单因素模型校准
演示技术校准估计的单因素模型组合使用的信贷损失creditDefaultCopula或creditMigrationCopula类。
这个示例使用股票返回数据来衡量信贷波动。股票数据,对单因素敏感性估计股票之间的相关性和索引。数据集包含一系列股票的每日返回数据,但需要校准在同比基础上的单因素模型。假设不存在自相关,那么每天的股票和市场指数之间的互相关等于年度互相关。对股市表现自相关,这个例子展示了如何计算隐含年度相关性将自相关的影响。
配件单因素模型
自企业违约是罕见的,通常使用一个代理信誉当校准违约模型。单因素介体模型的信用公司使用一个潜变量,一个:
在哪里X是系统性的信用因素,w是重量,它定义了公司的一个因素的敏感性,然后呢
是特殊的因素。w和
1 0均值和方差,通常假定为高斯或其他t分布。
计算之间的关系X和一个:
自X和一个有差异的1通过建设和
是不相关的X,那么:
如果你使用股票收益作为代表一个和市场指数的回报是一个代理X,那么重量参数,w是股票、指数之间的相关性。
准备数据
使用返回的道琼斯工业平均指数)为信号的整体信贷运动市场。30家组件公司的收益用于校准每个公司信贷系统运动的敏感性。权重估计其他公司在股票市场上以同样的方式。
%读一年吗价格数据。t = readtable (“dowPortfolio.xlsx”);%的表包含日期和价格为每一个公司在市场关闭%以及道琼斯工业指数的。disp(头(t (: 1:7)))
日期收AA AIG AXP英航C ___________ _____ _____ _____ _____ _____ _____ 03 - 10847年1月- 2006年04 - 28.72 68.41 51.53 68.63 45.26 28.89 68.51 51.03 69.34 44.42 10880年1月- 2006年05 - 10882年1月- 2006年06年29.12 68.6 51.57 68.53 44.65 - 29.02 68.89 51.75 67.57 44.65 10959年1月- 2006年09 - 11012年1月- 2006年10 - 29.37 68.57 53.04 67.01 44.43 28.44 69.18 52.88 67.33 44.57 11012年1月- 2006年11 - 28.05 69.6 52.59 68.3 44.98 11043年1月- 2006年12 - 10962年1月- 2006 27.68 69.04 52.6 67.9 45.02
%我们单独的日期和索引表和计算每日返回使用% tick2ret。日期= t){2:最终,1};index_adj_close = t {: 2};stocks_adj_close = t{: 3:结束};index_returns = tick2ret (index_adj_close);stocks_returns = tick2ret (stocks_adj_close);
计算单因素权重
计算的单因素权重指数的回报率,股票回报率之间的相关系数为每个公司。
[C, daily_pval] = corr ([index_returns stocks_returns]);w_daily = C(2:结束,1);
使用单因素时可以直接使用这些值creditDefaultCopula或creditMigrationCopula。
线性回归是常用的因素模型。单因素模型,线性回归股票市场回报率的回报被利用的相关系数匹配的平方根确定系数(R线性回归的平方)。
w_daily_regress = 0(30日1);为我= 1:30 lm = fitlm (index_returns stocks_returns(:,我));w_daily_regress (i) =√lm.Rsquared.Ordinary);结束%退化R值等于该指数相关性。流(“马克斯Abs Diff: e % \ n”马克斯(abs (w_daily_regress (:)——w_daily (:))))
马克斯Abs Diff: 8.326673 e-16
这一线性回归的模型形式相吻合 ,这在一般的单因素模型规范不匹配。例如, 和 没有一个零均值和标准偏差为1。一般来说,没有系数之间的关系 和误差项的标准差 。线性回归上面只作为一种工具来使用的变量之间的相关系数的平方根R平方值。
单因素模型校准,一个有用的替代方法是适合使用标准线性回归股票和市场返回数据 和 。这里的“标准化”是指减去均值和除以标准差。模型是 。然而,因为 和 有一个零均值,拦截 永远是零,因为两个吗 和 标准差为1,标准偏差的误差项满足吗 。这完全匹配的规格单因素模型的系数。单因素参数 将系数 和是一样的价值发现,直接通过相关性。
w_regress_std = 0(30日1);index_returns_std = zscore (index_returns);stocks_returns_std = zscore (stocks_returns);为我= 1:30 lm = fitlm (index_returns_std stocks_returns_std(:,我));w_regress_std (i) = lm.Coefficients {x1的,“估计”};结束%退化R值等于该指数相关性。流(“马克斯Abs Diff: e % \ n”马克斯(abs (w_regress_std (:)——w_daily (:))))
马克斯Abs Diff: 5.551115 e-16
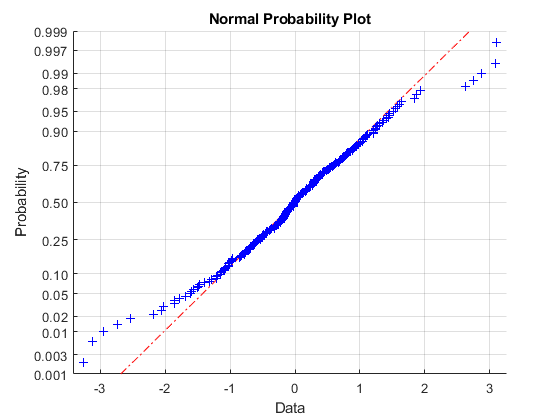
这种方法使其自然探索变量的分布假设。的creditDefaultCopula和creditMigrationCopula对象支持正常的分万博1manbetx布,或t潜在变量的分布。例如,当使用normplot市场回报率有沉重的尾巴,因此t连系动词更一致的数据。
normplot (index_returns_std)
估计的长期相关性
权重计算基于每日股票和指数之间的相关性。然而,通常的目标是潜在的损失估计在未来一段时间进一步从信用违约,通常一年。
为此,有必要调整权重,这样他们对应,一年期的相关性。是不实际的调整直接对历史年回报率数据因为任何合理的数据集没有足够的数据统计上显著的数据点的稀疏。
你面临的问题是计算年收益率相关性更频繁地从一个采样数据集,例如,日常的回报。解决这个问题的一个方法是使用一个重叠窗口。这样你可以考虑所有重叠的集合时间的一个给定的长度。
%作为一个例子,考虑一个重叠窗口1周。index_overlapping_returns = index_adj_close(6:结束)。/ index_adj_close(1:录得5个)- 1;stocks_overlapping_returns = stocks_adj_close(6:最后,:)。/ stocks_adj_close 1:录得5个,:- 1;C = corr ([index_overlapping_returns stocks_overlapping_returns]);w_weekly_overlapping = C(2:结束,1);%比较相关的日常相关。%显示每日和每周重叠相关性。barh ([w_daily w_weekly_overlapping]) yticks (1:30) yticklabels (t.Properties.VariableNames(3:结束)标题(“相关的指数”);传奇(“每天”,“重叠周刊”);
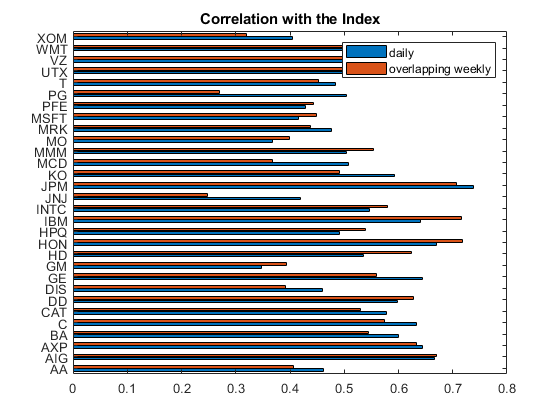
最大互相关p值每天回报表现出强烈的统计学意义。
maxdailypvalue = max (daily_pval(2:最终,1));disp(表(maxdailypvalue…“VariableNames”,{“每天”},…“rownames”,{“最大的假定值”}))
每日__________最大e-08假定值1.5383
搬到一个重叠rolling-window-style每周相关给稍微不同的相关性。这是一个方便的方法来估计长期从日常数据的相关性。然而,相邻重叠窗口的回报相关对应p对于重复每周值返回以来是无效的p值计算的相关系数数据集函数不考虑重叠窗口。例如,相邻重叠窗口返回由许多相同的点。这权衡是必要的,因为搬到不重叠的窗口可能会是一个不可接受的稀疏的样本。
%比较重叠每周回报周五工作日(日期)= = = 6;index_weekly_close = index_adj_close(星期五);:stocks_weekly_close = stocks_adj_close(星期五);index_weekly_returns = tick2ret (index_weekly_close);stocks_weekly_returns = tick2ret (stocks_weekly_close);[C, weekly_pval] = corr ([index_weekly_returns stocks_weekly_returns]);w_weekly_nonoverlapping = C(2:结束,1);maxweeklypvalue = max (weekly_pval(2:最终,1));%比较相关的日常和重叠。barh ([w_daily w_weekly_overlapping w_weekly_nonoverlapping]) yticks (1:30) yticklabels (t.Properties.VariableNames(3:结束)标题(“相关的指数”);传奇(“每天”,“重叠周刊”,“重叠周刊”);

