin(1):d:xmax(1),xmin(2):d:xmax(2));[〜,posteriorregion] =预测(svmmodel,[x1grid(:),x2grid(:)]);
양성클래스사후확률영역과훈련데이터를플로팅합니다。
图;contourf(x1grid,x2grid,......REPAPE(posteriorregion(:,2),尺寸(x1grid,1),尺寸(x1grid,2)));h =彩色杆;H.Label.String =.'p({\它{versicolor}})';h.ylabel.fontsize = 16;caxis([01]);COLOROMAP.喷射;抓住在G箭头(x(:,1),x(:,2),y,“mc”那“方式”,[15,10]);SV = X(SVMModel.Is万博1manbetxSupportVector,:);情节(SV(:,1),SV(:,2),'哟'那“MarkerSize”15,'行宽'2);轴紧的抓住从
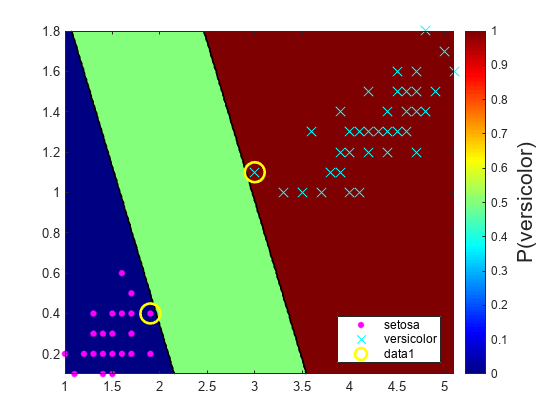
2-클래스학습에는클래스가분리가능한경우세개의영역영역영역에하나는관측값이양성클래스사후후0.을가지고,다른하나는1을가지며,나머지는양성클래스사전확률을가집니다。
선형서포트벡터머신을사용하여이미지분석분석
이예제에서는선형svm이진학습기로구성된오류출력(ecoc)모델모델훈련시켜이미지에서형상이차지차지사분면이무엇인지인지확인하는하는방법을보여줍니다보여보여보여보여이예제에서에서는서포트,해당레이블,추정추정 계수를저장하는ECOC모델의디스크공간사용량도보여줍니다。
데이터세트세트생성
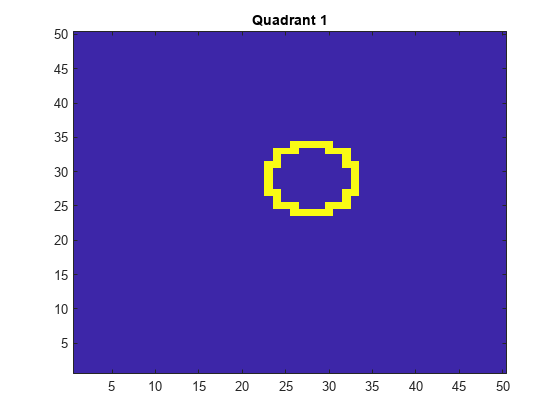
50×50이미지에반지름이5인원을임의로합니다。5000개이미지를를생성。이차지하는에이차지사분면을나타내는이블레을생성。1사분면은오른쪽위있고,2사분면은왼쪽왼쪽위에,3사분면은왼쪽아래있고,4사분면은오른쪽아래에。예측예측변수는각각픽셀의농도농도
d = 50;以像素为单位的图像的%高度和宽度n = 5e4;%样本大小x =零(n,d ^ 2);预测器矩阵预分配Y = 0 (n, 1);%标签preallocation.θ= 0:(1 / d):(2 *π);r = 5;%圆半径rng (1);重复性的%为j = 1:n fimmat =零(d);%空镜像C =数据征((r + 1):( d - r - 1),2);%随机圆心x = r * cos(θ)+ c(1);%制作圆圈Y = R * SIN(THETA)+ C(2);IDX = sub2ind([d d],圆(y)时,圆的(X));%转换为线性索引figmat(IDX)= 1;%画圆x(j,:) = fimmat(:);%存储数据Y(j)的=(C(2)> =地板(d / 2))+ 2 *(C(2)<地板(d / 2))+......(c(1)<楼层(d / 2))+......2 *((c(1)> =楼层(d / 2))&(c(2)<楼层(d / 2)));%确定象限结尾
관측값을플로팅합니다。
图于imagesc(figmat)H = GCA;H.YDIR =.'普通的';标题(Sprintf('Quadrant%d',y(结束))))
ecoc모델모델훈련
25%홀드아웃표본을사용하여훈련표본인덱스와홀드아웃표본인덱스를지정합니다。
P = 0.25;CVP = cvpartition(Y,'坚持',P);%交叉验证数据分区Isidx =培训(CVP);%培训样本指标oosIdx =测试(CVP);%测试样品指标
이진학습기학습기의서포트벡터를저장하도록지정하는svm템플릿을생성합니다。이템플릿과템플릿과데이터를fitcecoc.로전달하여모델을훈련시킵니다。훈련표본의분류오차를확인합니다。
t = templatesvm('save万博1manbetxsupportVectors',真正的);mdlsv = fitcecoc(x(isidx,:),y(isidx),'学习者't);isLoss = resubLoss (MdlSV)
isLoss = 0
mdlsv.는훈련된ClassificationECOC다중클래스모델입니다。이는훈련데이터와각이진학습기학습기의서포트를를합니다합니다。이미지분석의데이터세트세트와같은대규모대규모이터세트의경우,이모델은많은메모리를사용할수있습니다。
ecoc모델이사용하는디스크공간의를확인합니다。
Infomdlsv = whos('mdlsv');MBMDLSV = INFOMDLSV.BYTES / 1.049E6
mbMdlSV = 763.6151
이모델은763.6MB를사용용。
모델의효율성향상시키기
표본외성과를평가할수있습니다。또한,모델이서포트벡터,관련모수,훈련데이터를포함하지않는간소화된모델로과적합되었는지여부도평가할수있습니다。
훈련된ecoc모델모델에서서포트벡터와관련모수를를삭제그런다음,袖珍的를사용하여결과로된모델에서훈련데이터를를삭제삭제삭제를삭제삭제
MDL = Discard万博1manbetxSupportVectors(MDLSv);cmdl = compact(mdl);信息= whos('mdl'那'CMDL');[bytesCMdl,bytesMdl] = info.bytes;memReduction = 1 - [bytesMdl bytesCMdl] /infoMdlSV.bytes
擒矩=1×20.0626 0.9996
이경우,서포트서포트를삭제하면사용량이약6%정도줄어듭니다。서포트벡터를간소화하고삭제삭제크기크기가약99.96%줄어듭니다。
서포트벡터를관리하는다른방법은100과같은더큰상자제약조건을지정하여훈련과정중에그개수를줄이는것입니다。더적은수의서포트벡터를사용하는SVM모델이더바람직하고메모리를덜사용하지만상자제약조건의값을늘리면훈련시간이늘어나는경향이있습니다。
작업공간에서mdlsv.와Mdl을을합니다。
清除Mdlmdlsv.
홀드아웃표본성능가하기
홀드아웃표본의분류오차를계산합니다。홀드아웃표본예측의표본을플로팅합니다。
oosLoss =损耗(CMDL,X(oosIdx,:),Y(oosIdx))
oosLoss = 0
yhat =预测(cmdl,x(oosidx,:));nvec = 1:尺寸(x,1);OOSIDX = NVEC(OOSIDX);图;为j = 1:9子图(3,3,j)映射(reshape(x(x(oosidx(j),:)),[d d])h = gca;H.YDIR =.'普通的';标题(Sprintf('象限:%d',yhat(j))))结尾文本(-1.33 * d,4.5 * d + 1,'预测'那'字体大小'17)

이모델은은어떠한홀드홀드아웃표본관측값도오분류하지
참고항목
관련항목
참고문헌
[1] Hastie,T.,R. Tibshirani和J. Friedman。统计学习的要素,第二版。纽约:斯普林斯,2008年。
[2] Christianini,N.,和J. Shawe-泰勒。简介支持向量机和其他基于内核的学习方法万博1manbetx。剑桥,英国:剑桥大学出版社,2000年出版社。
[3]球迷,R.-E。,林志信。陈,C.-J。林。使用二阶信息进行训练支持向量机的工作集选择万博1manbetx机器学习研究杂志,2005年第6卷,1889-1918页。
凯克曼V., T. -M。和M. Vogt。从大数据集训练核机的迭代单数据算法:理论与性能支持向万博1manbetx量机:理论与应用。王力波主编,255-274。柏林:斯普林格出版社,2005年版。
您还可以从以下列表中选择一个网站:
