加固学习工具箱
使用强化学习设计和培训政策
强化学习工具箱™提供了一个应用程序、函数和一个Simulink万博1manbetx®使用强化学习算法的培训政策阻止,包括DQN,PPO,SAC和DDPG。您可以使用这些策略来实现用于复杂应用程序的控制器和决策算法,例如资源分配,机器人和自主系统。
该工具箱允许您使用深度神经网络或查找表来表示策略和价值函数,并通过与MATLAB中建模的环境交互来训练它们®或仿真万博1manbetx软件。您可以评估工具箱中提供的单或多智能体强化学习算法,也可以开发自己的算法。您可以试验超参数设置,监控训练进度,并通过应用程序或编程方式交互模拟训练过的代理。为了提高训练性能,仿真可以在多个cpu、gpu、计算机集群和云(使用并行计算工具箱™和MATLAB并行服务器™)上并行运行。
通过ONNX™模型格式,现有的策略可以从TensorFlow™Keras和PyTorch (with deep learning Toolbox™)等深度学习框架中导入。您可以生成优化的C、c++和CUDA®用于部署微控制器和GPU的培训策略的代码。工具箱包含参考示例,以帮助您开始。
开始:


强化学习算法
使用深度Q-network (DQN)、深度确定性策略梯度(DDPG)、近端策略优化(PPO)等内置算法创建代理。使用模板为培训策略开发定制代理。

训练算法可在强化学习工具箱。


Simulink中的单agent和多agent强化学习万博1manbetx
在Simulink中使用RL Agent块创建和训练强化学习Agent。万博1manbetx在Simulink中使用RL Agent块的多个实例同时训练多个Agent(多Agent强化学习)。万博1manbetx

Simulink的加强学习代理块。万博1manbetx
万博1manbetxSimulink和Simscape环境
使用Si万博1manbetxmulink和Simscape™创建环境模型。在模型中指定观察、行动和奖励信号。

万博1manbetx用于Biped机器人的Simulink环境模型。
Matlab环境
使用MATLAB函数和类来模拟环境。在MATLAB文件中指定观察,操作和奖励变量。

三自由度火箭的MATLAB环境。
分布式计算和多核加速
通过在多核计算机、云资源或计算集群上运行并行模拟来加速训练并行计算工具箱和MATLAB并行服务器.

使用并行计算加速训练。
GPU加速
高性能NVIDIA加快深度神经网络培训和推论®GPU。使用matlab并行计算工具箱和最支持的CUDA启用的NVIDIA GPU计算能力3.0及以上.

使用gpu加速训练。
代码生成
使用GPU编码器™从表示训练策略的MATLAB代码中生成优化的CUDA代码。使用Matlab Coder™生成C / C ++代码以部署策略。

使用GPU编码器生成CUDA代码。
Matlab编译器支持万博1manbetx
使用MATLAB编译器™和MATLAB编译器SDK™将培训的策略部署为独立应用程序,C / C ++共享库,Microsoft®net程序集,Java®课程和python®包。

将策略打包和共享为独立的程序。
入门
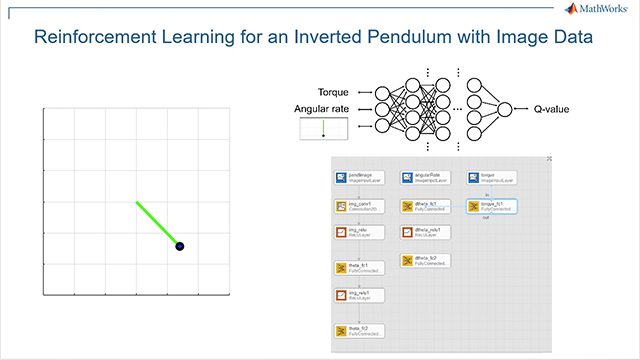
了解如何为一些问题制定强化学习策略,如倒立一个简单的钟摆、导航一个网格世界、平衡一个拉杆系统和解决一般的马尔可夫决策过程。
自动驾驶
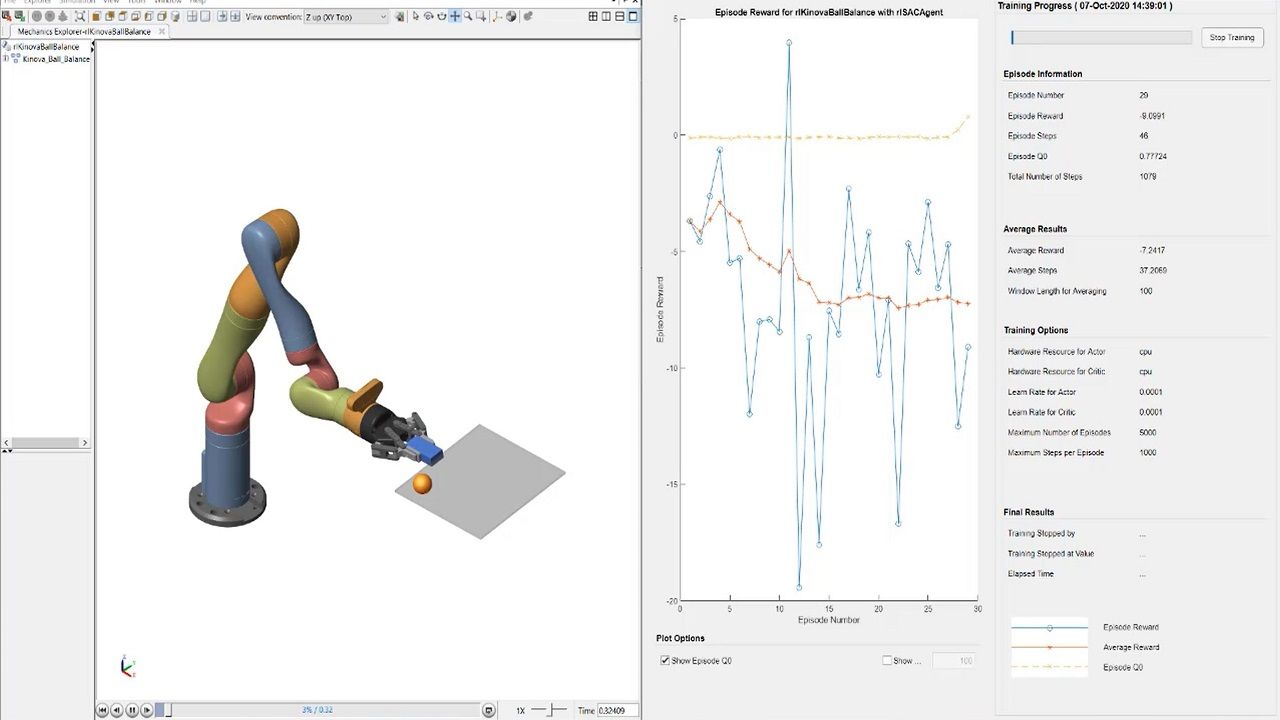
设计加强学习政策,自动驾驶应用,如自适应巡航控制,车道保持援助和自动停车。


水资源分配中的资源分配问题。