的p值不重叠的每周的相关性要高得多,说明统计学意义的丧失。
%计算样本的数量在每个系列。numDaily =元素个数(index_returns);numOverlapping =元素个数(index_overlapping_returns);numWeekly =元素个数(index_weekly_returns);disp(表([maxdailypvalue; numDaily],[南;numOverlapping], [maxweeklypvalue; numWeekly],…“VariableNames”,{“每天”,“重叠”,“Non_Overlapping”},…“rownames”,{“最大的假定值”,“样本”}))
每日重叠Non_Overlapping __________ ___________售予最大样本量假定值1.5383 e-08南0.66625 250 246 50
根据年度相关
一个共同的假设与金融数据暂时不相关的资产回报。即资产回报时间T是不相关的,前面还在吗T1。在这种假设下,一年一度的互相关正好等于每日互相关。
让 的日常日志返回市场指数在一天t和 的每日返回相关资产。利用CAPM,建模的关系为:
单因素模型是这种关系的一个特例。
假设资产回报率都是相关和索引与各自的过去,然后:
y,
让总年度(日志)换取每个系列
在哪里T可能是252年每天取决于底层数据。
让 和 每日差异,估计从每日返回数据。
每日之间的协方差 和 是:
日常联系 和 是:
考虑总体的方差和协方差的回报。没有相关的假设下:
年度资产之间的相关性和指数:
没有相关的假设下,注意日常互相关实际上是平等的一年一度的互相关。你可以直接使用这个假设在单因素模型通过设置单因素权重的日常互相关。
自相关处理
如果假设资产没有自相关放松,然后转换从日常年度资产之间互相关并不简单。的 现在有附加的条款。
首先考虑最简单的情况下计算的方差
当T等于2。
自 ,那么:
考虑T=3。表明每日回报之间的相关性
天分开
。
在一般情况下,一个总体的方差T天的时间返回后的自相关k天,有:
这也是同样的资产方差公式:
之间的协方差 和 正如前面所示的= 。
因此,与自相关指数和资产之间的互相关后1通过k天是:
请注意, 是没有相关的假设下的重量。平方根项提供了调整占自相关的系列。调整取决于之间的差异指数自相关和股票自相关,而不是这些自我的大小。所以每年的单因素权重调整的自相关是:
计算权重和自相关
寻找相关的股票与前一天的回报,并调整权重将一天的自相关的影响。
corr1 = 0(30日1);pv = 0(30日1);为stockidx = 1:30 [corr1 (stockidx) pv (stockidx)] = corr (stocks_returns(2:结束,stockidx) stocks_returns (1: end-1, stockidx));结束autocorrIdx =找到(pv < 0.05)
autocorrIdx =4×110 18 26日27日
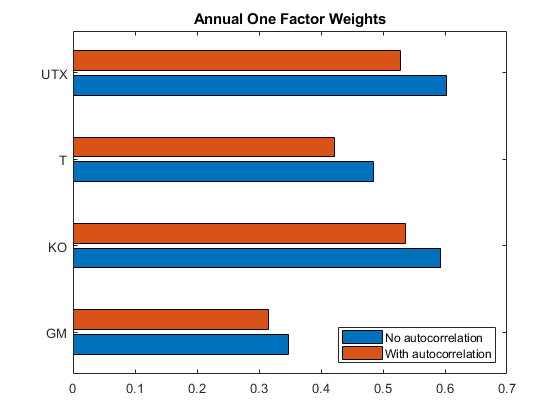
有四个较低的股票p值,这可能表明存在自相关。估计每年的互相关的指数在这种模式下,考虑到为期一天的自相关。
%的权重基于年度交叉相关性等于每日十字架%相关性乘以一个额外的因素。T = 252;w_yearly = w_daily;[rho_index, pval_index] = corr (index_returns (1: end-1) index_returns(2:结束);%检查该指数有显著的相关。流(“一天自相关指数假定值:% f \ n ',pval_index);
有一天自相关指数假定值:0.670196
如果pval_index < 0.05%如果假定值表示没有显著相关指数,%设置其ρ0。rho_index = 0;结束w_yearly (autocorrIdx) = w_yearly (autocorrIdx)。*…√(T / 2 + (T - 1)。* rho_index)。/ (T / 2 + (T - 1)。* corr1 (autocorrIdx)));%比较一年一度的互相关值来调整每日值。barh ([w_daily (autocorrIdx) w_yearly (autocorrIdx)]) yticks (1:4);allNames = t.Properties.VariableNames(3:结束);yticklabels (allNames (autocorrIdx)标题(年度的一个因素权重的);传奇(“不相关”,与自相关的,“位置”,“东南”);
另请参阅
creditDefaultCopula|模拟|portfolioRisk|riskContribution|confidenceBands|getScenarios