このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
データの探索的解析
この例では,記述統計を使用してデータの分布を調べる方法を示します。
標本データを生成します。
無作為に生成した標本データが含まれているベクトルを作成します。
rng默认的%的再现性x = [normrnd (4, 1100), normrnd (0.5, 1200);
ヒストグラムをプロットします。
標本データのヒストグラムを正規密度の近似とともにプロットします。このようにすると,データにあてはめた正規分布と標本データを視覚的に比較できます。
histfit (x)

データの分布は歪んでおり,左の裾が長くなっているように見えます。正規分布は,この標本データに適した近似ではないようです。
正規確率プロットを取得します。
正規確率プロットを取得します。このプロットは,データにあてはめた正規分布と標本データを視覚的に比較するための別の方法を提供します。
probplot (“正常”, x)
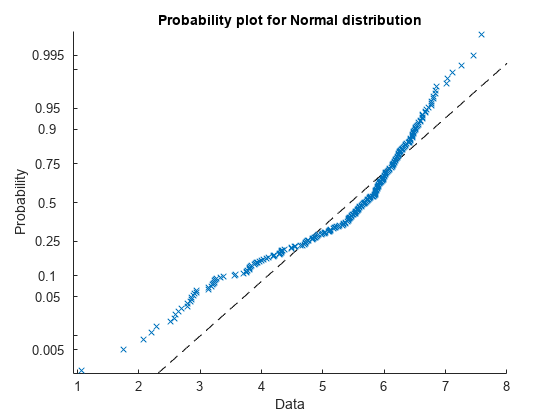
この確率プロットも,データが正規性から逸脱していることを示しています。
分位数を計算します。
標本データの分位数を計算します。
p = 0:0.25:1;y =分位数(x, p);z = [p; y]
z =2×50 0.2500 0.5000 0.7500 1.0000 1.0557 4.7375 5.6872 6.1526 7.5784
箱ひげ図を作成して統計量を可視化します。
箱线图(x)
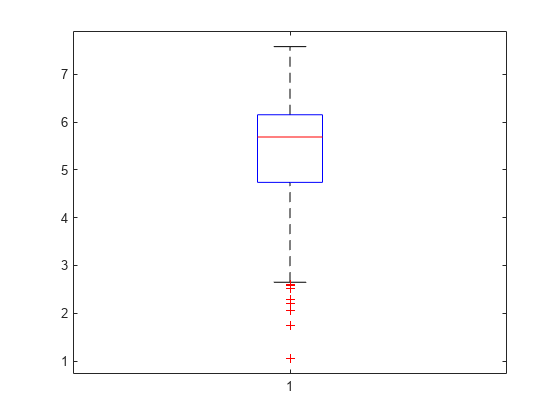
箱ひげ図には,0.25,0.5および0.75の分位数が示されます。長い下裾とプラス記号は,標本データの値に対称性が欠けていることを示しています。
記述統計を計算する。
データの平均値と中央値を計算します。
y = [(x),中等(x))
y =1×25.3438 - 5.6872
平均値と中央値は近いように見えますが,平均値が中央値より小さい場合,通常はデータが歪んでいて左の裾が長くなっています。
データの歪度と尖度を計算します。
y =[偏斜度(x),峰度(x))
y =1×2-1.0417 - 3.5895
歪度の値が負の場合,データは左に歪んでいることを意味します。尖度の値が3より大きいため,データの尖度は正規分布より大きくなります。
zスコアを計算します。
zスコアを計算し3より大きいか3より小さい値を探すことにより,外れ値の可能性がある値を識別します。
Z = zscore (x);找到(abs (Z) > 3);
zスコアに基づくと,3番目の観測値と35番目の観測値は外れ値の可能性があります。
参考
箱线图|histfit|峰度|的意思是|中位数|prctile|分位数|偏态
関連するトピック
你也可以从以下列表中选择一个网站:
