基于后期融合的声场景识别
这个例子展示了如何创建一个用于声学场景识别的多模型后期融合系统。该示例使用mel谱图训练卷积神经网络(CNN),使用小波散射训练集成分类器。该示例使用TUT数据集进行培训和评估[1]。
介绍
声学场景分类(ASC)是根据环境产生的声音对环境进行分类的任务。ASC是一个通用的分类问题,它是设备、机器人和许多其他应用程序中的上下文感知的基础。ASC的早期尝试使用梅尔频率倒频谱系数(mfcc)和高斯混合模型(GMMs)来描述它们的统计分布。ASC的其他常用特征包括过零率、光谱质心(光谱熵),光谱衰减(光谱衰减点)、谱通量(光谱通量),以及线性预测系数(lpc的) [5]. 训练隐马尔可夫模型(HMM)来描述GMM的时间演化。最近,性能最好的系统使用了深度学习(通常是CNN)和多个模型的融合。DCASE 2017大赛中排名靠前的系统最受欢迎的功能是mel光谱图(光谱图)。挑战中排名靠前的系统使用了后期融合和数据增强技术来帮助其系统实现通用化。
为了说明产生合理结果的简单方法,此示例使用mel频谱图训练CNN,使用小波散射训练集成分类器。CNN和集成分类器产生大致相等的总体精度,但在区分不同的声学场景方面表现更好。要提高总体精度,请合并CNN和集成分类器使用后期融合得到结果。
加载声学场景识别数据集
要运行此示例,必须首先下载数据集[1]。完整的数据集约为15.5 GB。根据您的计算机和internet连接,下载数据可能需要大约4小时。
downloadFolder=tempdir;datasetFolder=fullfile(downloadFolder,“图坦卡蒙-声场景- 2017”);如果~exist(datasetFolder,“dir”)disp(“正在下载TUT-acoustic-scenes-2017(15.5 GB)…”)HelperDownload_TUT_acoustic_scenes_2017(数据集文件夹);终止
以表的形式读入开发集元数据。命名表变量文件名,AcousticScene和SpecificLocation.
metadata\u train=可读取(完整文件(数据集文件夹、,“TUT-acoustic-scenes-2017-development”,“meta.txt”),...“分隔符”,{“\t”},...“ReadVariableNames”、假);metadata_train.Properties。VariableNames = {“文件名”,“AcousticScene”,“特定位置”}; 车长(车长)
8×3)表文件名名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称声学声学声学(声音)音音音(8×3)表文件名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称声学声学声学声学声学声学(词汇词汇名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称名称音频/b020_100_110.wav'}{'beach'}{'b020'}{'audio/b020_40_50.wav'}{'beach'}{'b020'}{'audio/b020_50_60.wav'}{'beach'}{'b020'}{'audio/b020_30_40.wav'}{'beach'}{'b020'}{'audio/b020_160_170.wav'}{'beach'}{'b020'}{'audio/b020_170_180.wav'}{'beach'}{'b020'}
metadata_test = readtable (fullfile (datasetFolder“TUT-声学-场景-2017-评估”,“meta.txt”),...“分隔符”,{“\t”},...“ReadVariableNames”,假);元数据\u test.Properties.VariableNames={“文件名”,“AcousticScene”,“特定位置”};头(metadata_test)
8×3)表文件名:8×3)表文件名:8×3)表文件名文件名:声学声学声学声学词汇词汇词汇表文件名名称名称名称名称名称名称名称名称名称声学声学词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇表文件名声学词汇词汇表文件名声学词汇词汇词汇词汇词汇表文件名声学词汇词汇词汇词汇词汇词汇词汇词汇词汇词汇表表表文件名声学词汇词汇表文件名声学词汇词汇词汇词汇表文件名,词汇表文件名声学词汇词汇表文件名,词汇表词汇表文件名声学词汇词汇词汇词汇词汇表词汇词汇表词汇词汇表词汇表词汇表词汇表词汇词汇词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表文件名声学声学声学声学词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇表词汇7.wav'}{'beach'}{'b174'}{'audio/203.wav'}{'beach'}{'b174'}{'audio/777.wav'}{'beach'}{'b174'}{'audio/231.wav'}{'beach'}{'b174'}{'audio/768.wav'}{'beach'}{'b174'}
请注意,测试集中的特定记录位置与开发集中的特定记录位置不相交。这使得验证经过训练的模型是否可以推广到真实场景变得更加容易。
sharedRecordingLocations=intersect(元数据\u test.SpecificLocation,元数据\u train.SpecificLocation);fprintf('列车和测试集中特定记录位置的数量=%d\n'元素个数(sharedRecordingLocations))
列车和测试集中特定记录位置的数量=0
元数据表的第一个变量包含文件名。将文件名与文件路径连接起来。
列车文件路径=完整文件(数据集文件夹,“TUT-acoustic-scenes-2017-development”,metadata_train.FileName);test_filepath=fullfile(datasetFolder,“TUT-声学-场景-2017-评估”, metadata_test.FileName);
为列车和测试集创建音频数据存储。设置标签财产的音频数据存储去音响现场,打电话计数标签验证列车和试验装置中标签的均匀分布。
adsTrain = audioDatastore (train_filePaths,...“标签”,分类(元数据列车声学场景),...“包含子文件夹”,true);显示(countEachLabel(adsTrain))adsTest=音频数据存储(test\u文件路径,...“标签”分类(metadata_test.AcousticScene),...“包含子文件夹”,true);显示(计数每个标签(adsTest))
15×2餐桌标签计数-海滩312公共汽车312咖啡馆/餐厅312汽车312城市中心312森林路312杂货店312家庭312图书馆312地铁站312办公室312公园312住宅区312火车312有轨电车312 15×2餐桌标签计数-海滩108公共汽车108城市中心8森林路108杂货店108住宅108图书馆108地铁站108办公室108公园108住宅区108火车108有轨电车108
您可以减少本例中使用的数据集,以牺牲性能来加快运行时间。通常,减少数据集对于开发和调试是一种很好的做法。set还原酶到符合事实的减少数据集。
reducedastatset=false;如果简化TASET adsTrain=splitEachLabel(adsTrain,20);adsTest=splitEachLabel(adsTest,10);终止
呼叫阅读从列车组获取文件的数据和采样率。数据库中的音频具有一致的采样率和持续时间。规范化音频并收听。显示相应的标签。
[数据,adsInfo]=读取(adsTrain);数据=数据。/max(数据,[],“全部”);fs = adsInfo.SampleRate;声音(数据、fs)流('声学场景=%s\n',adsTrain.标签(1))
声学场景=海滩
呼叫重置将数据存储返回到其初始状态。
重置(adsTrain)
CNN的特征提取
数据集中的每个音频剪辑由10秒的立体声(左-右)音频组成。本例中的特征提取管道和CNN架构基于[3].特征提取的超参数、CNN体系结构和培训选项均使用系统的超参数优化工作流从原始文件中修改。
首先,将音频转换为中间端编码。[3] 表明中间侧编码数据提供了更好的空间信息,CNN可以使用这些信息来识别移动源(例如火车在声学场景中移动)。
dataMidSide=[和(数据,2),数据(:,1)-数据(:,2)];
将信号分为1秒重叠段。最终系统使用1秒段的概率加权平均值预测测试集中每10秒音频片段的场景。将音频片段分为1秒段使网络更易于训练,并有助于防止网络中的特定声学事件过度拟合训练集。重叠有助于确保训练数据捕获彼此相关的所有特征组合。它还为系统提供额外的数据,这些数据可以在增强过程中唯一地混合。
segmentLength = 1;segmentOverlap = 0.5;[dataBufferedMid, ~] =缓冲区(dataMidSide(: 1),圆(segmentLength * fs),圆(segmentOverlap * fs),“诺德利”);[dataBufferedSide, ~] =缓冲区(dataMidSide(:, 2),圆(segmentLength * fs),圆(segmentOverlap * fs),“诺德利”); 数据缓冲=零(大小(数据缓冲,1),大小(数据缓冲,2)+大小(数据缓冲,2));数据缓冲(:,1:2:end)=数据缓冲;数据缓冲(:,2:2:end)=数据缓冲区;
使用光谱图将数据转换为紧凑的频域表示。按照[3]的建议定义mel谱图的参数。
windowLength=2048;samplesPerHop=1024;samplesOverlap=windowLength-samplesPerHop;fftLength=2*windowLength;Numands=128;
光谱图独立运营渠道。若要优化处理时间,请致电光谱图与整个缓冲信号。
规范= melSpectrogram (dataBuffered fs,...“窗口”,汉明(窗长,“周期性”),...“重叠长度”,样本重叠,...“FFTLength”,fft长度,...“NumBands”,麻木);
将mel光谱图转换为对数刻度。
spec=log10(spec+eps);
将阵列重塑为维度(频带数)-按-(跳数)-按-(通道数)-按-(分段数)。将图像输入神经网络时,前两个维度是图像的高度和宽度,第三维是通道,第四维是分离单个图像的维度。
X=重塑(规格、尺寸(规格1)、尺寸(规格2)、尺寸(数据2),[]);
呼叫光谱图无输出参数,以绘制中间通道的mel频谱图,增量为1秒的前六个增量。
对于通道=1:2:11图4频谱图(数据缓冲(:,通道),fs,...“窗口”,汉明(窗长,“周期性”),...“重叠长度”,样本重叠,...“FFTLength”,fft长度,...“NumBands”,麻木);头衔(斯普林特)('段%d',ceil(频道/2)))终止
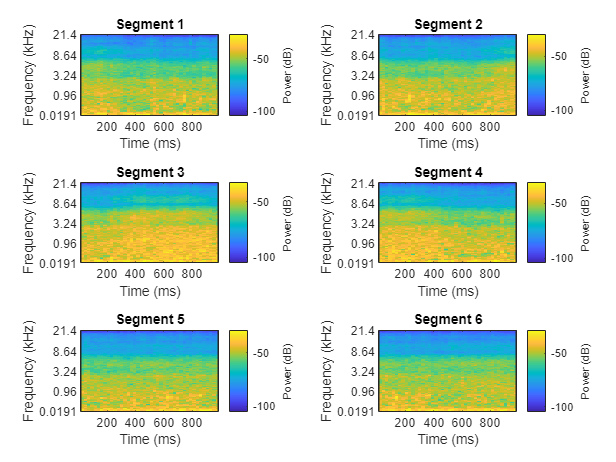




辅助函数HelperSegmentedMelSpectrograms执行上述特征提取步骤。
要加快处理速度,请使用提取数据存储中所有音频文件的mel频谱图高的数组。与内存中的数组不同,在您请求使用聚集此延迟评估使您能够快速处理大型数据集。当您最终使用聚集,MATLAB在可能的情况下结合了排队计算,并采用了通过数据的最少次数™, 您可以在本地MATLAB会话中或在本地并行池中使用高阵列。如果您有MATLAB®并行服务器,还可以在集群上运行高阵列计算™ 安装。
如果没有Parallel Computing Toolbox™,则此示例中的代码仍然可以运行。
pp=parpool(“IdleTimeout”,inf);训练集高=高(adsTrain);xTrain=cellfun(@(x)HelperSegmentedMelSpectrograms(x,fs,...“分段长度”,分段长度,...“分段重叠”segmentOverlap,...“WindowLength”,窗长,...“啤酒花长度”samplesPerHop,...“NumBands”numBands,...“FFTLength”fftLength),...火车站高,...“UniformOutput”,假);xTrain=收集(xTrain);xTrain=cat(4,xTrain{:});测试设置高度=高度(adsTest);xTest=cellfun(@(x)HelperSegmentedMelSpectrograms(x,fs,...“分段长度”,分段长度,...“分段重叠”segmentOverlap,...“WindowLength”,窗长,...“啤酒花长度”samplesPerHop,...“NumBands”numBands,...“FFTLength”fftLength),...测试设置高度,...“UniformOutput”,false);xTest=gather(xTest);xTest=cat(4,xTest{:});
正在使用“本地”配置文件启动并行池(parpool)。。。已连接到并行池(工作线程数:6)。使用并行池“本地”评估tall表达式:-通过1/1:在4分钟48秒内完成评估在4分钟48秒内完成使用并行池“本地”评估tall表达式:-通过1/1:在1分钟40秒内完成评估在1分钟40秒内完成

复制训练集的标签,使其与片段一一对应。
numSegmentsPer10seconds=大小(数据缓冲,2)/2;yTrain=repmat(adsTrain.Labels,1,numsegmentsper10秒);yTrain=yTrain(:);
CNN的数据扩充
DCASE 2017数据集包含了任务中相对较少的声学记录,开发集和评估集记录在不同的特定位置。因此,在训练过程中很容易对数据进行过度拟合。减少过拟合的一个流行方法是混合.在mixup中,您可以通过混合两个不同类的特性来扩充数据集。当你混合功能时,你混合了相同比例的标签。那就是:

混合由[2]重新表述为从概率分布中提取的标签,而不是混合标签。本例中混合的实现是混合的简化版本:每个谱图与不同标签的谱图混合,λ设置为0.5。原始数据集和混合数据集组合用于训练。
xTrainExtra=xTrain;yTrainExtra=yTrain;lambda=0.5;对于i = 1:尺寸(xTrain, 4)找到所有不同标签的光谱图。availableSpectrograms=find(yTrain~=yTrain(i));%随机选择一个具有不同标签的可用光谱图。numAvailableSpectrograms =元素个数(availableSpectrograms);, numAvailableSpectrograms idx =兰迪([1]);%混合。xtrainExtrain(:,:,:,i)=λ*xTrain(:,:,:,i)+(1-lambda)*xTrain(:,:,:,可用特殊程序(idx));%指定由lambda随机设置的标签。如果rand>lambda yTrainExtra(i)=yTrain(可用的谱图(idx));终止终止xTrain =猫(4 xTrain xTrainExtra);yTrain = [yTrain; yTrainExtra];
呼叫总结显示扩充训练集标签的分布。
摘要(yTrain)
海滩11769公共汽车11904咖啡馆/餐厅11873汽车11820城市中心11886森林路11936杂货店11914住宅11923图书馆11817地铁站11804办公室11922公园11871住宅区11704火车11773电车11924
定义和培训CNN
定义CNN体系结构。该体系结构基于[1],并通过反复试验进行修改。请参阅深度学习层列表(深度学习工具箱)了解更多有关MATLAB®中提供的深度学习层的信息。
imgSize = [(xTrain, 1),大小(xTrain, 2),大小(xTrain, 3)];numF = 32;层= [...imageInputLayer (imgSize) batchNormalizationLayer convolution2dLayer (3 numF“填充”,“一样”)batchNormalizationLayer reluLayer卷积2dLayer(3,numF,“填充”,“一样”)batchNormalizationLayer reluLayer MaxPoolig2dLayer(3,“大步走”2,“填充”,“一样”)卷积2层(3,2*numF,“填充”,“一样”)batchNormalizationLayer reluLayer卷积2Dlayer(3,2*numF,“填充”,“一样”)batchNormalizationLayer reluLayer MaxPoolig2dLayer(3,“大步走”2,“填充”,“一样”)卷积2层(3,4*numF,“填充”,“一样”)batchNormalizationLayer reluLayer卷积2Dlayer(3,4*numF,“填充”,“一样”)batchNormalizationLayer reluLayer MaxPoolig2dLayer(3,“大步走”2,“填充”,“一样”)卷积2层(3,8*numF,“填充”,“一样”)batchNormalizationLayer reluLayer卷积2Dlayer(3,8*numF,“填充”,“一样”) batchNormalizationLayer relullayer averagePooling2dLayer(ceil(imgSize(1:2)/8)) dropoutLayer(0.5) fulllyconnectedlayer (15) softmaxLayer classificationLayer];
定义培训选项(深度学习工具箱)这些选项基于[3],并通过系统的超参数优化工作流程进行修改。
miniBatchSize = 128;tuneme = 128;lr = 0.05 * miniBatchSize / tuneme;选择= trainingOptions (“个”,...“初始学习率”、lr、...“MiniBatchSize”miniBatchSize,...“动力”,0.9,...“L2规范化”,0.005,...“MaxEpochs”8....“洗牌”,“每个时代”,...“情节”,“培训进度”,...“详细”错误的...“LearnRateSchedule”,“分段”,...“LearnRateDropPeriod”2,...“LearnRateDropFactor”,0.2);
呼叫列车网络(深度学习工具箱)训练网络。
trainedNet=列车网络(xTrain、yTrain、图层、选项);
评价CNN
呼叫预测(深度学习工具箱)使用保持测试集预测训练网络的响应。
cnnResponsesPerSegment =预测(trainedNet xTest);
平均每个10秒音频剪辑的响应。
classes=trainedNet.Layers(end).classes;numFiles=numel(adsTest.Files);counter=1;cnnResponses=零(numFiles,numel(classes));对于通道=1:numFiles cnnResponses(通道,:)=sum(cnnResponsesPerSegment(计数器:计数器+numSegmentsPer10seconds-1,:),1)/numSegmentsPer10seconds;计数器=计数器+numSegmentsPer10seconds;终止
对于每个10秒的音频剪辑,选择预测的最大值,然后将其映射到相应的预测位置。
[~,classIdx]=max(cnnResponses,[],2);cnnPredictedLabels=classes(classIdx);
呼叫混淆图(深度学习工具箱)使测试集的准确性可视化。返回命令窗口的平均精度。
图cm=混淆图(adsTest.Labels、CNN预定标签、,“头衔”,“测试准确性- CNN”); cm.摘要=“列规格化”; cm.RowSummary=“row-normalized”;fprintf('CNN的平均精度=%0.2f\n',平均值(adsTest.Labels==CNN预定标签)*100)
CNN的平均准确度=75.12

集成分类器的特征提取
[4]中已经展示了小波散射,以提供声学场景的良好表示waveletScattering(小波工具箱)对象。通过反复试验确定了不变性量表和质量因子。
科幻小说= waveletScattering (“信号长度”,大小(数据,1),...“采样频率”,财政司司长,...“不变性刻度”,0.75,...“质量因素”,[4 1]);
将音频信号转换为单声道,然后呼叫特征矩阵(小波工具箱)要返回散射分解框架的散射系数,科幻小说.
数据单=平均值(数据,2);分散系数=特征矩阵(sf,数据单,“转换”,“日志”);
对10秒音频剪辑的散射系数求平均值。
特征向量=平均值(散射系数,2);fprintf('每10秒剪辑的小波特征数=%d\n',numel(特征向量))
每10秒剪辑的小波特征数=290
辅助函数HelperWaveletFeatureVector执行上述步骤。使用高的排列cellfun和HelperWaveletFeatureVector并行特征提取。提取列车和测试集的小波特征向量。
散射训练=cellfun(@(x)HelperWaveletFeatureVector(x,sf),训练设置高度,“UniformOutput”,false);xTrain=gather(scatteringTrain);xTrain=cell2mat(xTrain');scatteringTest=cellfun(@(x)HelperWaveletFeatureVector(x,sf),test_set_-toll,“UniformOutput”,false);xTest=gather(scatteringTest);xTest=cell2mat(xTest');
使用并行池“本地”评估tall表达式:-通过1/1:在30分钟内完成22秒评估在30分钟内完成22秒使用并行池“本地”评估tall表达式:-通过1/1:在10分钟内完成30秒评估在10分钟30秒内完成
定义和训练集成分类器
使用菲特森布尔创建经过训练的分类集成模型(ClassificationEnsemble).
子空间维度= min(150,size(xTrain,2) - 1);numLearningCycles = 30;classificationEnsemble = fitcensemble (xTrain adsTrain。标签,...“方法”,“子”,...“NumLearningCycles”,numLearningCycles,...“学习者”,“判别”,...“NPredToSample”subspaceDimension,...“类名”,removecats(唯一(adsTrain.Labels));
评价集成分类器
对于每个10秒的音频剪辑,打电话预测返回标签和权重,然后将其映射到相应的预测位置。调用混淆图(深度学习工具箱)将测试集上的精度可视化。打印平均值。
[小波预测标签,小波响应]=预测(分类插入,xTest);图cm=混淆图(adsTest.Labels,小波预测标签,“头衔”,“测试精度-小波散射”); cm.摘要=“列规格化”; cm.RowSummary=“row-normalized”;fprintf('分类器的平均精度=%0.2f\n',平均值(adsTest.Labels==小波预测标签)*100)
分类器的平均精度=76.23
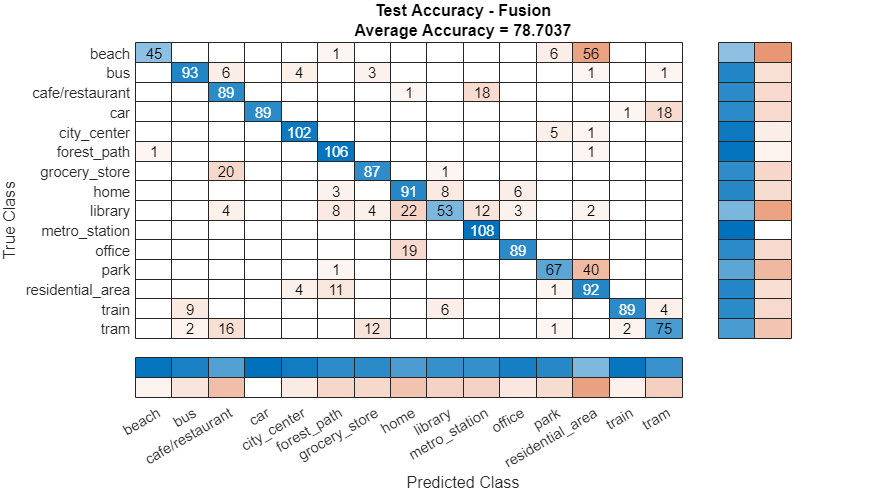
应用后期融合
对于每10秒的剪辑,调用小波分类器上的predict,CNN返回一个向量,表示他们的决策的相对可信度小波响应和CNN回复创建一个后期融合系统。
融合=小波响应。*cnnResponses;[~,classIdx]=max(融合,[],2);预测标签=类(classIdx);
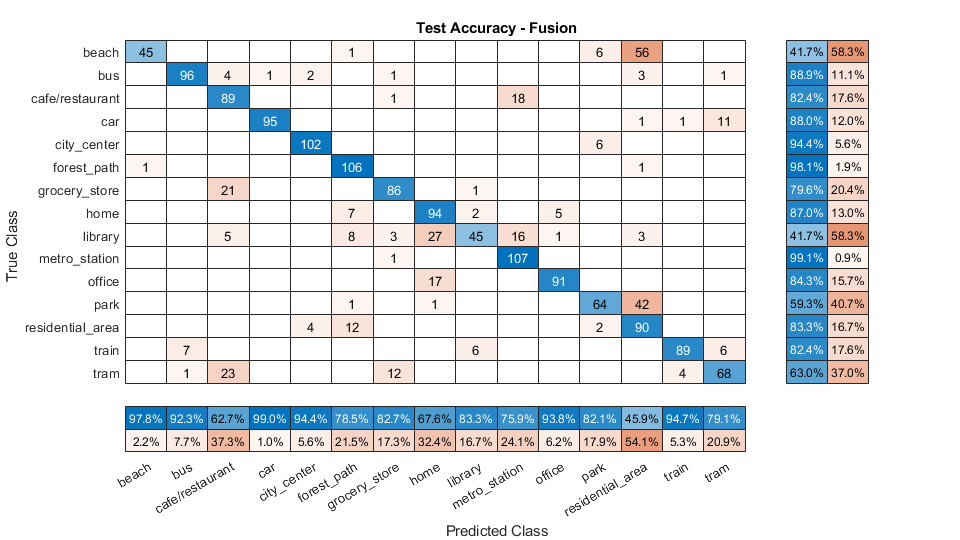
评估晚期融合
呼叫混淆图将融合后的分类精度可视化。打印平均精度到命令窗口。
图cm=混淆图(adsTest.Labels、predictedLabels、,“头衔”,“测试精度-融合”); cm.摘要=“列规格化”; cm.RowSummary=“row-normalized”;fprintf('融合模型的平均精度=%0.2f\n',平均值(adsTest.Labels==predictedLabels)*100)
融合模型的平均精度=79.57

关闭并行池。
删除(pp)
正在关闭使用“本地”配置文件的并行池。
参考文献
[1] A.Mesaros、T.Heittola和T.Virtanen.声学场景分类:DCASE 2017挑战赛参赛作品概述。过程中。声学信号增强国际研讨会,2018年。
[2] 胡萨,费伦茨。“混合:依赖于数据的数据扩充。”推论。2017年11月3日。2019年1月15日访问。https://www.inference.vc/mixup-data-dependent-data-augmentation/.
[3] Han,Yoonchang,Jeongsoo Park和Kyogu Lee.“用于声场景分类的双耳表示和背景减法卷积神经网络”,《声场景和事件的检测和分类》(DCASE)(2017):1-5。
[4] 洛斯坦伦、文森特和若阿金·安登。基于小波散射的双耳场景分类。技术报告,DCASE2016挑战,2016年。
[5] A.J.Eronen,V.T.Peltonen,J.T.Tuomi,A.P.Klapuri,S.Fagerlund,T.Sorsa,G.Lorho和J.Huopaniemi,“基于音频的上下文识别”,IEEE Trans.on Audio,Speech and Language Processing,第14卷,第1期,第321-329页,2006年1月。
附录——支持功能万博1manbetx
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%HelperSegmentedMelSpectrograms作用X = HelperSegmentedMelSpectrograms(X,fs,varargin) p = inputParser;addParameter (p,“WindowLength”,1024); addParameter(p,“啤酒花长度”,512);addParameter(p,“NumBands”,128);addParameter(p,“分段长度”,1); addParameter(p,“分段重叠”,0);addParameter(p,“FFTLength”, 1024);解析(p,varargin{:}) params = p. results;x = [(x, 2)和x (: 1) - x (:, 2)];x = x / max (max (x));[xb_m, ~] =缓冲区(x(: 1),圆(params.SegmentLength * fs),圆(params.SegmentOverlap * fs),“诺德利”); [xb_s,~]=缓冲区(x(:,2),圆形(参数分段长度*fs),圆形(参数分段重叠*fs),“诺德利”); xb=零(大小(xb_m,1),大小(xb_m,2)+大小(xb_s,2));xb(:,1:2:end)=xb_m;xb(:,2:2:end)=xb_s;spec=光谱图(xb,fs,...“窗口”汉明(参数。WindowLength,“周期性”),...“重叠长度”,参数个数。WindowLength——参数。HopLength,...“FFTLength”,参数FFTLENGHT,...“NumBands”,params.NumBands,...“FrequencyRange”[0,地板(fs / 2)));规范= log10(规范+ eps);X =重塑(规格、尺寸(规范,1),大小(规范,2),大小(X, 2), []);终止%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%HelperWaveletFeatureVector作用特征=辅助波特征向量(x,sf)x=平均值(x,2);特征=特征矩阵(sf,x,“转换”,“日志”);特征=平均值(特征,2);终止%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
您还可以从以下列表中选择网站: