基于深度学习的噪声中语音活动检测
在本例中,您使用预训练的深度学习模型在低信噪比环境中执行批处理和流式语音活动检测(VAD)。有关该模型及其训练方式的详细信息,请参见利用深度学习训练噪声模型中的语音活动检测.
加载和检查数据
读入一段包含有停顿的单词的音频文件,然后听一听。使用重新取样将信号重新采样到16千赫的采样率。使用detectSpeech对洁净信号确定地真语音区域。
Fs = 16e3;[speech,fileFs] = audioread(“Counting-16-44p1-mono-15secs.wav”);speech = resample(speech,fs,fileFs);Speech = Speech ./max(abs(Speech));声音(演讲中,fs) detectSpeech(演讲、fs、窗口=汉明(0.04 * fs,“周期”), MergeDistance =圆(0.5 * fs))

加载一个噪声信号和重新取样到音频采样率。
[noise,fileFs] = audioread(“洗衣机- 16 - 8 mono - 200 - secs.mp3”);noise = resample(noise,fs,fileFs);
使用支持函数万博1manbetxmixSNR用洗衣机噪音以所需的信噪比水平(以dB为单位)破坏干净的语音信号。收听损坏的音频。在-10 dB信噪比条件下训练网络。
信噪比= -10;noisySpeech = mixSNR(语音,噪声,信噪比);声音(noisySpeech fs)
-10;noisySpeech = mixSNR(语音,噪声,信噪比);声音(noisySpeech fs)

基于算法的VAD,detectSpeech,在这些噪声条件下失效。
detectSpeech (noisySpeech fs =汉明窗(0.04 * fs,“周期”), MergeDistance =圆(0.5 * fs))
下载预训练网络
下载并加载预先训练好的网络和配置好的网络audioFeatureExtractor对象。该网络被训练来检测低信噪比环境下的语音audioFeatureExtractor对象。
downloadFolder = matlab.internal.examples.download万博1manbetxSupportFile(“音频”,“VoiceActivityDetection.zip”);dataFolder = tempdir;unzip(下载文件夹,数据文件夹)netFolder = fullfile(数据文件夹,数据文件夹)“VoiceActivityDetection”);pretrainedNetwork = load(fullfile(netFolder,“voiceActivityDetectionExample.mat”));afe =预训练网络;net = pretrainedNetwork.speechDetectNet;
的audioFeatureExtractor对象配置为从256个样本窗口中提取特征,其中128个样本在窗口之间重叠。在16 kHz采样率下,从16 ms窗口中提取特征,重叠8 ms。从每个窗口,audioFeatureExtractor对象提取了9个特征:谱质心、谱波峰、谱熵、谱通量、谱峰度、谱滚脱点、谱偏度、谱斜率和谐波比。
afe
afe = audioFeatureExtractor with properties: properties Window: [256×1 double] OverlapLength: 128 SampleRate: 16000 FFTLength: [] SpectralDescriptorInput: 'linearSpectrum' FeatureVectorLength:9启用特征spectralCentroid, spectralCrest, spectralEntropy, spectralFlux, spectral峰度,spectralRolloffPoint spectralSkewness, spectralSlope, harmonicRatio禁用特征linearSpectrum, melSpectrum, barkSpectrum, erbSpectrum, mfcc, mfccDelta mfccDeltaDelta, gtcc, gtccDelta, gtccDeltaDelta, spectralreduce, spectralFlatness spectralSpread, pitch, zerocrossrate, shortTimeEnergy提取一个特征,将相应的属性设置为true。例如,obj。MFCC = true,将MFCC添加到启用的特性列表中。
该网络由两个双向LSTM层组成,每个层有200个隐藏单元,以及一个分类输出,返回对应于未检测到语音活动的类0或对应于检测到语音活动的类1。
网层
ans = 6×1层数组:1' sequenceinput'序列输入序列输入与9个维度2' biLSTM_1' BiLSTM BiLSTM与200个隐藏单元3 'biLSTM_2' BiLSTM BiLSTM与200个隐藏单元4 'fc'全连接2全连接层5 'softmax' softmax softmax 6 'classoutput'分类输出crossentropyex与类'0'和'1'
执行语音活动检测
从语音数据中提取特征并进行标准化。定位特征,使时间跨列。
features = extract(afe,noisySpeech);Features = (Features - mean(Features,1))./std(Features,[],1);Features = Features ';
将特征通过语音检测网络,对每个特征向量进行分类,判断是否属于某个语音帧。
decisionsCategorical =分类(网络,特征);
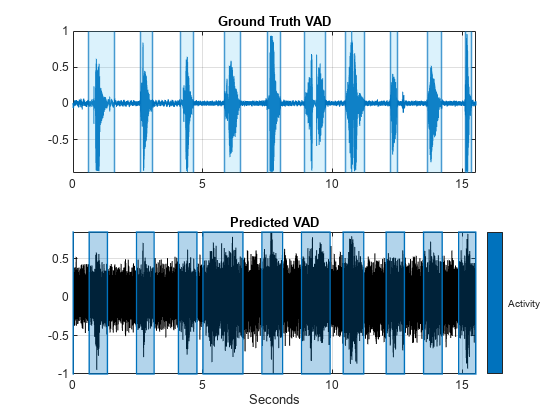
对象分析的一个分析窗口对应于每个决策audioFeatureExtractor.复制决策,使它们与音频样本一一对应。使用detectSpeech便利阴谋阴谋地真相。使用signalMask而且plotsigroi来绘制预测的VAD。
decisions = (double(decisionsCategorical) - 1)';decisionsPerSample = [decisions(1:round(number (afe.Window)/2));repelem(decisions,numel(afe.Window)-afe.OverlapLength,1)];tiledlayout(2,1) nexttile detectSpeech(speech,fs,Window=汉明(0.04*fs,“周期”), MergeDistance =圆(0.5 * fs))标题(“Ground Truth VAD”)包含(""nexttile mask = signalMask(decisionsPerSample,SampleRate=fs,Categories=“活动”);plotsigroi(面具,noisySpeech,真正的)标题(“预测和监督”)
执行流式语音活动检测
的audioFeatureExtractor对象用于批处理,并且在调用之间不保留状态。使用generateMATLABFunction创建一个流友好的特征提取器。您可以在流环境中使用经过训练的VAD网络classifyAndUpdateState(深度学习工具箱).
generateMATLABFunction (afe“featureExtractor”IsStreaming = true)
为了模拟流环境,将语音和噪声信号保存为WAV文件。为了模拟流输入,您将使用dsp。AudioFileReader从文件中读取帧,并以所需的信噪比混合它们。你也可以使用audioDeviceReader麦克风就是语音源。
audiowrite (“Speech.wav”演讲中,fs) audiowrite (“Noise.wav”、噪音、fs)
定义噪声演示中流语音活动检测的参数:
信号-信号源,指定为先前录制的演讲文件,或您的麦克风。噪音-噪声源,指定为与信号混合的噪声声音文件。信噪比-混合信号和噪声的信噪比,单位为dB。testDuration—测试持续时间,单位为秒。playbackSource—回放源,指定为原始干净信号、噪声信号或检测到的语音。一个audioDeviceWriter对象用于向扬声器播放音频。
信号=“Speech.wav”;噪音=“Noise.wav”;信噪比=
-10;% dBtestDuration =
20.;%秒playbackSource =
“吵”;




调用支持函数万博1manbetxstreamingDemo观察VAD网络在流音频上的性能。使用实时控件设置的参数不会中断流示例。在流演示完成后,您可以修改演示的参数,然后再次运行流演示。
afe streamingDemo(净,...信号,噪声,信噪比,...testDuration playbackSource);

参考文献
狱长P。“语音命令:用于单词语音识别的公共数据集”,2017年。可以从https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz.版权所有谷歌2017。语音命令数据集是在创作共用属性4.0许可下授权的
万博1manbetx支持功能
流媒体演示
函数streamingDemo(净,afe、信号、噪声、信噪比、testDuration, playbackSource)% streamingDemo(net,afe,signal,noise,SNR,testDuration,playbackSource)运行%实时VAD演示。创建dsp。AudioFileReader对象用于读取语音和噪声文件帧% by帧。如果语音信号指定为“麦克风”,请使用% audioDeviceReader作为源。如果strcmpi(信号,“麦克风”) speechReader = audioDeviceReader(afe.SampleRate);其他的语音阅读器= dsp.AudioFileReader(信号,PlayCount=inf);结束noiseReader = dsp.AudioFileReader(noise,PlayCount=inf,SamplesPerFrame=speechReader.SamplesPerFrame);fs = speechReader.SampleRate;创建dsp。MovingStandardDeviation对象和dsp。MovingAverage%的对象。您将使用这些来确定标准偏差和平均值%的音频功能进行标准化。统计数据应该有所改善%随时间变化。movSTD = dsp。MovingStandardDeviation(方法=“指数权重”ForgettingFactor = 1);movMean = dsp。MovingAverage(Method=“指数权重”ForgettingFactor = 1);创建dsp。MovingMaximum对象。您将使用它来标准化%的音频。movMax = dsp.MovingMaximum(specificwindowlength =false);创建dsp。MovingRMS对象。你将用它来确定信号%和噪声混合在所需的信噪比。此对象仅用于举例人为增加噪音的目的。movRMS = dsp。MovingRMS(方法=“指数权重”ForgettingFactor = 1);创建3个dsp。AsyncBuffer对象。一个用来缓冲输入音频,一个%用于缓冲提取的特征,一个用于缓冲输出的音频%的VAD决策对应于音频信号。输出缓冲区为只需要实时可视化决策。。audioInBuffer = dsp.AsyncBuffer(2*speechReader.SamplesPerFrame);featureBuffer = dsp.AsyncBuffer(ceil(2*speechReader.SamplesPerFrame/(numel(afe.Window)-afe.OverlapLength)));audioOutBuffer = dsp.AsyncBuffer(2*speechReader.SamplesPerFrame);创建一个时间范围来可视化原始语音信号,噪声%信号的网络应用,和决策输出从%网络。scope = timescope(SampleRate=fs,...TimeSpanSource =“财产”,...时间间隔= 3,...BufferLength = f * 3 * 3,...TimeSpanOverrunAction =“滚动”,...AxesScaling =“更新”,...MaximizeAxes =“上”,...AxesScalingNumUpdates = 20,...NumInputPorts = 3,...LayoutDimensions = (3,1),...ChannelNames = [《吵闹的演讲》,“廉洁演说(原文)”,“发现演讲”),......ActiveDisplay = 1,...ShowGrid = true,......ActiveDisplay = 2,...ShowGrid = true,......ActiveDisplay = 3,...ShowGrid = true);% #好< DUPNAMEARG >设置(范围、{1 1 1})创建一个audioDeviceWriter对象来播放原始或噪声%来自扬声器的音频。deviceWriter = audioDeviceWriter(SampleRate=fs);初始化循环中使用的变量。windowLength = numel(afe.Window);hopLength = windowLength - afe.OverlapLength;运行流演示。loopTimer = tic;而toc(loopTimer) < testDuration . toc读取一帧语音信号和一帧噪声信号speechIn = speechReader();noiseIn = noiseReader();以指定的信噪比将语音和噪声混合能量= movRMS([speechIn,noiseIn]);噪声增益= 10^(-SNR/20) *能量(end,1) /能量(end,2);noisyAudio = speechIn + noiseIn;更新运行最大值以缩放音频myMax = movMax(abs(noisyAudio));noisyAudio = noisyAudio/myMax(end);将有噪声的音频和语音写入缓冲区写(audioInBuffer [noisyAudio speechIn]);%如果音频缓冲区中有足够的样本来计算一个特征%向量,读取样本,归一化,提取特征%向量,并将最新的特征向量写入特征缓冲区。而(audioInBuffer。NumUnreadSamples >= hopLength) x = read(audioInBuffer,numel(afe.Window),afe.OverlapLength);写(audioOutBuffer x (end-hopLength + 1:,:));noisyAudio = x(:,1);features = featureExtractor(noisyAudio);写(featureBuffer、特点);结束如果featureBuffer。NumUnreadSamples >= 1%按未读数读取音频数据%特征向量。audioHop = read(audioOutBuffer,featureBuffer.NumUnreadSamples*hopLength);读取所有未读特征向量。features = read(featureBuffer);只使用新的特征来更新标准偏差和%的意思。标准化特征。rmean = movMean(特征);rstd = movSTD(特征);Features = (Features - rmean(end,:)) ./ rstd(end,:);网络推断[net,decision] = classifyAndUpdateState(net,features');%将每个特征向量的决策转换为每个样本的决策decision = repelem(decision,hopLength,1);在嘈杂的讲话上加一个遮罩,使声音更清晰。vadResult = audioHop(:,1);vadResult(decision==categorical(0)) = 0;听演讲或演讲+噪音开关playbackSource情况下“清洁”deviceWriter (audioHop (:, 2));情况下“吵”deviceWriter (audioHop (: 1));情况下“detectedSpeech”deviceWriter (vadResult);结束视觉化演讲+噪音,原始演讲和声音。%活动检测。范围(audioHop (: 1), audioHop (:, 2), vadResult)结束结束结束
混合信噪比
函数[noissignal, requestdnoise] = mixSNR(信号,噪声,比率)% [noissignal, requestdnoise] = mixSNR(信号,噪声,比率)返回一个噪声%版本的信号,noisyssignal。有噪声的信号被混入了%的噪音,以分贝为单位。numSamples = size(信号,1);将噪声转换为单声道噪声=均值(噪声,2);修剪或扩大噪声以匹配信号大小如果大小(噪音,1)> = numSamples选择一个随机的起始索引,这样您仍然有numSamples%后索引噪声。start = randi(size(noise,1) - numSamples + 1);noise = noise(start:start+numSamples-1);其他的numReps = ceil(numSamples/size(noise,1));temp = repmat(noise,numReps,1);start = randi(size(temp,1) - numSamples - 1);noise = temp(start:start+numSamples-1);结束signalNorm = norm(信号);noiseNorm = norm(噪声);goalNoiseNorm = signalNorm/(10^(ratio/20));factor = goalNoiseNorm/noiseNorm;requestdnoise =噪音。*因子;noisyssignal =信号+请求噪声;noisyssignal = noisyssignal ./max(abs(noisyssignal));结束
您也可以从以下列表中选择一个网站: