深度学习的数据集
使用这些数据集开始深度学习应用程序。
图像数据集
| 数据集 | 描述 | 任务 |
|---|---|---|
数字
|
数字数据集由10,000张合成的手写数字灰度图像组成。每个图像是28 × 28像素,并有一个相关的标签表示图像所代表的数字(0-9)。每个图像都被旋转了一定的角度。当以数组形式加载图像时,还可以加载图像的旋转角度。 将数字数据作为内存中的数字阵列加载 [XTrain, YTrain anglesTrain] = digitTrain4DArrayData;[XTest,欧美,anglesTest] = digitTest4DArrayData; 关于如何处理这些数据进行深度学习的例子,请参见监测深度学习培训进度和训练卷积神经网络用于回归. |
图像分类和图像回归 |
使用使用的图像数据存储将数字数据加载 datafolder = fullfile(toolboxdir(“nnet”),“nndemos”那“nndatasets”那“DigitDataset”);imds=图像数据存储(数据文件夹,...'insertumbfolders',真的,....“LabelSource”那“foldernames”); 有关如何处理这些数据进行深度学习的示例,请参见为分类创建简单的深度学习网络. |
图像分类 | |
MNIST
(代表) |
MNIST数据集由70,000个手写数字组成,分别分为60,000张和10,000张图像的训练和测试分区。每个图像是28 × 28像素,并有一个相关的标签表示图像所代表的数字(0-9)。 从中下载mnist文件http://yann.lecun.com/exdb/mnist/并将数据集加载到工作区中。要将文件中的数据加载为MATLAB数组,请将文件放置在工作目录中,然后使用辅助函数 oldpath = addpath(fullfile(matlabroot,'例子'那“nnet”那“主要”));filenameimagestrain =“train-images-idx3-ubyte.gz”;filenamelabelstrain =“train-labels-idx1-ubyte.gz”;filenameimagestest ='t10k-images-idx3-ubyte.gz';filenameLabelsTest ='t10k-labels-idx1-ubyte.gz';XTrain = processImagesMNIST (filenameImagesTrain);YTrain = processLabelsMNIST (filenameLabelsTrain);XTest = processImagesMNIST (filenameImagesTest);欧美= processLabelsMNIST (filenameLabelsTest); 有关如何处理这些数据进行深度学习的示例,请参见火车变形AutoEncoder(VAE)生成图像. 要恢复路径,请使用 路径(旧路径); |
图像分类 |
万能语
|
Omniglot数据集包含50个字母的字符集,分为30个字符集用于训练,20个字符集用于测试。每个字母表都包含一些字符,从14个代表Ojibwe(加拿大土著音节)到55个代表Tifinagh。最后,每个字符有20个手写的观察结果。 下载并提取Omniglot数据集[1]从…起https://github.com/brendenlake/omniglot.放 downloadFolder = tempdir;url =“https://github.com/brendenlake/omniglot/raw/master/python”;URLTRAIN = URL +“/ images_background.zip”;URLTEST = URL +“/images_evaluation.zip”;filenameTrain=fullfile(下载文件夹,“images_background.zip”);filenametest = fullfile(downloadFolder,“images_evaluation.zip”);dataFolderTrain = fullfile (downloadFolder,“images_background”);dataFolderTest = fullfile (downloadFolder,“images_evaluation”);如果~exist(dataFolderTrain,“dir”)fprintf(“下载omniglot培训数据集(4.5 MB)......”)websave(filenameTrain,urlTrain);解压缩(filenameTrain,downloadFolder);fprintf(“完成。\ n”)结尾如果〜存在(DataFoldert,“dir”)fprintf(“下载Omniglot测试数据(3.2 MB)…”)Websave(FilenameTest,URLTest);解压缩(FilenameTest,DownloadFolder);fprintf(“完成。\ n”)结尾 要将训练和测试数据加载为图像数据存储,请使用 imdsTrain = imageDatastore (dataFolderTrain,...'insertumbfolders',真的,...“LabelSource”那'没有任何');文件= imdsTrain.Files;部分=分裂(文件、filesep);标签=加入(部分(:,(end-2): (end-1)),'_');imdstrain.labels =分类(标签);imdstest = imageageataStore(DataFoldertest,...'insertumbfolders',真的,...“LabelSource”那'没有任何');files = imdstest.files;部分=分裂(文件、filesep);标签=加入(部分(:,(end-2): (end-1)),'_');imdsTest。标签= categorical(labels); 有关如何处理这些数据进行深度学习的示例,请参见训练暹罗网络来比较图像. |
图像相似性 |
花
|
花卉数据集包含3670幅花卉图像,它们属于五个类(黛西那蒲公英那玫瑰那向日葵, 和郁金香)。 下载并提取Flowers数据集[2]从…起http://download.tensorflow.org/example_images/flower_photos.tgz.数据集约为218 MB。根据你的网络连接,下载过程可能需要一些时间。放 url =“http://download.tensorflow.org/example_images/flower_photos.tgz”;downloadFolder = tempdir;filename = fullfile(downloadFolder,'flower_dataset.tgz');dataFolder = fullfile (downloadFolder,'flower_photos');如果~exist(数据文件夹,'dir')fprintf(“下载鲜花数据集(218 MB)......”) websave(文件名,url);Untar(Filename,DownloadFolder)FPRINTF(“完成。\ n”)结尾 使用使用的图像数据存储将数据加载 imd = imageDatastore (dataFolder,...'insertumbfolders',真的,...“LabelSource”那“foldernames”); 有关如何处理这些数据进行深度学习的示例,请参见火车生成对抗网络(GaN). |
图像分类 |
示例食物图像
|
该示例食物图像数据集包含978张食物的九级课程(caeser_salad那caprese_salad那french_fries那greek_salad那汉堡包那热狗那披萨那生鱼片, 和寿司)。 属性下载Example Food Images数据集 fprintf("下载食物图片样本数据集(77mb)…")filename = matlab.internal.examples.downloads万博1manbetxupportfile(“nnet”那...'data / exampleFoodImageGageTaset.zip');fprintf(“完成。\ n”) filepath = fileparts(文件名);dataFolder = fullfile (filepath,'exampleFoodImageTataSet');解压缩(文件名、数据文件夹); 有关如何处理这些数据进行深度学习的示例,请参见使用TSNE查看网络行为. |
图像分类 |
CiFar-10.
(代表) |
CIFAR-10数据集包含60,000个彩色图像的大小32×32像素,属于10类(飞机那汽车那鸟那猫那鹿那狗那青蛙那马那船, 和卡车)。 每个类有6000张图像,数据集被分割为包含50,000张图像的训练集和包含10,000张图像的测试集。该数据集是测试新的图像分类模型最广泛使用的数据集之一。 下载并提取CIFAR-10数据集[7]从…起https://www.cs.toronto.edu/%7ekriz/cifar-10-matlab.tar.gz..数据集大约是175mb。根据你的互联网连接,下载过程可能需要一些时间。放 url =“https://www.cs.toronto.edu/ ~ kriz / cifar-10-matlab.tar.gz”;downloadFolder = tempdir;filename = fullfile(downloadFolder,“cifar-10-matlab.tar.gz”);dataFolder = fullfile (downloadFolder,'CiFar-10-Batches-Mat');如果~exist(数据文件夹,'dir')fprintf(“下载CIFAR-10数据集(175mb)…”);WebSave(Filename,URL);Untar(文件名,DownloadFolder);fprintf(“完成。\ n”)结尾 loadCIFARData,在该示例中使用图像分类的训练残差网络.oldpath = addpath(fullfile(matlabroot,'例子'那“nnet”那“主要”));[XTrain, YTrain XValidation YValidation] = loadCIFARData (downloadFolder); 有关如何处理这些数据进行深度学习的示例,请参见图像分类的训练残差网络. 要恢复路径,请使用 路径(旧路径); |
图像分类 |
MathWorks®货物
|
这是一个小型数据集,其中包含75个MathWorks商品图像,属于五种不同的类(帽子那立方体那打牌那螺丝刀, 和火炬)。您可以使用此数据集尝试快速传输学习和图像分类。 这些图像的尺寸是227 × 227 × 3。 提取Mathworks Merch数据集。 filename =.“MerchData.zip”;dataFolder = fullfile (tempdir,'merchdata');如果~exist(数据文件夹,'dir'解压缩(文件名,tempdir);结尾 使用使用的图像数据存储将数据加载 imd = imageDatastore (dataFolder,...'insertumbfolders',真的,....“LabelSource”那“foldernames”); 关于如何处理这些数据进行深度学习的例子,请参见开始迁移学习和训练深度学习网络对新图像进行分类. |
图像分类 |
CamVid
|
CamVid数据集是一组图像,其中包含从行驶中的汽车获取的街道级别视图。该数据集对于执行图像语义分割的培训网络非常有用,并为32个语义类提供像素级别的标签,包括汽车那行人, 和路. 图像的大小为720×960-3。 下载并提取Camvid数据集[8]从…起http://web4.cs.ucl.ac.uk/staff/g.brostow/MotionSegRecData.数据集大约是573 MB。根据你的互联网连接,下载过程可能需要一些时间。放 downloadFolder = tempdir;url =“http://web4.cs.ucl.ac.uk/staff/g.brostow/motionsegrecdata”urlImages = url +“/files/701_stillsraw_full.zip”;urlLabels = url +“/data/labeledapu full.zip”;dataFolder = fullfile (downloadFolder,“CamVid”);dataFolderImages = fullfile (dataFolder,“图像”);datafolderlabels = fullfile(datafolder,“标签”);filenameLabels = fullfile (dataFolder,'labels.zip');filenameimages = fullfile(datafolder,'图像.zip');如果~存在(filenameLabels“文件”)||〜存在(Imagezip,“文件”mkdir (dataFolder)流(“下载Camvid数据集图像(557 MB)......”);websave (filenameImages urlImages);解压缩(filenameImages dataFolderImages);fprintf(“完成。\ n”)fprintf("下载CamVid数据集标签(16mb)…");websave (filenameLabels urlLabels);解压缩(filenameLabels dataFolderLabels);fprintf(“完成。\ n”)结尾 使用使用的像素标签数据存储作为像素标签数据存储 oldpath = addpath(fullfile(matlabroot,'例子'那'deeplearning_shared'那“主要”));imd = imageDatastore (dataFolderImages,'insertumbfolders',真的);类= [“天空”“建筑”“极”“路”“路面”“树”...“SignSymbol”“篱笆”“汽车”“行人”“骑自行车的人”];labelids = camvidpixellabelids;pxds = pixellabeldataStore(datafolderlabels,classes,labelids); 有关如何处理这些数据进行深度学习的示例,请参见利用深度学习的语义分割. 要恢复路径,请使用 路径(旧路径); |
语义分割 |
车辆
|
车辆数据集由295个图像组成,其中包含一个或两个已标记的车辆实例。这个小数据集对于探索YOLO-v2训练过程很有用,但在实践中,需要更多标记的图像来训练一个健壮的检测器。 图像的大小为720×960-3。 提取车辆数据集。设置 filename =.“vehicleDatasetImages.zip”;dataFolder = fullfile (tempdir,'车辆仿真');如果~exist(数据文件夹,'dir'解压缩(文件名,tempdir);结尾 将作为文件名表的数据集从提取的MAT文件中加载为文件名表和边界框,并将文件名转换为绝对文件路径。 data =负载('车辆有绳索地面纠址.MAT');vevicledataset = data.vehicledataset;vevicledataset.imagefilename = fullfile(tempdir,车辆levicallaset.imagefilename);
创建包含图像的图像数据存储和包含包含边界框的框标签数据存储 filenamesImages = vehicleDataset.imageFilename;tblBoxes = vehicleDataset (:,“汽车”);IMDS = ImageageAtastore(FilenamesImages);BLDS = BoxLabeldAtastore(Tblboxes);CDS =组合(IMDS,BLD);
有关如何处理这些数据进行深度学习的示例,请参见使用YOLO V2深度学习的对象检测. |
目标检测 |
RIT-18
|
RIT-18数据集包含在纽约州的哈林海滩州立公园的无人机捕获的图像数据。数据包含标记的培训,验证和测试集,其中18个对象类标签,包括道路标记那树, 和建筑. 下载rit18数据集[9]从…起https://www.cis.rit.edu/%7Ermk6217/rit18_data.mat.数据集是约3 GB。根据你的网络连接,下载过程可能需要一些时间。放 downloadFolder = tempdir;url =“http://www.cis.rit.edu/ ~ rmk6217 / rit18_data.mat”;filename = fullfile(downloadFolder,“rit18_data.mat”);如果〜存在(文件名,“文件”)fprintf(“下载Hamlin Beach数据集(3 GB)......”); websave(文件名、url);fprintf(“完成。\ n”)结尾 有关如何处理这些数据进行深度学习的示例,请参见深度学习的多光谱图像的语义分割. |
语义分割 |
br
|
Brats数据集包含脑肿瘤的MRI扫描,即胶质瘤,这是最常见的主要脑恶性肿瘤。 该数据集包含750个4-D卷,每个卷表示一组3-D图像。每个4-D体积的大小为240×240×155×4,其中前三个尺寸对应于3-D体积图像的高度、宽度和深度。第四维对应不同的扫描模式。数据集分为484个带有体素标签的训练卷和266个测试卷。 创建一个目录来存储BraTS数据集[10]. dataFolder = fullfile (tempdir,“小鬼”);如果~exist(数据文件夹,'dir'mkdir (dataFolder);结尾 下载BraTS数据医学分割十项全能点击“下载数据”链接。下载“task01_braintumor .tar”文件。数据集约为7gb。根据你的网络连接,下载过程可能需要一些时间。 将TAR文件解压到指定的目录中 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的三维脑肿瘤分割. |
语义分割 |
Camelyon16
|
来自Camelyon16攻击的数据含有来自两个独立源的总共400 WSIS的淋巴结,分为270次训练图像和130个测试图像。WSIS以带有11级金字塔结构的剥离格式存储为TIF文件。 训练数据集由159 WSIS的正常淋巴结和111个全幻灯片(WSIS)的淋巴结与肿瘤和健康组织组成。通常,肿瘤组织是健康组织的一小部分。肿瘤图像伴随病变界限的地面真理坐标。 创建用于存储Camelyon16数据集的目录[11]. dataFolderTrain=fullfile(tempdir,“Camelyon16”那“培训”);datafoldernormaltrain = fullfile(datafoldertrain,'普通的'); dataFolderTumorTrain=完整文件(dataFolderTrain,'瘤');datafolderannotationstrain = fullfile(datafoldertrain,“病变注释”);如果~exist(dataFolderTrain,'dir')mkdir(datafoldertrain);mkdir(datafoldernormaltrain);mkdir(datafoldertumortrain);mkdir(datafolderannotationstrain);结尾 下载来自的Camelyon16数据Camelyon17单击第一个“Camelyon16数据集”链接。打开“培训”目录,然后按照下列步骤操作:
数据集约为2gb。根据您的Internet连接,下载过程可能需要一些时间。 有关如何处理这些数据进行深度学习的示例,请参见利用分块图像和深度学习对大的多分辨率图像进行分类. |
图像分类(大图像) |
上下文中的常见对象(Coco)
(代表) |
Coco 2014列车图像数据集由82,783个图像组成。注释数据包含至少五个对应于每个图像的标题。 创建目录以存储COCO数据集。 dataFolder = fullfile (tempdir,“Coco”);如果~exist(数据文件夹,'dir'mkdir (dataFolder);结尾 从以下站点下载并提取COCO 2014列车图像和标题:https://cocodataset.org/#download.点击“2014火车图像”和“2014火车/ val注释”链接。将数据保存在指定的文件夹中 从文件中提取标题 filename = fullfile(datafolder,“annotations_trainval2014”那“注释”那...“captions_train2014.json”);str = fileread(文件名);data = jsondecode (str); 这 有关如何处理这些数据进行深度学习的示例,请参见使用注意力的图像说明. |
图像字幕 |
IAPR TC-12
(代表) |
IAPR TC-12基准[12]包括20,000个仍然自然图像。数据集包括人,动物,城市等照片。数据文件的大小约为1.8 GB。 下载IAPR TC-12数据集。 datadir = fullfile(tempdir,'iaprtc12');url =“http://www-i6.informatik.rwth-aachen.de/imageclef/resources/iaprtc12.tgz”;如果〜存在(Datadir,'dir')fprintf('下载IAPR TC-12数据集(1.8 GB)... \ n');试一试解压(url, dataDir);抓百分比在某些Windows机器上,用于.tgz的Untar命令错误%的文件。重命名为。tg,然后重试。文件名= fullfile (tempdir,“iaprtc12.tg”);WebSave(Filename,URL);Untar(文件名,Datadir);结尾fprintf(“做。\ n \ n”);结尾 使用使用的图像数据存储将数据加载 imageDir = fullfile (dataDir,“图像”)exts = {“jpg”那bmp格式的那“使用”};imd = imageDatastore (imageDir,...'insertumbfolders',真的,...“文件扩展名”,exts); 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的单图像超分辨率. |
Image-to-image回归 |
苏黎世原色到RGB
|
苏黎世RAW到RGB数据集[13]包含48,043个空间注册的原始和RGB培训尺寸448〜448的训练图像贴片。数据集包含两个单独的测试集。一个测试集由1,204个空间注册的原始和RGB图像块的大小为448×448组成。其他测试集包括未注册的全分辨率原始和RGB图像。数据集的大小为22 GB。 创建一个目录以将苏黎世RAW存储到RGB数据集。 imagedir = fullfile(tempdir,'zurichrawtorgb');如果〜存在(Imageager,'dir')mkdir(Imagedir);结尾 我是变量。当成功提取时,我是包含三个目录full_resolution.那测试, 和火车.有关如何处理这些数据进行深度学习的示例,请参见使用深度学习开发原始相机处理管道. |
Image-to-image回归 |
生活在野外
|
生活在野外数据集中[14]由移动设备捕获的1,162张照片,具有7个额外培训图像。每个图像的评分为175个个体,在[1,100]的范围内。数据集提供了每个图像的主观分数的平均值和标准偏差。 创建一个目录以将Live存储在遍布野外数据集中。 imagedir = fullfile(tempdir,“LiveInthewild”);如果〜存在(Imageager,'dir')mkdir(Imagedir);结尾 按照遵循概述的说明下载数据集LIVE In the Wild Image Quality Challenge数据库.将数据提取到指定的目录 有关如何处理这些数据进行深度学习的示例,请参见使用神经图像评估量化图像质量. |
图像分类 |














时间序列和信号数据集
| 数据 | 描述 | 任务 |
|---|---|---|
日语元音
|
日本元音数据集[15][16]包含从不同扬声器中表示日本元音的话语的预处理序列。
将日语元音数据设置为包含数字序列的内存单元阵列,其中包含使用该序列 [Xtrain,Ytrain] = JapanesevowelstrainData;[xtest,ytest] =日本韦沃尔斯特迪塔 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习序列分类. |
序列到标签分类 |
水痘
|
水痘数据集包含一个时间序列,时间步长对应于几个月和值对应于案例的数量。输出是单元阵列,其中每个元素是单个时间步长。 控件将水痘数据作为单个数字序列加载 数据= chickenpox_dataset;数据=({}):数据;
有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的时间序列预测. |
时间序列预测 |
人类活动
|
人类活动数据集包含从身体上佩戴的智能手机获得的七个时间序列。每个序列具有三个特征,长度变化。三个特征对应于三个不同方向的加速度计读数。 加载人类活动数据集。 dataTrain =负载(“HumanActivityTrain”);人数(=负载(“HumanActivityTest”);XTrain = dataTrain.XTrain;YTrain = dataTrain.YTrain;XTest = dataTest.XTest;欧美= dataTest.YTest; 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的序列到序列分类. |
序列到序列分类 |
涡扇发动机退化仿真
|
每个时间序列的涡轮机发动机劣化模拟数据集[17]代表一个不同的发动机。每个发动机从未知程度的初始磨损和制造变化开始。发动机正常运行在每次序列的开始时,并在序列期间的某个点在某些位置开发故障。在训练集中,故障的幅度幅度大,直到系统故障增加。 该数据包含一个zip压缩的文本文件,其中26列数字由空格分隔。每一行都是单个操作周期中数据的快照,每一列都是不同的变量。各列对应如下:
创建一个目录以存储TurboOman引擎劣化模拟数据集。 dataFolder = fullfile (tempdir,“涡扇”);如果~exist(数据文件夹,'dir'mkdir (dataFolder);结尾 下载并提取涡轮机发动机劣化模拟数据集https://ti.art.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/. 从文件中解压缩数据 filename =.“CMAPSSData.zip”;解压缩(文件名,dataFolder)
