适合
局部可解释模型不可知解释(LIME)拟合简单模型
语法
描述
newresults=健康(结果,queryPoint,numImportantPredictors)queryPoint),使用指定数目或预测项(numImportantPredictors).函数返回一个石灰对象newresults其中包含了新的简单模型。
适合属性时指定的简单模型选项石灰对象结果。属性的名称-值对参数可更改选项适合函数。
newresults=健康(结果,queryPoint,numImportantPredictors,名称,值)“SimpleModelType”、“树”拟合决策树模型。
例子
用线性简单模型解释预测
训练一个回归模型并创建一个石灰对象,该对象使用线性简单模型。当你创建石灰对象,如果不指定查询点和重要预测因子的数量,则软件生成合成数据集的样本,但不适合简单的模型。使用object函数适合为查询点拟合一个简单的模型。然后利用目标函数显示拟合后线性简单模型的系数情节。
加载carbig数据集,其中包含20世纪70年代和80年代初生产的汽车的测量数据。
负载carbig
创建一个包含预测变量的表加速度,气缸,等等,以及响应变量英里/加仑。
tbl = table(加速度,气缸,排量,马力,车型年,重量,MPG);
删除训练集中的缺失值可以帮助减少内存消耗并加快fitrkernel函数。中删除缺失的值资源描述。
TBL = rmmissing(TBL);
通过删除响应变量来创建一个预测变量表资源描述。
tblX = removevars(tbl,“英里”);
训练一个黑盒模型英里/加仑通过使用fitrkernel函数。
rng (“默认”)%用于再现性mdl = fitrkernel(tblX,tbl。英里/加仑,“CategoricalPredictors”[2 - 5]);
创建一个石灰对象。指定一个预测器数据集,因为mdl不包含预测器数据。
results = lime(mdl,tblX)
结果= lime with properties: BlackboxModel: [1x1 RegressionKernel] DataLocality: 'global' CategoricalPredictors: [2 5] Type: 'regression' X: [392x6 table] QueryPoint: [] NumImportantPredictors: [] numsynticdata: 5000 synticdata: [5000x6 table] fitting: [5000x1 double] SimpleModel: [] ImportantPredictors: [] blackboxfitting: [] simplemodelfitting: []
结果包含生成的合成数据集。的SimpleModel属性为空([]).
中第一个观测拟合线性简单模型tblX。指定要查找的重要预测因子的数量为3。
queryPoint = tblX(1,:)
queryPoint =1×6表加速气缸位移马力Model_Year重量 ____________ _________ ____________ __________ __________ ______ 12 8 307 130 70 3504
results = fit(results,queryPoint,3);
画出石灰对象结果通过使用对象函数情节。若要在任何预测器名称中显示现有下划线,请更改TickLabelInterpreter轴的值“没有”。
F =图(结果);f.CurrentAxes.TickLabelInterpreter =“没有”;
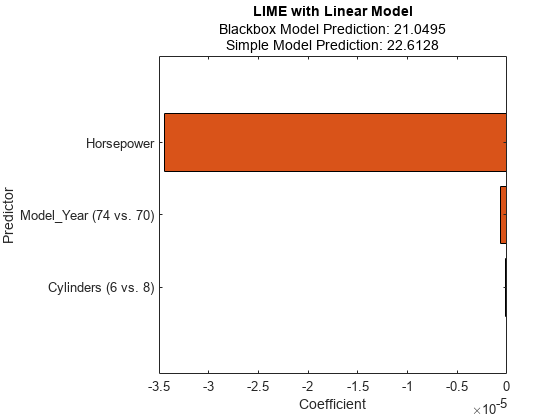
该图显示了查询点的两个预测,它们对应于BlackboxFitted财产和SimpleModelFitted的属性结果。
横柱图显示了简单模型的系数值,按它们的绝对值排序。石灰发现马力,Model_Year,气缸作为查询点的重要预测器。
Model_Year而且气缸是具有多个类别的分类预测器。对于线性简单模型,软件为每个分类预测器创建的虚拟变量比类别数少一个。条形图只显示最重要的虚变量。,可以检查其他虚变量的系数SimpleModel的属性结果。显示排序系数值,包括所有分类虚拟变量。
[~,I] = sort(abs(results.SimpleModel.Beta),“下”);表(results.SimpleModel.ExpandedPredictorNames (I)”,results.SimpleModel.Beta(我),...“VariableNames”, {“扩展预测器名称”,“系数”})
ans =17×2表Exteded预测名字系数 __________________________ ___________ {' -3.4485马力的}e-05 {Model_Year(74和70)的}-6.1279 e-07{“Model_Year(80和70)的}-4.015 e-07{“Model_Year(81和70)的}3.4176 e-07{“Model_Year(82和70)的}-2.2483 e-07{的圆柱体(6和8)}-1.9024 e-07{“Model_Year(76和70)的}1.8136 e-07{的圆柱体(5和8)}1.7461 e-07{“Model_Year(71和70)的}1.558 e-07{“Model_Year(75和70)的}1.5456 e-07{“Model_Year(77和70)的}1.521 e-07 {Model_Year (78 vs。70)'} 1.4272e-07 {'Model_Year (72 vs. 70)'} 6.7001e-08 {'Model_Year (73 vs. 70)'} 4.7214e-08{'气缸(4 vs. 8)'} 4.5118e-08 {'Model_Year (79 vs. 70)'} -2.2598e-08 \
为多个查询点拟合简单模型
训练一个分类模型并创建一个石灰对象,该对象使用决策树简单模型。为多个查询点拟合多个模型。
加载CreditRating_Historical数据集。数据集包含客户id及其财务比率、行业标签和信用评级。
可读的(“CreditRating_Historical.dat”);
通过删除客户id和评分列,创建一个预测变量表资源描述。
tblX = removevars(tbl,[“ID”,“评级”]);
训练信用评级的黑盒模型fitcecoc函数。
blackbox = fitcecoc(tblX,tbl。评级,“CategoricalPredictors”,“行业”)
blackbox = ClassificationECOC PredictorNames: {1x6 cell} ResponseName: 'Y' categoricalpredictortors: 6 ClassNames: {'A' 'AA' 'AAA' 'B' 'BB' 'BBB' 'CCC'} ScoreTransform: 'none' BinaryLearners: {21x1 cell} CodingName: 'onevsone'属性,方法
创建一个石灰对象的黑箱模型。
rng (“默认”)%用于再现性结果=石灰(黑箱);
找到两个真实评级值为的查询点AAA而且B,分别。
queryPoint(1,:) = tblX(find(strcmp(tbl。评级,“AAA”), 1):);queryPoint(2,:) = tblX(find(strcmp(tbl。评级,“B”), 1),:)
queryPoint =2×6表WC_TA RE_TA EBIT_TA MVE_BVTD S_TA行业 _____ _____ _______ ________ _____ ________ 12 0.121 0.413 0.057 3.647 0.466 0.019 0.009 0.042 0.257 0.119 1
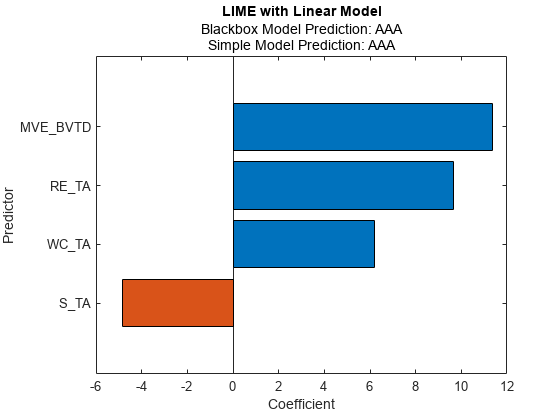
为第一个查询点拟合一个线性简单模型。将重要预测因子的数量设置为4。
newresults1 = fit(results,queryPoint(1,:),4);
绘制LIME结果图newresults1对于第一个查询点。若要在任何预测器名称中显示现有下划线,请更改TickLabelInterpreter轴的值“没有”。
F1 = plot(newresults1);f1.CurrentAxes。TickLabelInterpreter =“没有”;
为第一个查询点拟合线性决策树模型。
newresults2 = fit(results,queryPoint(1,:),6,“SimpleModelType”,“树”);F2 = plot(newresults2);f2.CurrentAxes。TickLabelInterpreter =“没有”;
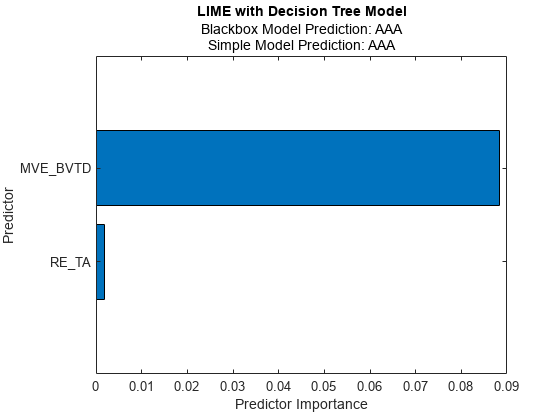
中的简单模型newresults1而且newresults2这两个发现MVE_BVTD而且RE_TA作为重要的预测指标。
为第二个查询点拟合线性简单模型,并绘制第二个查询点的LIME结果。
newresults3 = fit(results,queryPoint(2,:),4);F3 = plot(newresults3);f3.CurrentAxes。TickLabelInterpreter =“没有”;
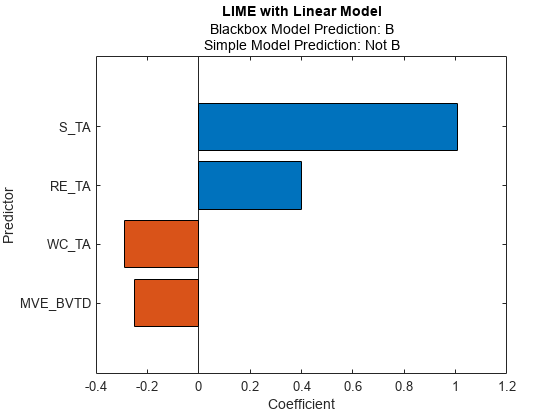
预测来自黑箱模型是B,但简单模型的预测并非如此B。当两个预测值不一致时,可以指定一个较小的“KernelWidth”价值。该软件使用更关注查询点附近样本的权重来拟合一个简单的模型。如果查询点是一个离群值或位于决策边界附近,那么两个预测值可能是不同的,即使您指定了一个小的“KernelWidth”价值。在这种情况下,您可以更改其他名称-值对参数。例如,您可以生成一个本地合成数据集(指定“DataLocality”的石灰作为“本地”)为查询点,并增加样本数量(“NumSyntheticData”的石灰或适合)。您也可以使用不同的距离度量(“距离”的石灰或适合).
拟合线性简单模型与小“KernelWidth”价值。
newresults4 = fit(results,queryPoint(2,:),4,“KernelWidth”, 0.01);F4 = plot(newresults4);f4.CurrentAxes。TickLabelInterpreter =“没有”;
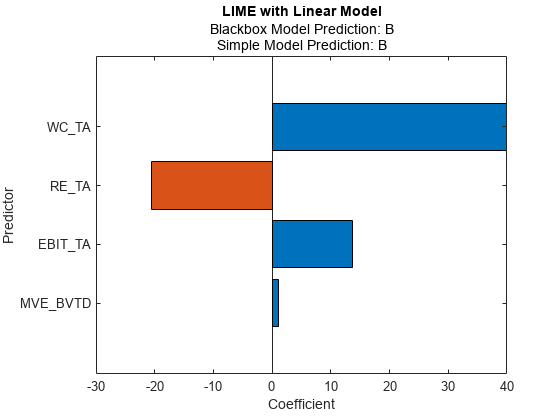
第一个和第二个查询点的信用评级为AAA而且B,分别。中的简单模型newresults1而且newresults4这两个发现MVE_BVTD,RE_TA,WC_TA作为重要的预测指标。但是,它们的系数值是不同的。图表显示,这些预测因素根据信用评级的不同而有所不同。
输入参数
输出参数
更多关于
算法
参考文献
您也可以从以下列表中选择一个网站:
