定制培训与实验中的多个gpu经理
这个例子展示了如何配置多个平行工人合作在每个试验的自定义训练实验。在这个例子中,平行的工人训练部分整体mini-batch在每个试验图像的分类实验。在培训期间,DataQueue对象将培训进展信息发送回实验管理器。如果你有一个支持GPU,然后万博1manbetx训练在GPU上没有发生。有关更多信息,请参见GPU计算的需求(并行计算工具箱)。
作为一种替代方法,您可以设置一个平行的定制培训循环运行单个试验的实验以编程方式。有关更多信息,请参见列车网络与自定义训练循环。
开放实验
首先,打开示例。实验管理器加载一个预配置实验的项目,你可以检查和运行。开放实验,实验的浏览器面板,双击ParallelCustomLoopExperiment。

定制培训实验由一个描述,hyperparameters表和培训功能。有关更多信息,请参见配置自定义训练实验。
的描述字段包含的文本描述的实验。对于这个例子,描述是:
使用多个平行工人培训一个图像分类网络。每个试验使用不同的初始学习速率和动量。
的Hyperparameters节指定策略和hyperparameter值用于实验。当您运行实验,实验管理器使用每一列车网络的组合hyperparameter hyperparameter表中指定的值。这个示例使用两个hyperparameters:
InitialLearnRate用于训练集最初的学习速率。如果学习速率太低,那么培训需要很长时间。如果学习速率过高,那么训练可以达到一个理想的结果或发散的。最好的学习速率取决于你数据以及网络培训。动力指定的贡献梯度从上一次迭代到当前迭代步随机梯度下降的势头。
的培训功能部分指定一个函数,定义了训练数据,网络体系结构,培训方案和培训过程所使用的实验。在MATLAB®编辑器打开这个功能,点击编辑。函数的代码也出现在培训功能。训练的输入函数是一个结构从hyperparameter表和字段experiments.Monitor对象,您可以使用它来跟踪培训的进度,记录值的指标使用的培训,和生产培训的阴谋。函数返回一个结构,包含训练网络,训练,和验证精度。实验管理器保存此输出可以出口到MATLAB工作区当培训完成。这些部分:训练函数
初始化输出设置网络的初始值,训练,和验证准确性空数组,表明训练还没有开始。
output.network = [];输出。损失= [];输出。精度= [];
负荷训练和测试数据定义了实验的训练和测试数据
imageDatastore对象。实验使用数字数据集合,它由5000 28-by-28像素灰度图像的数字从0到9,由它们所代表的数字分类。这个数据集的更多信息,请参阅图像数据集。
班长。状态=“加载数据”;dataFolder = fullfile (toolboxdir (“nnet”),…“nndemos”,“nndatasets”,“DigitDataset”);imd = imageDatastore (dataFolder,…IncludeSubfolders = true,…LabelSource =“foldernames”);[imdsTrain, imdsTest] = splitEachLabel (imd, 0.9,“随机”);类=类别(imdsTrain.Labels);numClasses =元素个数(类);XTest = readall (imdsTest);XTest =猫(4 XTest {:});XTest =单(XTest)。/ 255;trueLabels = imdsTest.Labels;
定义网络体系结构定义了图像分类网络的体系结构。这个网络体系结构包括一批标准化层轨道的均值和方差统计数据集。当并行训练,确保网络状态反映了整个mini-batch,结合统计数据从所有的工人在每个迭代步骤。否则,网络状态可以发散在工人。如果你是递归神经网络训练状态(RNNs),例如,使用序列数据分割成更小的序列来训练网络包含LSTM或格勒乌层,你还必须管理的工人之间的状态。训练网络使用一个自定义训练循环和启用自动分化,训练函数转换层图
dlnetwork对象。
班长。状态=“创建网络”;层= [imageInputLayer([28 28 1],正常化=“没有”20)convolution2dLayer (5) batchNormalizationLayer reluLayer convolution2dLayer(3、20、填充= 1)batchNormalizationLayer reluLayer convolution2dLayer(3、20、填充= 1)batchNormalizationLayer reluLayer fullyConnectedLayer (numClasses)];lgraph = layerGraph(层);
设置并行环境确定如果gpu可用于MATLAB使用。如果有可用的gpu,然后火车在gpu上。如果平行池不存在,创建一个与gpu的许多工人。如果没有可用的gpu,然后火车cpu。如果平行池不存在,创建一个默认的工人数量。
班长。状态=“开始平行池”;池= gcp (“nocreate”);如果canUseGPU executionEnvironment =“图形”;如果isempty(池)numberOfGPUs = gpuDeviceCount (“可用”);池= parpool (numberOfGPUs);结束其他的executionEnvironment =“cpu”;如果isempty(池)池= parpool;结束结束N = pool.NumWorkers;
指定培训选项定义使用的培训选择实验。在这个例子中,实验经理mini-batch大小的列车网络
128年为20.时代使用最初的学习速率和动量hyperparameter表中定义。如果你训练GPU, mini-batch与GPU的数量规模的增加线性保持每个GPU的工作负载恒定。有关更多信息,请参见深度学习与MATLAB在多个gpu。
numEpochs = 20;miniBatchSize = 128;速度= [];initialLearnRate = params.InitialLearnRate;动量= params.Momentum;衰变= 0.01;如果executionEnvironment = =“图形”miniBatchSize = miniBatchSize。* N;结束workerMiniBatchSize =地板(miniBatchSize。/ repmat (1, N));剩余= miniBatchSize - sum (workerMiniBatchSize);workerMiniBatchSize = workerMiniBatchSize +[1(剩余)0 (N-remainder)];
火车模型定义了平行定制培训循环使用的实验。同时执行代码在所有的工人,培训使用一个函数
spmd块,不能包含打破,继续,或返回语句。结果,你不能中断试验实验的训练是在进步。如果您按停止、实验管理器运行当前试验完成之前停止实验。并行自定义训练循环的更多信息,见附录1最后这个例子。
班长。指标= [“TrainingLoss”“ValidationAccuracy”];班长。包含=“迭代”;班长。状态=“培训”;Q = parallel.pool.DataQueue;updateFcn = @ (x) updateTrainingProgress (x,监控);afterEach (Q, updateFcn);spmdworkerImds =分区(imdsTrain N spmdIndex);workerImds。ReadSize= workerMiniBatchSize(spmdIndex); workerVelocity = velocity; iteration = 0; lossArray = []; accuracyArray = [];为时代= 1:numEpochs重置(workerImds);workerImds = shuffle (workerImds);如果~ monitor.Stop而spmdReduce (@and hasdata (workerImds))迭代=迭代+ 1;[workerXBatch, workerTBatch] =阅读(workerImds);workerXBatch =猫(4,workerXBatch {:});workerNumObservations =元素个数(workerTBatch.Label);workerXBatch =单(workerXBatch)。/ 255;workerY = 0 (numClasses workerNumObservations,“单身”);为c = 1: numClasses workerY (c, workerTBatch.Label = =类(c)) = 1;结束workerX = dlarray (workerXBatch,“SSCB”);如果executionEnvironment = =“图形”workerX = gpuArray (workerX);结束[workerLoss, workerGradients workerState] = dlfeval (@modelLoss,净,workerX workerY);workerNormalizationFactor = workerMiniBatchSize (spmdIndex)。/ miniBatchSize;损失= spmdPlus (workerNormalizationFactor * extractdata (workerLoss));网。状态= aggregateState (workerState workerNormalizationFactor);workerGradients。值= dlupdate (@aggregateGradients workerGradients.Value, {workerNormalizationFactor});learnRate = initialLearnRate /(1 +衰变*迭代);【净。可学的,workerVelocity] = sgdmupdate (net.Learnables、workerGradients workerVelocity, learnRate,动量);结束如果spmdIndex = = 1 YPredScores =预测(净dlarray (XTest,“SSCB”));[~,idx] = max (YPredScores [], 1);Ypred =类(idx);精度=意味着(Ypred = = trueLabels);lossArray = [lossArray;迭代,损失);accuracyArray = [accuracyArray;迭代精度);数据= (numEpochs时代迭代精度损失);发送(Q,收集(数据));结束结束结束结束output.network =净{1};输出。损失= lossArray {1};输出。精度= accuracyArray {1};predictedLabels =分类(Ypred {1});删除(gcp (“nocreate”));
情节混淆矩阵调用
confusionchart函数创建验证数据的混淆矩阵。培训完成后,审查结果画廊在将来发布混淆矩阵显示一个按钮。的的名字图的属性指定按钮的名称。您可以点击按钮来显示的混淆矩阵可视化窗格。
图(Name =“混淆矩阵”)confusionchart (trueLabels predictedLabels,…ColumnSummary =“column-normalized”,…RowSummary =“row-normalized”,…Title =“验证数据的混淆矩阵”);
运行实验
当您运行实验,实验管理列车网络多次训练函数定义的。每个试验使用不同的组合hyperparameter值。
因为这个实验使用MATLAB的平行池会话,你不能训练多个试验在同一时间。在实验管理器将来发布,在模式中,选择顺序并点击运行。另外,将实验作为批处理作业,集模式来批处理顺序,指定你集群和池大小,然后单击运行。有关更多信息,请参见卸载实验作为集群的批处理作业。
一个表显示的结果为每个审判训练和验证精度损失。

显示培训策划和跟踪每个试验的进展在实验时,审查结果,点击培训策划。

请注意,这个实验的训练函数使用一个spmd不能包含的语句打破,继续,或返回语句。结果,你不能中断试验实验的训练是在进步。如果您点击停止、实验管理器运行当前试验完成之前停止实验。
评估结果
找到最佳的实验结果,验证结果的准确性对表进行排序。
指出ValidationAccuracy列。
点击三角形图标。
选择按照降序排列。
最高的试验验证准确性出现在顶部的结果表。

显示这个审判的混淆矩阵,选择结果表中的第一行,审查结果,点击混淆矩阵。

执行额外的计算,导出培训输出工作空间的结构。的trainedNet这个结构包含了训练网络。
在实验管理器将来发布,点击出口>训练输出。
在对话框窗口中,输入导出的培训工作空间变量的名称输出。默认的名称是
trainingOutput。
记录对你的实验的结果,添加一个注释。
在结果表中,右键单击ValidationAccuracy细胞最好的审判。
选择添加注释。
在注释窗格中,在文本框中输入你的观察。
有关更多信息,请参见排序、过滤和注释的实验结果。
关闭实验
在实验的浏览器窗格中,右键单击项目并选择的名称关闭项目。实验管理器关闭所有的实验和结果包含在项目中。
培训功能
这个函数配置培训数据、网络体系结构和培训选择实验。同时执行代码在所有的工人,函数使用一个spmd块。在spmd块,spmdIndex给出了指数的工人正在执行的代码。在培训之前,功能分区数据存储为每个工人使用分区功能,集ReadSizemini-batch大小的工人。对于每个时代,重置并打乱数据存储功能。每一次迭代的时代,功能:
读取mini-batch从数据存储和处理数据进行训练。
计算损失和网络的梯度在每个工人通过调用
dlfeval在modelLoss函数。获得整体使用叉和损失总量损失所有工人使用损失的总和。
骨料和更新所有员工使用的梯度
dlupdate函数与aggregateGradients函数。聚合网络状态的所有工人使用
aggregateState函数。更新的网络可学的参数
sgdmupdate函数。
在每个时代,函数只使用职工培训进展信息发送回客户端。
函数输出= ParallelCustomLoopExperiment_training(参数、监控)
初始化输出
output.network = [];输出。损失= [];输出。精度= [];
负荷训练和测试数据
班长。状态=“加载数据”;dataFolder = fullfile (toolboxdir (“nnet”),…“nndemos”,“nndatasets”,“DigitDataset”);imd = imageDatastore (dataFolder,…IncludeSubfolders = true,…LabelSource =“foldernames”);[imdsTrain, imdsTest] = splitEachLabel (imd, 0.9,“随机”);类=类别(imdsTrain.Labels);numClasses =元素个数(类);XTest = readall (imdsTest);XTest =猫(4 XTest {:});XTest =单(XTest)。/ 255;trueLabels = imdsTest.Labels;
定义网络体系结构
班长。状态=“创建网络”;层= [imageInputLayer([28 28 1],正常化=“没有”20)convolution2dLayer (5) batchNormalizationLayer reluLayer convolution2dLayer(3、20、填充= 1)batchNormalizationLayer reluLayer convolution2dLayer(3、20、填充= 1)batchNormalizationLayer reluLayer fullyConnectedLayer (numClasses)];lgraph = layerGraph(层);
设置并行环境
班长。状态=“开始平行池”;池= gcp (“nocreate”);如果canUseGPU executionEnvironment =“图形”;如果isempty(池)numberOfGPUs = gpuDeviceCount (“可用”);池= parpool (numberOfGPUs);结束其他的executionEnvironment =“cpu”;如果isempty(池)池= parpool;结束结束N = pool.NumWorkers;
指定培训选项
numEpochs = 20;miniBatchSize = 128;速度= [];initialLearnRate = params.InitialLearnRate;动量= params.Momentum;衰变= 0.01;如果executionEnvironment = =“图形”miniBatchSize = miniBatchSize。* N;结束workerMiniBatchSize =地板(miniBatchSize。/ repmat (1, N));剩余= miniBatchSize - sum (workerMiniBatchSize);workerMiniBatchSize = workerMiniBatchSize +[1(剩余)0 (N-remainder)];
火车模型
班长。指标= [“TrainingLoss”“ValidationAccuracy”];班长。包含=“迭代”;班长。状态=“培训”;Q = parallel.pool.DataQueue;updateFcn = @ (x) updateTrainingProgress (x,监控);afterEach (Q, updateFcn);spmdworkerImds =分区(imdsTrain N spmdIndex);workerImds。ReadSize= workerMiniBatchSize(spmdIndex); workerVelocity = velocity; iteration = 0; lossArray = []; accuracyArray = [];为时代= 1:numEpochs重置(workerImds);workerImds = shuffle (workerImds);如果~ monitor.Stop而spmdReduce (@and hasdata (workerImds))迭代=迭代+ 1;[workerXBatch, workerTBatch] =阅读(workerImds);workerXBatch =猫(4,workerXBatch {:});workerNumObservations =元素个数(workerTBatch.Label);workerXBatch =单(workerXBatch)。/ 255;workerY = 0 (numClasses workerNumObservations,“单身”);为c = 1: numClasses workerY (c, workerTBatch.Label = =类(c)) = 1;结束workerX = dlarray (workerXBatch,“SSCB”);如果executionEnvironment = =“图形”workerX = gpuArray (workerX);结束[workerLoss, workerGradients workerState] = dlfeval (@modelLoss,净,workerX workerY);workerNormalizationFactor = workerMiniBatchSize (spmdIndex)。/ miniBatchSize;损失= spmdPlus (workerNormalizationFactor * extractdata (workerLoss));网。状态= aggregateState (workerState workerNormalizationFactor);workerGradients。值= dlupdate (@aggregateGradients workerGradients.Value, {workerNormalizationFactor});learnRate = initialLearnRate /(1 +衰变*迭代);【净。可学的,workerVelocity] = sgdmupdate (net.Learnables、workerGradients workerVelocity, learnRate,动量);结束如果spmdIndex = = 1 YPredScores =预测(净dlarray (XTest,“SSCB”));[~,idx] = max (YPredScores [], 1);Ypred =类(idx);精度=意味着(Ypred = = trueLabels);lossArray = [lossArray;迭代,损失);accuracyArray = [accuracyArray;迭代精度);数据= (numEpochs时代迭代精度损失);发送(Q,收集(数据));结束结束结束结束output.network =净{1};输出。损失= lossArray {1};输出。精度= accuracyArray {1};predictedLabels =分类(Ypred {1});删除(gcp (“nocreate”));
情节混淆矩阵
图(Name =“混淆矩阵”)confusionchart (trueLabels predictedLabels,…ColumnSummary =“column-normalized”,…RowSummary =“row-normalized”,…Title =“验证数据的混淆矩阵”);
结束
辅助函数
的modelLoss函数接受一个dlnetwork对象净和mini-batch输入数据X与相应的标签Y。函数返回的梯度对可学的参数净、网络状态和损失。自动计算梯度,函数调用dlgradient函数。
函数(损失、渐变、状态)= modelLoss(净,X, Y) [YPred、州]=前进(净,X);YPred = softmax (YPred);损失= crossentropy (YPred Y);梯度= dlgradient(损失、net.Learnables);结束
的updateTrainingProgress功能更新来自于工人的培训进展信息。在这个例子中,DataQueue对象调用这个函数每次工人发送数据。
函数updateTrainingProgress(数据、监控)监控。进步=((2)数据/数据(1))* 100;recordMetrics(监视、数据(4)…TrainingLoss =数据(3));结束
的aggregateGradients功能聚合物梯度对所有工人通过添加在一起。spmdplus加在一起,复制上的所有渐变的工人。添加渐变之前,该函数可实现通过乘以一个系数代表的比例总体mini-batch工人工作。
函数梯度= aggregateGradients(渐变因子)梯度= spmdPlus(因子*渐变);结束
的aggregateState功能聚合物网络状态对所有工人。网络状态包含训练一批标准化数据的数据集。因为每个工人只看到一部分mini-batch,这个函数聚合网络状态,以便统计是统计所有数据的代表。对于每个mini-batch,这个函数计算结合均值的加权平均在每个迭代的工人。该函数根据公式计算方差相结合
![$ $ s_c ^ 2 = \压裂{1}{M} \ sum_ {j = 1} ^ {N} m_j [s_j ^ 2 +(\酒吧{x_j} & # xA; \酒吧{x_c}) ^ 2],美元美元](http://www.tianjin-qmedu.com/help/examples/experiments/win64/MultiGPUExample_eq06906594659706812441.png)
在哪里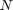 工人总数,
工人总数,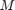 是在mini-batch观测的总数,
是在mini-batch观测的总数,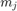 观察上处理的数量吗
观察上处理的数量吗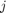 th工人,
th工人,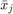 和
和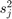 均值和方差的统计计算,工人,然后呢
均值和方差的统计计算,工人,然后呢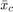 合并意味着所有工人。
合并意味着所有工人。
函数国家= aggregateState(状态、因素)numrows =大小(状态,1);为j = 1: numrows isBatchNormalizationState = state.Parameter (j) = =“TrainedMean”…& & state.Parameter (j + 1) = =“TrainedVariance”…& & state.Layer (j) = = state.Layer (j + 1);如果isBatchNormalizationState meanVal = state.Value {};varVal = state.Value {j + 1};* meanVal combinedMean = spmdPlus(因素);combinedVarTerm =因素。* (varVal + (meanVal combinedMean) ^ 2);state.Value (j) = {combinedMean};state.Value (j + 1) = {spmdPlus (combinedVarTerm)};结束结束结束