使用辅助功能加载培训和测试数据 oldpath = addpath(fullfile(matlabroot,'例子'那“nnet”那“主要”));filenamePredictors = fullfile (dataFolder,“train_FD001.txt”);[XTrain,YTrain]=processTurboFanDataTrain(FileNamePredictor);FileNamePredictor=fullfile(dataFolder,“test_FD001.txt”);filenamersponses = fullfile(datafolder,“RUL_FD001.txt”);[XTest,YTest]=processTurboFanDataTest(FileNamePredictor,filenameResponses); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习的序列到序列回归. 要恢复路径,请使用 路径(旧路径); |
序列到序列回归,预测性维护 |
PhysioIonet 2017挑战
|
PhysoioNet 2017挑战数据集[19]由一组专家以300赫兹采样的一组心电图记录组成,并将其分为不同类别。 下载和提取PhysioNet 2017 Challenge数据集使用 数据集约95mb。根据你的互联网连接,下载过程可能需要一些时间。 oldpath = addpath(fullfile(matlabroot,'例子'那'deeplearning_shared'那“主要”));ReadPhysionetData data = load(“PhysionetData.mat”) signals = data.Signals;标签= data.Labels; 有关如何处理这些数据进行深度学习的示例,请参见基于长短时记忆网络的心电信号分类. 要恢复路径,请使用 路径(旧路径); |
序列到标签分类 |
田纳西州伊士曼流程(TEP)模拟
|
该数据集由由Tennessee Eastman Process (TEP)模拟数据转换而成的MAT文件组成。 下载Tennessee Eastman Process (TEP)模拟数据集[18]从MathWorks支持文件站点(请参万博1manbetx阅免责声明)。数据集有四个组件:无故障培训,无故障测试,训练故障和错误的测试。单独下载每个文件。 数据集约为1.7 GB。根据您的Internet连接,下载过程可能需要一些时间。 fprintf("下载TEP故障训练数据(613 MB)…")filenamefaultytrain = matlab.internal.examples.DownloadS万博1manbetxupportFile('predmaint'那...“chemical-process-fault-detection-data / faultytraining.mat”);fprintf(“完成。\ n”)fprintf(“下载TEP故障测试数据(1 GB)......”filenameFaultyTest = matlab.internal.examples.downloadSu万博1manbetxpportFile('predmaint'那...'化学过程 - 故障检测 - 数据/故障.MAT');fprintf(“完成。\ n”)fprintf("下载TEP无故障训练数据(36mb)…") filenameFaultFreeTrain = matlab.internal.examples.download万博1manbetxSupportFile('predmaint'那...'化学过程 - 故障检测数据/故障汇流.MAT');fprintf(“完成。\ n”)fprintf(“下载TEP无故障测试数据(69 MB)......”) filenameFaultFreeTest = matlab.internal.examples.download万博1manbetxSupportFile('predmaint'那...“chemical-process-fault-detection-data / faultfreetesting.mat”);fprintf(“完成。\ n”) 将下载的文件加载到MATLAB中®工作区。 load(filenamefaultytrain);加载(filenamefaultytest);加载(FilenameFaultFreeTrain);加载(filenamefaultfreetest); 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的化工过程故障检测. |
序列到标签分类 |
物理体心电图分割
|
物理体ECG分段数据集[19][20]由总共105名患者大约15分钟的ECG记录组成。为了获得每次记录,检查人员在患者胸部的不同位置放置两个电极,从而产生双通道信号。数据库提供由自动专家系统生成的信号区域标签。 下载PhysioNet心电分割数据集从https://github.com/mathworks/physionet_ecg_segumentation.通过下载zip文件 downloadFolder = tempdir;url =“https://github.com/mathworks/physionet_ecg_segentation/raw/master/qt_database-master.zip”;filename = fullfile(downloadFolder,“qt_database-master.zip”);dataFolder = fullfile (downloadFolder,“QT_Database-master”);如果~exist(数据文件夹,“dir”)fprintf(“下载Physionet心电分割数据集(72mb)…”) websave(文件名,url);解压缩(文件名,downloadFolder);fprintf(“完成。\ n”)结尾 解压缩创建文件夹
负载(fullfile (dataFolder'qtdata.mat'))
有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的波形分割. |
序列-标签分类,波形分割 |
合成行人,汽车和自行车后散射
|
使用辅助功能生成合成行人,汽车和自行车背散射数据集 辅助函数 辅助函数 oldpath = addpath(fullfile(matlabroot,'例子'那“分阶段”那“主要”));numPed = 1;%行人实现的数量numbic = 1;百分比骑自行车型的次数numCar=1;%汽车实现数量[XPedREC,XBICREC,Xcarrec,Tsamp] = Helper BackScattersignals(Numped,Numbic,Numcar);[Sped,T,F] = Helperdopplersignatures(XPedrec,Tsamp);[SBIC,〜,〜] = Helperdopplersignatures(Xbicrec,Tsamp);[疤痕,〜,〜] = Helperdopplersignatures(Xcarrec,Tsamp); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习的行人和自行车分类. 要恢复路径,请使用 路径(旧路径); |
序列到标签分类 |
生成波形
|
使用辅助功能生成矩形,线性FM和相位编码波形 辅助函数 oldpath = addpath(fullfile(matlabroot,'例子'那“分阶段”那“主要”)); [wav,modType]=HelperGeneratorDarWaveforms; 有关如何处理这些数据进行深度学习的示例,请参见基于深度学习的雷达和通信波形分类. 要恢复路径,请使用 路径(旧路径); |
序列到标签分类 |




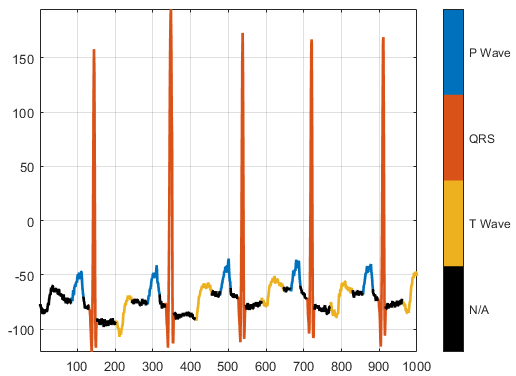

视频数据集
| 数据 | 描述 | 任务 |
|---|---|---|
HMDB:一个大型的人体运动数据库
(代表) |
HMBD51数据集包含来自51类的7000个剪辑的大约2 GB的视频数据,例如喝那运行, 和俯卧撑. 下载并提取HMBD51数据集HMDB:一个大型的人体运动数据库.数据集约为2gb。根据你的网络连接,下载过程可能需要一些时间。 提取RAR文件后,使用helper函数获取视频的文件名和标签 oldpath = addpath(fullfile(matlabroot,'例子'那“nnet”那“主要”));dataFolder = fullfile (tempdir,“hmdb51_org”);(文件、标签)= hmdb51Files (dataFolder); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习分类视频. 要恢复路径,请使用 路径(旧路径); |
视频分类 |

文本数据集
| 数据 | 描述 | 任务 |
|---|---|---|
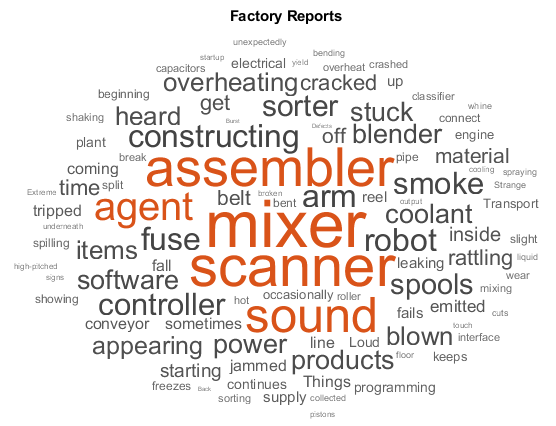
工厂的报告
|
Factory Reports数据集是一个包含大约500个报告的表,这些报告具有各种属性,包括变量中的纯文本描述 阅读工厂从文件中报告数据 filename =.“factoryreports.csv”;数据= readtable(文件名,“TextType”那“字符串”);textdata = data.description;标签= data.category; 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习对文本数据进行分类. |
文本分类,主题建模 |
莎士比亚的十四行诗
|
文件 从文件中阅读莎士比亚的十四赛数据 filename =.“sonnets.txt”; textData=fileread(文件名);
SONNET由两个空格字符缩进,并被两个换行符分隔。使用缩进使用 textdata = replace(textdata,“那“);textData = split(textData,[newline newline]); / /输出textData = textData(5:2:结束); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习生成文本. |
主题建模、文本生成 |
Arxiv元数据
|
ARXIV API允许您访问提交的科学电子版的元数据https://arxiv.org包括摘要和主题领域。有关更多信息,请参见https://arxiv.org/help/api. 使用arXiV API从数学论文中导入一组摘要和类别标签。 url =“https://export.arxiv.org/oai2?verb=listrecords”+...“&set = math”+...“&metadataprefix = Arxiv”;选择= weboptions (“超时”,160);代码= Webrabread(URL,选项); 有关如何解析返回的XML代码并导入更多记录的示例,请参见基于深度学习的多标签文本分类. |
文本分类,主题建模 |
古登堡计划的书籍
|
你可以从古登堡计划下载很多书。例如,下载刘易斯·卡罗尔的《爱丽丝梦游仙境》https://www.gutenberg.org/files/11/11-h/11-h.htm使用 url =“https://www.gutenberg.org/files/11/11-h/11-h.htm”;代码= Webrabread(URL);
HTML代码包含内部相关文本 树= htmlTree(代码);选择器=“P”;子树= findElement(树,选择器);
使用 textdata = extracthtmltext(子树);TextData(TextData ==“) = [];
有关如何处理这些数据进行深度学习的示例,请参见使用深度学习逐字生成文本. |
主题建模、文本生成 |
周末更新
|
文件 从文件中提取文本数据 filename =.“weekendUpdates.xlsx”;台= readtable(文件名,“TextType”那“字符串”);textdata = tbl.textdata; 有关如何处理此数据的示例,请参见分析文本情绪(文本分析工具箱). |
情绪分析 |
罗马数字
|
CSV文件 从CSV文件加载小数-罗马数字对 文件名= fullfile (“romannumerals.csv”);选项= detectimportoptions(文件名,...“TextType”那“字符串”那...“ReadVariableNames”、假);选项。VariableNames = [“来源”“目标”];选项。VariableTypes = [“字符串”“字符串”];data = readtable(文件名,选择); 有关如何处理这些数据进行深度学习的示例,请参见使用注意的顺序翻译. |
Sequence-to-sequence翻译 |
财务报告
|
美国证券交易委员会(SEC)允许您通过电子数据收集、分析和检索(EDGAR) API访问财务报告。有关更多信息,请参见https://www.sec.gov/edgar/searchedgar/accessing-edgar-data.htm. 要下载这些数据,请使用该函数 年= 2019;季度= 4;最大长度= 2 e6;textData = financeReports(年、季度、最大长度); 有关如何处理此数据的示例,请参见生成领域特定情感词典(文本分析工具箱). |
情绪分析 |






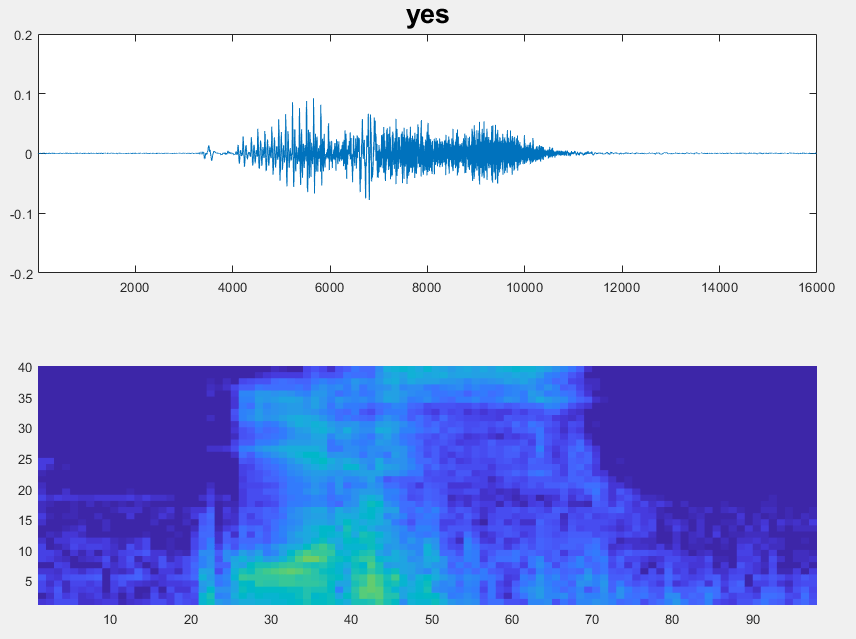
音频数据集
| 数据 | 描述 | 任务 |
|---|---|---|
语音命令
|
语音命令数据集[21]由大约65,000个音频文件组成,标有1个中的1个课程,包括是的那不那在, 和离开以及对应于未知命令和背景噪声的类。 下载并提取语音命令数据集https://storage.googleapis.com/download.tensorflow.org/data/speech_commands_v0.01.tar.gz..数据集约为1.4 GB。根据你的网络连接,下载过程可能需要一些时间。 放 dataFolder = tempdir;广告= audiodataStore(DataFolder,...'insertumbfolders',真的,...“文件扩展名”那“wav”那...“LabelSource”那“foldernames”); 有关如何处理这些数据进行深度学习的示例,请参见使用深度学习的言语命令识别. |
音频分类,语音识别 |
Mozilla共同的声音
|
Mozilla通用语音数据集包括语音录音和相应的文本文件。数据还包括人口统计元数据,如年龄、性别和口音。 下载并提取Mozilla Common Voice数据集https://voice.mozilla.org/.数据集是开放数据集,这意味着它可以随时间增长。截至2019年10月,数据集约为28gb。根据你的网络连接,下载过程可能需要一些时间。放 dataFolder = tempdir;广告= audioDatastore (fullfile (dataFolder,“剪辑”));
有关如何处理这些数据进行深度学习的示例,请参见使用GRU网络对性别进行分类. |
音频分类,语音识别。 |
免费口头数字数据集
|
截止到2019年1月29日,“自由口语数字数据集”是由4名演讲者的2000段英语数字0到9的录音组成的。在这个版本中,两名讲话者的母语是美国英语,两名讲话者的母语是非英语,分别带有比利时、法国和德国口音。数据采样频率为8000 Hz。 下载自由语音数字数据集(FSDD)录音https://github.com/jakobovski/free-spoken-digit-dataset.. 放 dataFolder = fullfile (tempdir,'自由发言 - DataSet'那'录音');广告= audiodataStore(DataFolder); 有关如何处理这些数据进行深度学习的示例,请参见基于小波散射和深度学习的语音数字识别. |
音频分类,语音识别。 |
柏林情感演讲数据库
|
柏林情感语言数据库[22]包含由10个演员说出的535个话语,旨在传达以下情绪之一:愤怒、无聊、厌恶、焦虑/恐惧、快乐、悲伤或中性。情感是独立于文本的。 文件名是表示说话者ID、所讲文本、情感和版本的代码。该网站包含破译密码的钥匙,以及演讲者的性别和年龄等附加信息。 下载来自情绪演讲的柏林数据库http://emodb.bilderbar.info/index-1280.html..数据集大约是40mb。根据你的互联网连接,下载过程可能需要一些时间。 放 dataFolder = tempdir;广告= audioDatastore (fullfile (dataFolder,“wav”));
有关如何处理这些数据进行深度学习的示例,请参见语音情感识别. |
音频分类,语音识别。 |
TUT声学场景2017
|
下载并提取TUT声学场景2017数据集[23]从…起TUT声学场景2017,开发数据集和TUT声学场景2017,评估数据集. 该数据集由来自15个声学场景的10秒音频片段组成,包括公共汽车那汽车, 和图书馆. 有关如何处理这些数据进行深度学习的示例,请参见声学场景识别使用后期融合. |
声场景分类 |

工具书类
[1] Lake,Brenden M.,Ruslan Salakhutdinov和Joshua B. Tenenbaum。“通过概率方案诱导学习人类概念。”科学类350年,没有。6266(2015年12月11日):1332-38。https://doi.org/10.1126/science.aab3050。
[2] Tensorflow团队。“花卉”https://www.tensorflow.org/datasets/catalog/tf_flowers.
[3] Kat,郁金香, 图片,https://www.flickr.com/photos/swimparallel/3455026124.知识共享许可证(抄送人)。
[4] Rob Bertholf,向日葵, 图片,https://www.flickr.com/photos/tobbertholph/20777358950.Creative Commons 2.0通用许可证。
[5] Parvin,玫瑰, 图片,https://www.flickr.com/photos/55948751@N00.Creative Commons 2.0通用许可证。
[6]约翰·海斯蓝蒲公英, 图片,https://www.flickr.com/photos/foxypar4/645330051..Creative Commons 2.0通用许可证。
[7] Krizhevsky,亚历克斯。"从微小图像中学习多层特征"硕士论文,多伦多大学,2009。https://www.cs.toronto.edu/%7ekriz/learning-features-2009-tra.pdf..
Brostow, Gabriel J., Julien Fauqueur和Roberto Cipolla。《视频中的语义对象类:高清地面真实数据库》模式识别的字母30,没有。2(2009年1月):88-97。https://doi.org/10.1016/j.patrec.2008.04.005
[9] Kemker,Ronald,Carl Salvaggio和Christopher Kanan。“语义细分的高分辨率多光谱数据集。”ArXiv: 1703.01918 (Cs),2017年3月6日。https://arxiv.org/abs/1703.01918
Isensee, Fabian, Philipp Kickingereder, Wolfgang Wick, Martin Bendszus和Klaus H. Maier-Hein。脑肿瘤分割和放射组学生存预测:对BRATS 2017挑战的贡献在脑损伤:胶质瘤,多发性硬化症,中风和创伤性脑损伤, Alessandro Crimi, Spyridon Bakas, Hugo Kuijf, Bjoern Menze, and Mauricio Reyes编辑,10670:287-97。瑞士Cham:施普林格International Publishing, 2018。https://doi.org/10.1007/978-3-319-75238-9_25
Ehteshami Bejnordi, Babak, Mitko Veta, Paul Johannes van Diest, Bram van Ginneken, Nico Karssemeijer, Geert Litjens, Jeroen A. W. M. van der Laak, et al.“深度学习算法检测乳腺癌女性淋巴结转移的诊断评估”。《美国医学会杂志》318年,没有。22(2017年12月12日):2199。https://doi.org/10.1001/jama.2017.14585
[12] Grubinger,M.,P. Clough,H.Müller和T. Deselaers。“IAPR TC-12基准测试:用于视觉信息系统的新评估资源。”基于内容的图像检索的odimage 2006语言资源的程序。热那亚,意大利。卷。5,2006年5月,p。10。
[13] Ignatov,Andrey,Luc Van Gool和Radu Townofte。“用一个深入学习模型替换移动相机ISP。”ArXiv: 2002.05509 (Cs,套)2020年2月13日。http://arxiv.org/abs/2002.05509。项目网站.
[14] 现场:图像和视频工程实验室。https://live.ece.utexas.edu/research/ChallengeDB/index.html.
[15] Kudo,Mineichi,Jun Toyama和Masaru Shimbo。“使用过度区域的多维曲线分类。”模式识别字母20,否。11-13(1999年11月):1103-11。https://doi.org/10.1016/s0167-8655(99)00077-x.
[16] Kudo,Mineichi,Jun Toyama和Masaru Shimbo。日本元音数据集.由UCI机器学习存储库分发。https://archive.ics.uci.edu/ml/datasets/Japanese+Vowels
萨克森,阿比纳夫,凯·戈贝尔。涡扇发动机退化模拟数据集NASA AMES预测数据存储库https://ti.art.nasa.gov/tech/dash/groups/pcoe/prognostic-data-repository/,美国宇航局阿米斯研究中心,迈夫特田,加州
[18] Rieth,Cory A.,Ben D. Amsel,Randy Tran和Maia B.厨师。“额外的田纳西州Eastman流程用于异常检测评估的模拟数据。”哈佛Dataverse,版本1,2017。https://doi.org/10.7910/DVN/6C3JR1.
[19] 戈德伯格、阿瑞·勒、路易斯·阿马拉尔、利昂·格拉斯、杰弗里·豪斯多夫、普拉曼·伊万诺夫、罗杰·G·马克、约瑟夫·E·密特斯、乔治·B·穆迪、钟康鹏和H·尤金·斯坦利。“生理库、生理工具包和生理网:复杂生理信号新研究资源的组成部分。”循环101,23,2000,PP。E215-E220。https://circ.ahajournals.org/content/101/23/E215.FULL.
[20] Laguna,Pablo,Roger G. Mark,Ary L. Goldberger和George B. Moody。“用于评估ECG中QT和其他波形间隔的算法的数据库。”心脏病学中的计算机24,997,第673-676页。
[21]监狱长P。“语音指令:单字语音识别的公共数据集”,2017。可以从http://download.tensorflow.org/data/speech_commands_v0.01.tar.gz..版权所有Google 2017.语音命令DataSet在Creative Commons归因4.0许可下许可,可在此处提供:https://creativeCommons.org/licenses/by/4.0/Legalcode..
[22] Burkhardt,Felix,Astrid Paeschke,Melissa A. Rolfes,Walter F. Sendlmeier,以及Benjamin Weiss。“德国情绪言论的数据库。”2005年的Interspeech程序.里斯本,葡萄牙:国际言论协会,2005年。
[23] Mesaros,Annamaria,Toni Heittola和Tuomas Virtanen。“声学场景分类:DCEAD 2017挑战条目的概述。”在2018年第16届关于声学信号增强国际研讨会(IWAENC), 411 - 415页。IEEE 2018。
也可以看看
相关话题
你也可以从以下列表中选择一个网站:
