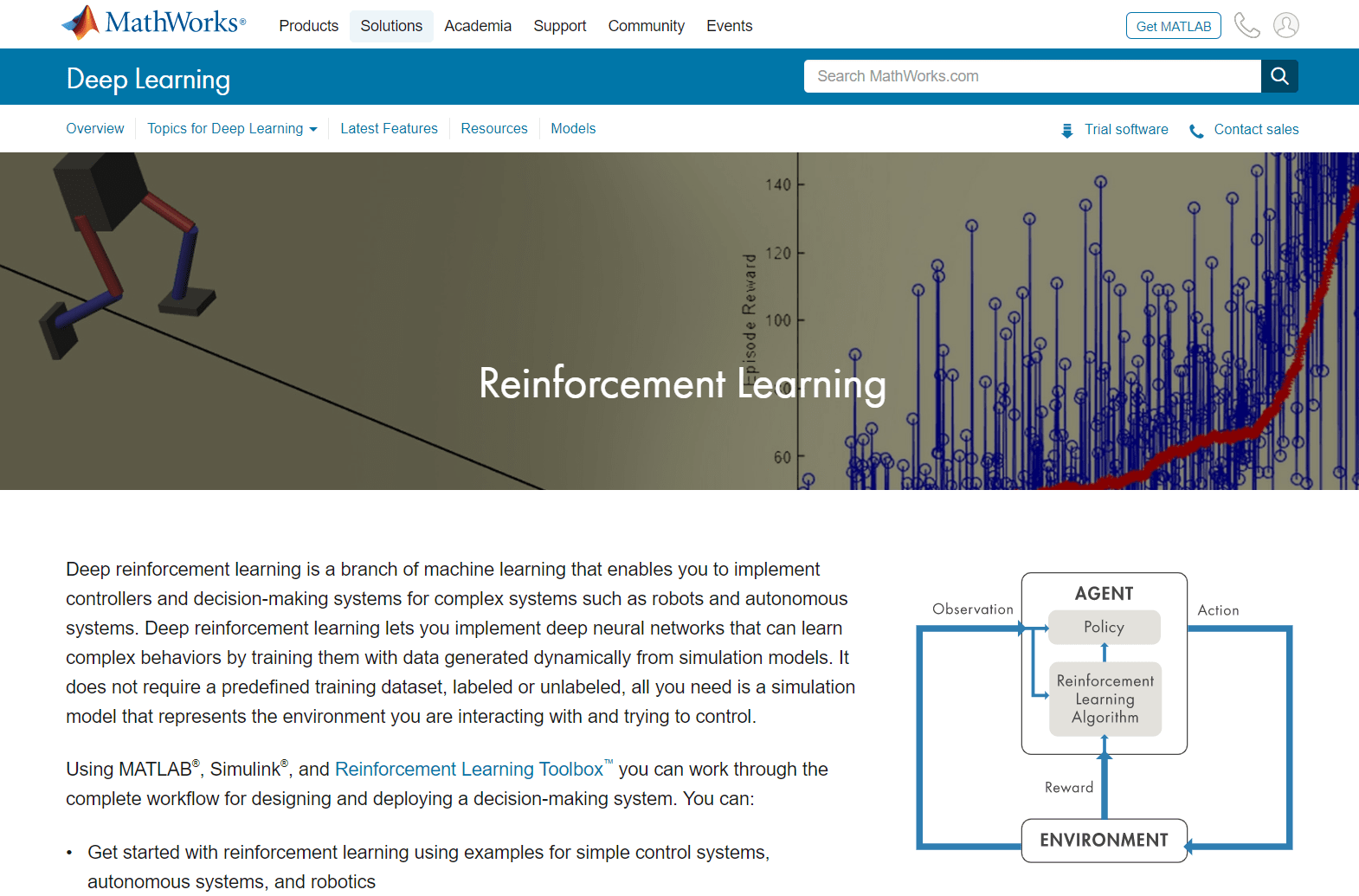
强化(加固学习)とは,机械学习の种コンピューターエージェントが动环境と,缲り返し试行错误やりとりをを重ねる重ねることことことによってによってタスクをを実行できるできるようようにになる手法手法です。。このこのこの学习によりによりによりにより决定をます人间がし,をするためために明示的ににプログラムししたりする必要必要はは
强化たたたたプログラムプログラム,やチェスなどのゲームゲームやビデオビデオゲームゲームゲームにおいてにおいて,人间ののプレイヤープレイヤーととのの胜负でで胜利胜利ををを收め收め收めて。。。强化强化ディープラーニングや计算の进歩により,AI(人工能)の分野目覚ましいをもたらています。
强化学习机械学习ディープラーニングの违い
学习の(1)。/教师教师教师机械机械学习とはは异なり,学习学习は静的ななセットセットに依存依存せせ动的なななしますポイントすなわち経験経験,环境とソフトウェアので试行试行错误ののののやりとりやりとりを通し通し学习学习中中ににさされます。。これはは强化教师あり学习や教师なし学习必要と,学习前のデータ收集前处理,ラベルがが不要不要にになるなるなるなるからからからです。。つまり,,,事実事実事実上上上上上上,适切适切なななインセンティブインセンティブがががあれあれ自体での学习开始できます。
33はははは种类机械学习に及び,そしてとととディーディープラーニングプラーニングプラーニングははは相互に排他排他的ななものものではありではありませませません。。。多く多く多くのの场合场合,,学习学习ます。,深层学习として知ら分野。。。
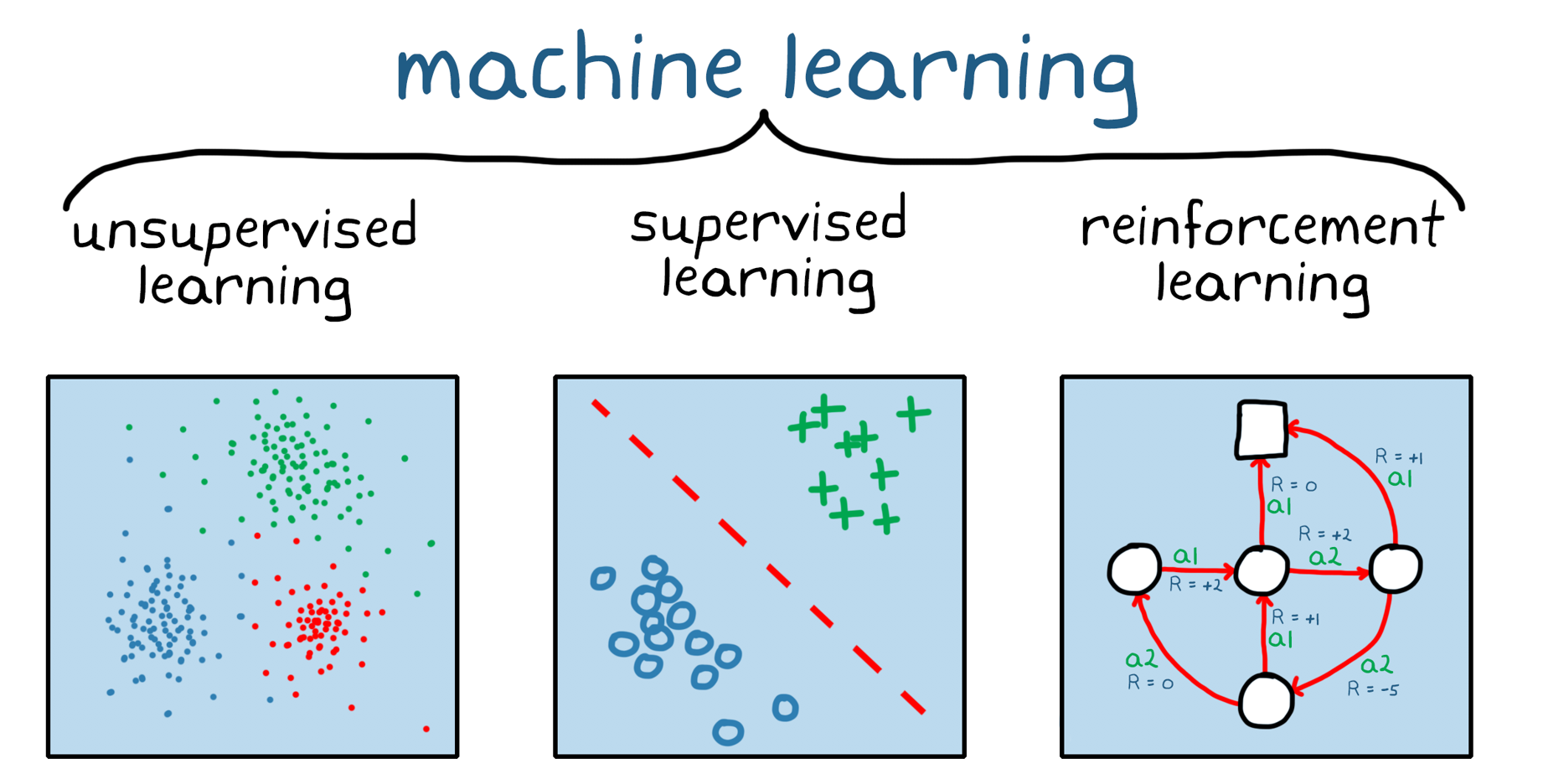
1. 1.机械学习のつのカテゴリ:教师教师学习教师あり,强化。。。

强化学习の例
强化学习用いて学习たたディープニューラルネットワークでは复雑行动符号化ことができます。そのため,方法方法でではは扱い扱い扱いづらかっづらかったり,取り组み取り组みがが困难困难なな用途用途に対してに対して,,别别ののののアプローチがとなりなりなりなりLIDAR测定のセンサーを同时に确认,运転に代わっニューラルネットワークネットワークネットワークがハンドルハンドルハンドルのの切り方方を决める决めることができことができますニューラルニューラルネットワークがなけれなけれ特徴抽出LIDAR测定测定値フィルタリング,,センサー出力の融合,センサー基づく运転」の意思に细分化され。
强化学习は运用システム向けとして段阶ですが,この技术はは次のようような产业用途用途ににに适し
高度な制御::非线形制御困难困难问题であり多く场合场合动作点でシステムシステムををを线形化化しし対応しますます。强化强化强化学习
自动运転:画像アプリケーションニューラルの成功考える考える入力基づく运転の意思意思决定は,强化学习学习が适し适しててて
ロボティクス::强化学习ピックプレースアプリケーションのさまざまオブジェクトをするするロボットロボットアームににに学习学习さとといったた,,ロボットロボットによる把持把持操作のののようような用途用途に役立ちますなど,工学用途はにわたります。
スケジューリング:スケジューリング问题,机のや,目的に対する工场のリソースリソース调整などなどなどのの多く多くの场面で见受け见受けられられますます。强化强化学习ははは,,,のの组合使用することができ。
キャリブレーション:电子ユニット(ECU)のの,のキャリブレーション伴う用途は强化学习に适し适してと言え言え
强化学习さ学习学习には,世界のが数多く反映反映さされれれてていますますたとえばたとえば,正正正のの强化によるによる

図2.犬犬しつけにおける学习。。
(2)をををすると场合の学习,犬犬犬(エージェント)のしつけ(学习)のしつけ(学习)をををの环境士がれますます。,训练士士や合図合図合図を出し出し出し出し,()目的行动近い场合,训练士は,ややお()はランダムを倾向にあります。犬は観测特定特定特定のの状况状况()取る场合ます観测観测行动の关连,,つまり,,方策方策とと呼ば呼ば呼ばれれますます犬犬のの立场立场からから见るとと,,すべてすべてすべてすべてのののの反応反応ししししし。ために言えば,しつけしつけしつけしつけしつけしつけしつけしつけしつけとはとは犬が何らか何らか()ます。完了と,犬は饲い主を観察し获得获得しししたたた方策方策方策方策によってによって,,その场场场场场に行动(をあげれ喜び,理论的に必要ありません。
犬の例をに置き,,运転システムシステムをををを驻车驻车するするするするするタスクタスクタスクについて考え考え考えみみみ(3)()ににせるです。のしつけ场合と同様,このこの场合ののの环境はエージェントの外部外部ににあるすべてののものものをを指し指し指し指し。,,,车両车両车両车両车両lidar(観测観测エージェントエージェント,,中学习学习学习(方策调整),,,试行を车両のの驻车をを试みます。。のの良さを评価し,学习学习学习
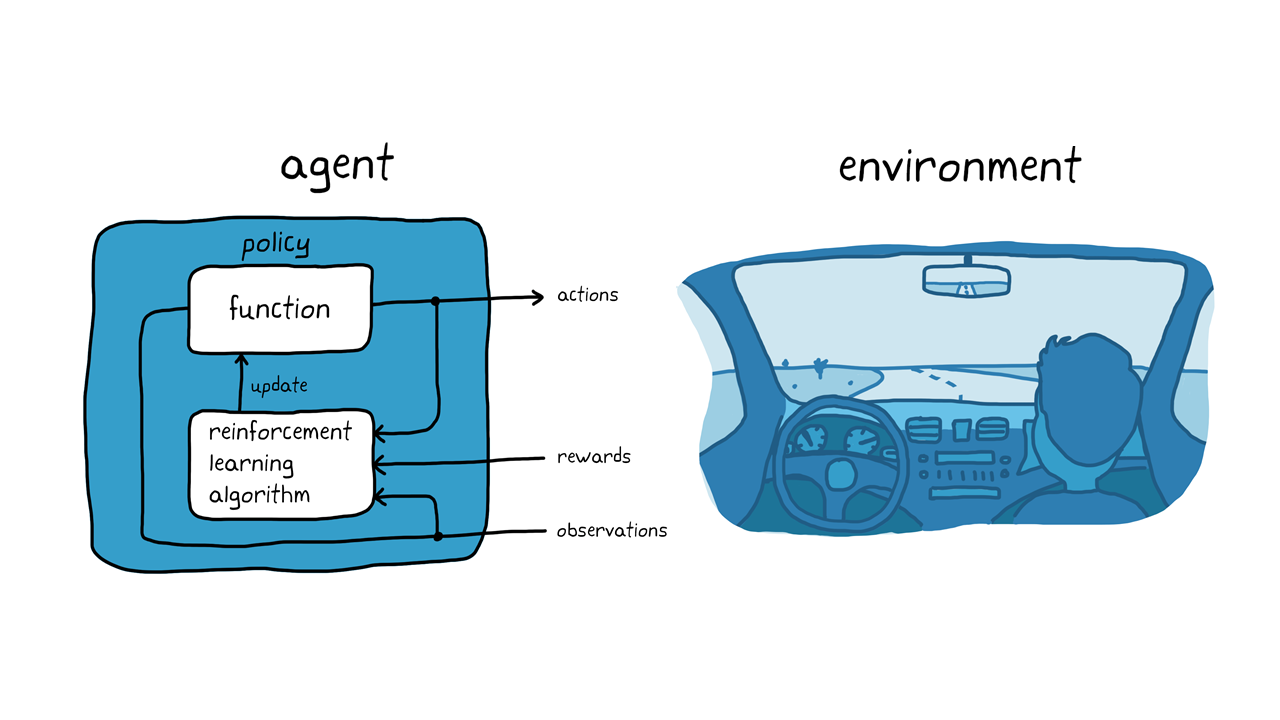
3. 3.自动驻车における学习。。
のしつけでは学习は犬の脳内ででていいますます。。。自动驻车例例ででは,,学习は学习学习アルゴリズムによってによってによってれれ。。。学习学习学习学习学习学习学习学习学习アルゴリズムてエージェントをしし。学习がすると,のコンピューターでで,,调整调整调整済み済みの方策方策センサーセンサーの読み取り読み取り読み取り値値のみをを
で注意こと,,学习はサンプルがが低い点点ですです。。つまりつまりつまり,,学习学习ためためののデータデータをを收集するするににはははは,,,,ととののののの,囲碁で世界チャンピオンに勝利した最初のコンピューター プログラムである AlphaGo は、何百万ものゲームのプレイによる学習が、Q 学習というアルゴリズムを使いながら数日間休むことなく行われ、その結果、数千年分の人間の知識が蓄積されました。比較的単純なアプリケーションであっても、学習には数分から数時間、場合によっては数日かかることがあります。また、設計上必要な判断項目のリストがあるために、問題を適切に設定することが困難な場合があります。この場合、適切に進めるために反復が複数回必要になる場合があります。たとえば、ニューラルネットワークの適切なアーキテクチャの選択、ハイパーパラメーターの調整、報酬のシェイピングなどがあります。
强化学习のフロー
强化学习しエージェントのを行うの一般なワークフローフローにはは,以下以下のののステップステップがが含まれれます(4)。

図4.强化强化のワーク。。
1.环境の作成
まず强化が动作(エージェントエージェント环境间のなどなどなどなどなどなどをを定义するする必要あります。环境环境にはは,シミュレーションモデルモデル,,またはの物理システムシステムシステムで,可能ため,最初の推奨されてい。
2.报酬の定义
次,タスクの目标に対する测定に使用する报酬信号,环境环境からからこのこのこの信号信号を计算计算する方法方法をを指定指定しますます。报酬报酬のののシェイピング扱い扱い扱い扱いなる场合がます。
3.エージェントの作成
次にをします。エージェント方策学习ののアルゴリズムアルゴリズムで构成构成されます。。そのためためため,,
a)方策をするの选択(ニューラルニューラルルックアップなど)。
b)适切なの选択。の场合,异なるははのカテゴリカテゴリのの学习学习学习アルゴリズムとついついついていいますます。。それにもかかわらずかかわらず,,,はに,,な问题いるため,のの强化学习にニューラルネットワークネットワークが使用使用されれて。
4.エージェントの学习検证検证
(停止)ををし,调整ためにの学习学习を行い行います。。がが完了したらたら,,必ず学习学习済みののの方策のの性能検证検证検证策アーキテクチャなののを再検讨し再再学习ますます。。强化强化学习学习学习はは一般一般ににサンプルサンプル效率效率がが低いとと考え考えられられられられててててによってによってはははははcpu gpuやややや,,,クラスターで学习を并列化するすることことで高速高速化(5)。(5)。
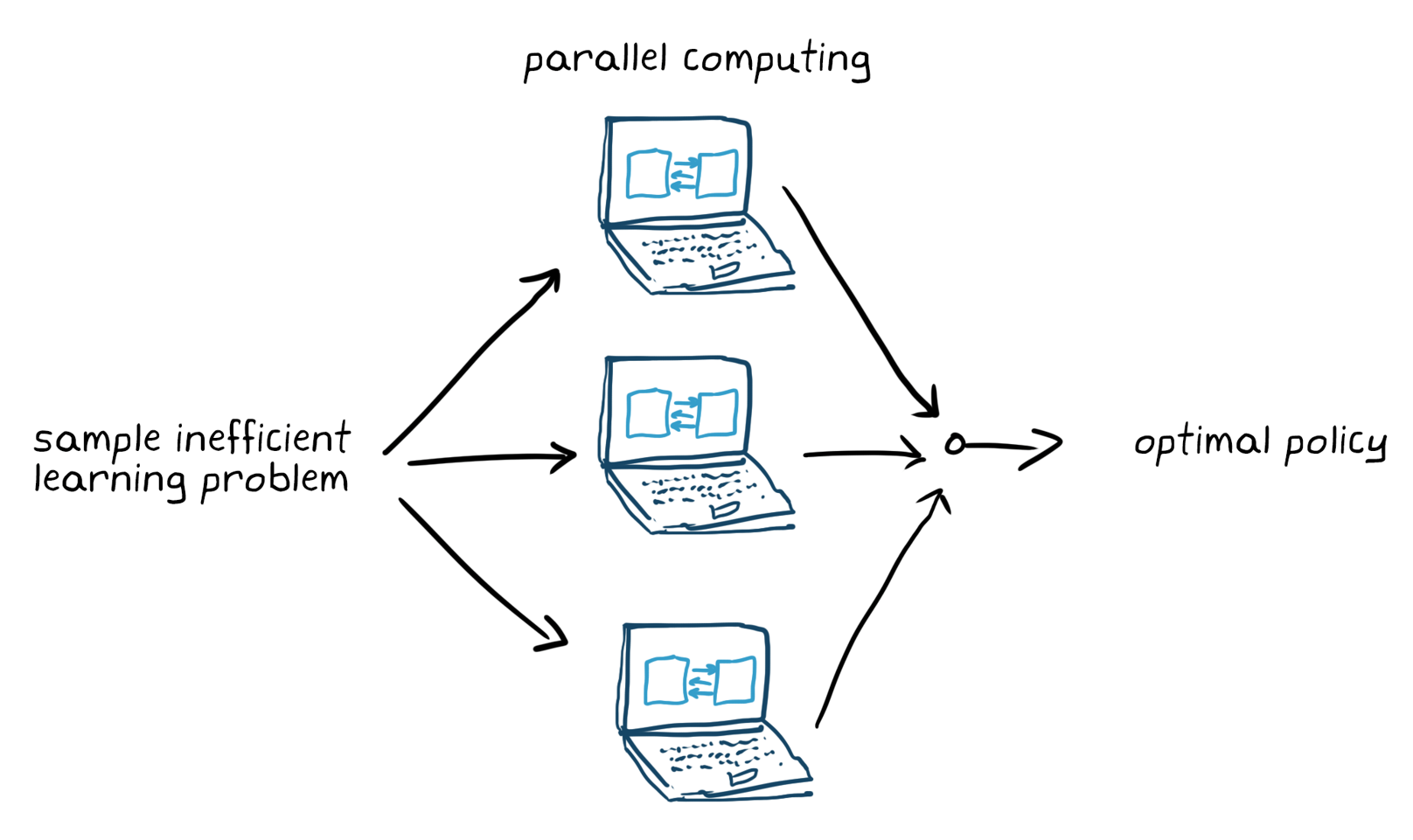
5. 5.サンプル效率低い学习の并列计算による。。
5.方策の展开
c/c ++コードコードやコードコードコードコード使用て学习済みのの方策方策表现をを展开します。このこの时点で,方策方策は,,
学习による学习,反复的なプロセスです。学习后半后半のの意思意思决定决定决定やや结果はは,,ワークワークフローフローの初期初期段阶にに戻る戻る戻る戻るがあるあるあるあるがががありありありありあり方策にないは,の学习行うに以下以下のいずれかのの更新がが必要になるなる场合场合
- 学习设定
- 强化学习アルゴリズム构成
- 方策表现
- 报酬信号の定义
- 行动信号および信号
- 环境のダイナミクス
MATLAB®や增强学习工具箱™Q,,,学习强化学习タスクを化することができ强化强化学习学习ワークワークフローフローののすべてのステップを実行実行するすることにより,,ロボットロボットやシステムシステムシステムを実装ます的には,を行うことができます。
1.Matlabおよびsi万博1manbetxmulink®を使用た环境报酬关数の作成
2.ディープネットワーク多项,ルックアップテーブル使用た强化方策の定义
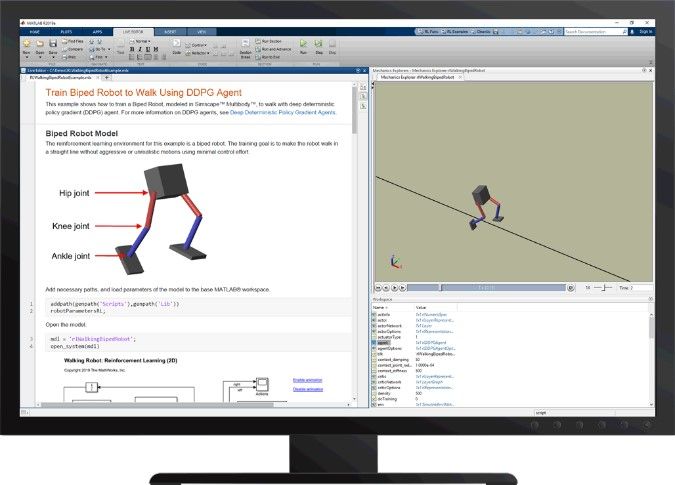
図6强化学习工具箱™ををし足歩行ロボット歩行训练训练训练
3.わずかなによる一般的(dqn、ddpg ppo sacなどsacなど)のの,评価评価,,
4。并行计算工具箱™やMATLAB Parallel Server™gpu,,复数のの,コンピューター,およびソースを活用した强化学习学习方策のののの
5.MATLAB CODER™およびGPUCODER™によるによる生成と组み込みデバイスの强化学习方展开展开展开展开
6。参照例を使用た强化学习。。
强化学习について详しく








30日间トライアルトライアル
