估计
适用于数据的自回归综合移动平均(ARIMA)模型
描述
[也返回与所估计的参数相关联的方差 - 协方差矩阵estmdl.,estparamcov.,logl.,信息] =估计(___)estparamcov.的,优化的对数似然的目标函数值logl.和摘要信息信息,使用前面语法中的任何输入参数组合。
例子
估计ARMA模型
适合的ARMA(2,1)模型来模拟数据。
从已知模型模拟数据
假设数据生成处理(DGP)是
在哪里 为一系列iid高斯随机变量,均值为0,方差为0.1。
创建表示DGP的ARMA(2,1)模型。
文章= arima (基于“增大化现实”技术的,{0.5,-0.3},'嘛',0.2,......'持续的',0,'方差',0.1)
描述:“arima(2,0,1)模型(高斯分布)”分布:Name = "Gaussian" P: 2 D: 0 Q: 1 Constant: 0 AR: {0.5 -0.3} at lag [1 2] SAR: {} MA: {0.2} at lag [1] SMA:{}季节性:0 Beta: [1×0] Variance: 0.1 .
文章是完全指定的阿玛玛模型对象。
模拟从ARMA(2,1)模型的随机500观察路径。
rng (5);重复性的%t = 500;Y =模拟(DGP,T);
Y是一个500×1列矢量,代表来自ARMA(2,1)模型的模拟响应路径文章.
估计模型
创建ARMA(2,1)模型模板进行估计。
Mdl = arima (0, 1)
MDL = Arima具有属性:描述:“Arima(2,0,1)模型(高斯分布)”分布:名称=“高斯”P:2 D:0 Q:1常数:南ar:{南南}在滞后[1 2] SAR:{} ma:{nan}在Lag [1] sma:{}季节性:0 beta:[1×0]方差:南
MDL.被部分指明的阿玛玛模型对象。决定模型结构只要求,nonestimable参数指定。南- 估计属性,包括
,
,
,
, 和
,是要估计的未知模型参数。
符合ARMA(2,1)模型y.
EstMdl =估计(Mdl, y)
ARIMA(2,0,1)模型(高斯分布):值StandardError的TStatistic p值_________ _____________ __________ __________常数0.0089018 0.018417 0.48334 0.62886 AR {1} 0.49563 0.10323 4.8013 1.5767e-06 AR {2} -0.25495 0.070155 -3.6341 0.00027897 MA {1} 0.27737 0.10732 2.5846 0.0097492方差0.10004 0.0066577 15.027 4.9017e-51
ESTMDL = ARIMA具有属性:“ARIMA(2,0,1)模型(高斯分布)”分布:名称=“高斯”P:2 D:0 Q:1常数:0.00890178 AR:{0.495632 -0.254951} ATLAG [1 2] SAR:{} MA:{0.27737}在LAG [1] SMA:{}季节性:0β:[1×0]方差:0.100043
MATLAB®显示包含的估计总结,其中包括参数估计和推断的表。例如,价值列包含对应的最大似然估算,和pvalue.列包含
- 值的渐近
- 最低假设,即相应的参数为0。
estmdl.是完全指明的,估计阿玛玛模型对象;它的估计类似于DGP的参数值。
在估计过程中对参数应用等式约束
适合的AR(2)模型来模拟的数据,同时保持估计期间固定模型恒定。
从已知模型模拟数据
假设DGP是
在哪里 为一系列iid高斯随机变量,均值为0,方差为0.1。
创建表示DGP的AR(2)的模型。
文章= arima (基于“增大化现实”技术的,{0.5,-0.3},......'持续的',0,'方差',0.1);
从模拟模型中的随机观察500路径。
rng (5);重复性的%t = 500;Y =模拟(DGP,T);
创建模型对象指定约束
假定平均的 是0吗 是0。
创建一个AR(2)估计模型。放 到0。
mdl =阿里马('ARLags',1:2,'持续的',0)
MDL = ARIMA模型属性:描述: “ARIMA(2,0,0)模型(高斯分布)” 分布:名称= “高斯” P:2 d:0问:0常数:0 AR:{楠楠}在滞后[1 2] SAR:{} MA:{} SMA:{}季节性:0贝塔:[1×0]方差:NaN的
MDL.被部分指明的阿玛玛模型对象。指定的参数包括所有必需的参数和模型常量。南- 估计属性,包括
,
, 和
,是要估计的未知模型参数。
估计模型
适合AR包含约束(2)模型模板y.
EstMdl =估计(Mdl, y)
ARIMA(2,0,0)模型(高斯分布):价值标准误差Tstatistic pvalue _______________________________常数0 0 NaN NaN AR {1} 0.56342 0.044225 12.74 3.5474E-37 AR {2} -0.29355 0.04178C-0.29355 0.041784 -0-30-12方差0.10022 0.006644 15.085 2.0476E-51
描述:“arima(2,0,0)模型(高斯分布)”分布:Name = "Gaussian" P: 2 D: 0 Q: 0 Constant: 0 AR: {0.563425 -0.293554} at lag [1 2] SAR: {} MA: {} SMA:{}季节性:0 Beta: [1×0] Variance: 0.100222 . (x = 0
estmdl.是完全指明的,估计阿玛玛模型对象;其估计类似于AR(2)模型的参数值文章.的价值
在估计总结和对象显示是0,并且相应的推论是微不足道的或不适用。
初始化模型估计使用样品前响应数据
因为一个ARIMA模型是以前的值的函数,估计需要预先定位数据以提前在采样期间初始化模型。虽然,估计在默认情况下样品前数据backcasts,您可以指定所需的样品前数据,而不是。这P一个物业阿玛玛模型对象指定所需数量的样品前体的观察。
加载数据
加载美国股票指数数据集data_equityidx..
加载data_equityidx.
桌子数据表包括时间序列的可变纽约证券交易所,它通过1995年12月包含每天,纽约证券交易所综合收盘价从1990年1月。
将表格转换为一个时间表。
dt = datetime(日期,'vectormfrom','数据内容','格式','yyyy-mm-dd');TT = table2timetable(数据表,'rowtimes',dt);T =尺寸(TT,1);%总样本大小
创建模型模板
假设一个ARIMA(1,1,1)模型是适当的,在采样期间,以NYSE复合系列建模。
创建估计的ARIMA(1,1,1)模型模板。
MDL = Arima(1,1,1)
MDL = ARIMA模型属性:描述: “ARIMA(1,1,1)模型(高斯分布)” 分布:名称= “高斯” P:2 d:1 Q:1常数:NaN的AR:{}的NaN在滞后[1] SAR:{} MA:{}的NaN在滞后[1] SMA:{}季节性:0贝塔:[1×0]方差:NaN的
MDL.被部分指明的阿玛玛模型对象。
分区的样本
该分区的样品进入样品前体和估计的采样周期,从而使样品前体发生第一和包含创建索引的矢量mdl.p.=2观察,估计样品中含有剩余的观察结果。
样品前体= 1:Mdl.P;estsample =(Mdl.P + 1):T;
估计模型
适合的ARIMA(1,1,1)模型来估计样品。指定预先响应。
estmdl =估计(mdl,tt {estsample,“纽约证券交易所”},'y0',TT {样品前体,“纽约证券交易所”});
ARIMA(1,1,1)模型(高斯分布):值StandardError的TStatistic p值________ _____________ __________ _______常数0.15775 0.097888 1.6115 0.10706 AR {1} -0.21985 0.15652 -1.4046 0.16015 MA {1} 0.28529 0.15393 1.8534 0.06382方差17.17 0.20065 85.573 0
estmdl.是完全指明的,估计阿玛玛模型对象。
指定优化初始参数值
将Arima(1,1,1)模型适合纽约证券交易所综合指数的日常关闭。指定从导频示例的分析获得的初始参数值。
加载数据
加载美国股票指数数据集data_equityidx..
加载data_equityidx.
桌子数据表包括时间序列的可变纽约证券交易所,它通过1995年12月包含每天,纽约证券交易所综合收盘价从1990年1月。
将表格转换为一个时间表。
dt = datetime(日期,'vectormfrom','数据内容','格式','yyyy-mm-dd');TT = table2timetable(数据表,'rowtimes',dt);
适合模型到试点样品
假设一个ARIMA(1,1,1)模型是适当的,在采样期间,以NYSE复合系列建模。
创建估计的ARIMA(1,1,1)模型模板。
Mdl = arima (1, 1, 1);
MDL.被部分指明的阿玛玛模型对象。
治疗前两年作为用于拟合模型到剩余三年的数据时,获得初始参数值的导频样本。拟合模型的导频样本。
EndPilot = DateTime(1991,12,31);pilottr = timerange(tt.time(1),EndPilot,'天');EstMdl0 =估计(MDL,TT {pilottr,“纽约证券交易所”},'展示','离开');
EstMdl0是完全指明的,估计阿玛玛模型对象。
估计模型
适合的ARIMA(1,1,1)模型来估计样品。指定从先导样品适合作为用于优化的初始值估计的参数。
esttr = TIMERANGE(endPilot +天(1),TT.Time(结束),'天');C0 = EstMdl0.Constant;AR0 = EstMdl0.AR;MA0 = EstMdl0.MA;var0 = EstMdl0.Variance;EstMdl =估计(MDL,TT {esttr,“纽约证券交易所”},“Constant0”,C0,“AR0”,AR0,......'ma0',MA0,'variance0',var0);
ARIMA(1,1,1)模型(高斯分布):值StandardError的TStatistic p值_______ _____________ __________ _______常数0.17424 0.11648 1.4959 0.13468 AR {1} -0.2262 0.18587 -1.217 0.22362 MA {1} 0.29047 0.18276 1.5893 0.11199方差20.053 0.27603 72.65 0
estmdl.是完全指明的,估计阿玛玛模型对象。
估计含有外源预测器的Arima模型(Arimax)
适合的ARIMAX模型模拟的时间序列数据。
模拟预测器和响应数据
为DGP创建ARIMAX(2,1,0)模型,表示 在等式中
在哪里 为一系列iid高斯随机变量,均值为0,方差为0.1。
文章= arima (基于“增大化现实”技术的,{0.5,-0.3},'D',1,'持续的'2,......'方差',0.1,'beta',[1.5 2.6-0.3]);
假定外生变量 , , 和 由AR(1)表示的流程
在哪里 服从高斯分布,均值为0,方差为0.01 .创建ARIMA模型代表的外生变量。
mdlx1 = Arima(基于“增大化现实”技术的,0.1,'持续的',0,'方差', 0.01);mdlx2 = Arima(基于“增大化现实”技术的,0.2,'持续的',0,'方差', 0.01);mdlx3 = Arima(基于“增大化现实”技术的,0.3,'持续的',0,'方差', 0.01);
模拟长度1000从AR模型外源性系列。在矩阵存储模拟数据。
T = 1000;rng (10);重复性的%X1 =模拟(MdlX1,T);X2 =模拟(MdlX2,T);X3 =模拟(MdlX3,T);X = [X1 X2 X3的];
X是模拟时间序列数据的1000×3矩阵。每行对应于时间序列中的观察,并且每列对应于外源变量。
模拟的长度从DGP 1000系列。指定模拟外生数据。
y =模拟(文章,T,'X',X);
y是1000×1响应数据矢量矢量图。
估计模型
创建Arima(2,1,0)模型模板进行估计。
MDL = Arima(2,1,0)
描述:“arima(2,1,0)模型(高斯分布)”分布:Name = "Gaussian" P: 3 D: 1 Q: 0 Constant: NaN AR: {NaN NaN} at lag [1 2] SAR: {} MA: {} SMA:{}季节性:0 Beta: [1×0] Variance: NaN . (n
模型描述(描述属性)和值bet表明部分规定阿玛玛模型对象MDL.是外部预测因素的不可知论者。
估计Arimax(2,1,0)模型;指定外源性预测器数据。因为估计对预样本响应(一个过程,需要预样本预测数据的ARIMAX模型)进行回投,使模型适合最新的t - mdl.p.回复。(或者,您也可以通过使用指定样品前回应'y0'名称值对参数。)
EstMdl =估计(Mdl y (Mdl。P + 1): T)'X',X);
ARIMAX(2,1,0)模型(高斯分布):值StandardError TStatistic PValue ________ _____________ __________ ___________ Constant 1.7519 0.021143 82.859 0 AR{1} 0.56076 0.016511 33.963 7.9439e-253 AR{2} -0.26625 0.015966 -16.676 1.9633e-62 Beta(1) 1.4764 0.10157 14.536 7.1231e-48 Beta(2) 2.5638 0.10445 24.547 4.6651e-133 Beta(3) -0.34422 0.098623 -3.4903 0.00048249方差0.106730.0047273 22.577 7.3169 e - 113
estmdl.是完全指明的,估计阿玛玛模型对象。
当你用估计并通过指定供应外生数据'X'名称-值对参数,MATLAB®将模型识别为ARIMAX(2,1,0)模型,并包括外生变量的线性回归组件。
估计的模型是
它类似于DGP表示由Mdl0.因为MATLAB返回在差异方程表示法中表达的模型的AR系数,所以它们的迹象在等式中相反。
计算估计的标准误差
加载美国股票指数数据集data_equityidx..
加载data_equityidx.
桌子数据表包括时间序列的可变纽约证券交易所,它通过1995年12月包含每天,纽约证券交易所综合收盘价从1990年1月。
将表格转换为一个时间表。
dt = datetime(日期,'vectormfrom','数据内容','格式','yyyy-mm-dd');TT = table2timetable(数据表,'rowtimes',dt);
假设一个ARIMA(1,1,1)模型是适当的,在采样期间,以NYSE复合序列模型
将Arima(1,1,1)模型适合数据,并返回估计的参数协方差矩阵。
Mdl = arima (1, 1, 1);[estmdl,estparamcov] =估计(mdl,tt {:,“纽约证券交易所”});
ARIMA(1,1,1)模型(高斯分布):值StandardError的TStatistic p值________ _____________ __________ ________常数0.15745 0.097831 1.6094 0.10753 AR {1} -0.21996 0.15642 -1.4062 0.15965 MA {1} 0.2854 0.15382 1.8554 0.063533方差17.159 0.20038 85.632 0
estparamcov.
estparamcov =4×4.0.0096 -0.0002 0.0002 0.0023 -0.0002 0.0245 -0.0240 -0.0060 0.0002 -0.0240 0.0237 0.0057 0.03 -0.0060 0.0057 0.0402
estmdl.是完全指明的,估计阿玛玛模型对象。的行和列estparamcov.对应于估计表中的行和推断;例如,
.
通过对协方差矩阵的对角元素取平方根来计算估计的参数标准误差。
estParamSE = SQRT(DIAG(EstParamCov))
estParamSE =4×10.0978 0.1564 0.1538 0.2004
计算基于WALD的95%置信区间 .
T =尺寸(TT,1);%有效样本容量phihat = EstMdl.AR {1};sephihat = estParamSE (2);ciphi = phhat + tinv([0.025 0.975],T - 3)* phhihat . ciphi = phhat + tinv([0.025 0.975],T - 3
CIPHI =1×2-0.5267 0.0867
间隔包含0,这表明了 是微不足道的。
计算拟合响应值
加载美国股票指数数据集data_equityidx..
加载data_equityidx.
桌子数据表包括时间序列的可变纽约证券交易所,它通过1995年12月包含每天,纽约证券交易所综合收盘价从1990年1月。
将表格转换为一个时间表。
dt = datetime(日期,'vectormfrom','数据内容','格式','yyyy-mm-dd');TT = table2timetable(数据表,'rowtimes',dt);T =尺寸(TT,1);
假设一个ARIMA(1,1,1)模型是适当的,在采样期间,以NYSE复合系列建模。
适合的ARIMA(1,1,1)模型的数据。指定所需的样品前体和关闭估计显示。
Mdl = arima (1, 1, 1);preidx = 1:mdl.p;estidx =(mdl.p + 1):t;estmdl =估计(mdl,tt {estidx,“纽约证券交易所”},......'y0', TT {preidx,“纽约证券交易所”},'展示','离开');
推断出残差 从估计的模型,指定所需的样品前。
REND =推断(ESTMDL,TT {estidx,“纽约证券交易所”},......'y0', TT {preidx,“纽约证券交易所”});
渣滓是一个(t - mdl.p.)×1残差矢量。
计算拟合值 .
yhat = tt {estidx,“纽约证券交易所”} - 渣油;
绘制在同一个图形的意见和拟合值。
绘图(tt.time(estidx),tt {estidx,“纽约证券交易所”},“r”,tt.time(estidx),yhat,'B--','行宽'2)
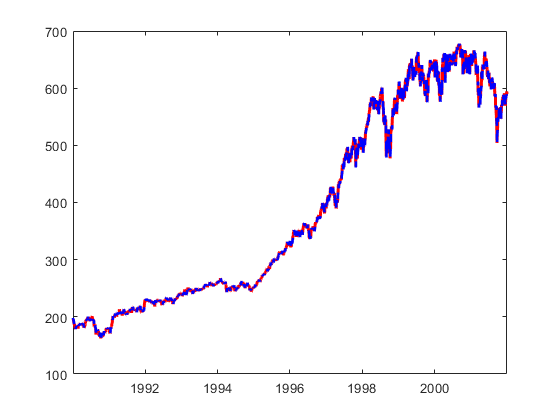
拟合值密切追踪观察结果。
绘制残差与拟合值的关系。
图(yhat,渣油,“。”)ylabel('残留')Xlabel('适合价值')
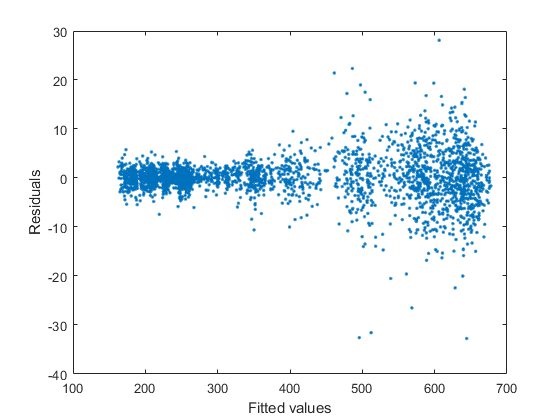
剩余方差出现较大的拟合值大。对该行为的一种补救方法是应用日志转换成数据。
输入参数
输出参数
算法
参考
[1]Box, George E. P., Gwilym M. Jenkins,和Gregory C. Reinsel。时间序列分析:预测和控制.3版。恩格尔伍德悬崖,NJ: Prentice Hall, 1994。
[2]沃尔特汉语。应用计量经济时间序列.新泽西州霍博肯市:John Wiley和Sons公司,1995年。
[3]格林,威廉。H。经济学分析.第6届。上马鞍河,NJ:Prentice Hall出版社,2008年。
[4]汉密尔顿,詹姆斯D.时间序列分析.普林斯顿,新泽:普林斯顿大学出版社,1994年。
另请参阅
对象
功能
您还可以从以下列表中选择一个网站:
