このページの翻訳は最新ではありません。ここをクリックして,英語の最新版を参照してください。
石灰
本地可解释模型不可知解释(LIME)
説明
石灰は、重要な予測子を見つけて解釈可能な単純モデルをあてはめることにより、クエリ点に対する機械学習モデル (分類または回帰) の予測を説明します。
クエリ点(查询点)と重要な予測子の数(重要预测因子) を指定して、機械学習モデル用の石灰オブジェクトを作成できます。ソフトウェアは合成データセットを生成し,クエリ点周辺の合成データに対する予測を効果的に説明する重要な予測子の解釈可能な単純モデルをあてはめます。単純モデルにできるのは,線形モデル(既定)または決定木モデルです。
あてはめられた単純モデルを使用して、指定したクエリ点での機械学習モデルの予測を局所的に説明します。関数情节を使用して、石灰の結果を可視化します。局所的な説明に基づいて,機械学習モデルを信頼するかどうかを判断できます。
別のクエリ点には、関数适合を使用して、新しい単純モデルをあてはめます。
作成
構文
説明
入力引数
プロパティ
例
単純な決定木モデルを使った予測の説明
分類モデルの学習を行い、単純な決定木モデルを使用する石灰オブジェクトを作成します。石灰オブジェクトを作成するときに、クエリ点と重要な予測子の数を指定して、ソフトウェアが合成データ セットの標本を生成し、重要な予測子を使って単純モデルをクエリ点にあてはめるようにします。次に、オブジェクト関数情节を使用して、予測子の推定重要度を単純モデルに表示します。
信用评级データセットを読み込みます。データセットには,顧客ID,顧客の財務比率,業種ラベル,および信用格付けが格納されています。
tbl=可读(“CreditRating_Historical.dat”);
テーブルの最初の 3.行を表示します。
头部(待定,3)
ans=3×8表这是一个两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两两}424440.3110.3670.0741.9350.3661{'A'}
tblから顧客IDと信用格付けの列を削除して,予測子変数の表を作成します。
tblX = removevars(资源描述,“ID”,“评级”]);
関数fitcecocを使用して,信用格付けの黑箱モデルに学習させます。
黑盒=fitcecoc(tblX,tbl.额定值,“CategoricalPredictors”,“工业”);
単純な決定木モデルを使用して最後の観測値の予測を説明する石灰オブジェクトを作成します。最大 6.つの重要な予測子を見つけるため、“NumImportantPredictors”を 6.に指定します。石灰オブジェクトを作成するときに“QueryPoint”と“NumImportantPredictors”の値を指定した場合、ソフトウェアは合成データ セットの標本を生成し、解釈可能な単純モデルを合成データ セットにあてはめます。
queryPoint=tblX(结束:)
查询点=1×6表企业所得税息税前利润(MVE)为行业所得税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税行业所得税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税息税
rng(“默认”)%为了再现性结果=石灰(黑盒,“QueryPoint”,查询点,“NumImportantPredictors”6....“SimpleModelType”,“树”)
结果=带属性的lime:BlackboxModel:[1x1 ClassificationCoC]数据位置:'global'分类预测因子:6类型:'classification'X:[3932x6表]查询点:[1x6表]NUM重要预测因子:6 NUM合成数据:5000合成数据:[5000x6表]拟合:{5000x1单元格}简单模型:[1x1 ClassificationTree]重要预测因子:[2x1 double]BlackboxFitted:{'AA'}SimpleModelFitted:{'AA'}
オブジェクト関数情节を使用して,石灰オブジェクト结果をプロットします。予測子名に含まれるアンダースコアを表示するには、座標軸のTickLabelInterpreter値を“没有”に変更します。
f=绘图(结果);f.CurrentAxis.TickLabelInterpreter=“没有”;
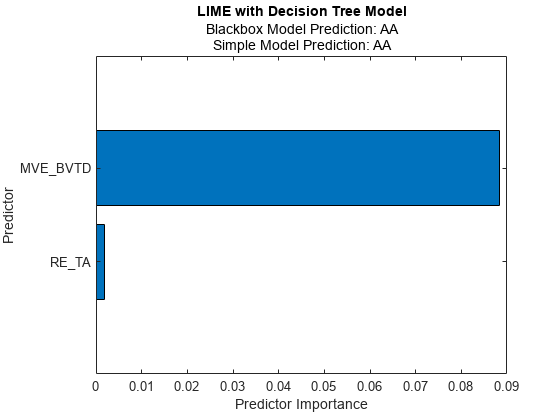
プロットには、クエリ点についての 2.つの予測値が示されています。この予測値は、结果の黑匣子プロパティと简单模型プロパティに対応します。
横棒グラフは,予測子の重要度の並べ替えられた値を示しています。石灰はクエリ点の重要な予測子として財務比率変数息税前利润および沃库塔を求めます。
バーの長さは,データヒントまたは酒吧のプロパティを使用して読み取ることができます。たとえば,関数芬多布吉を使用して酒吧オブジェクトを検索し、関数文本を使用して、バーの端にラベルを追加できます。
b = findobj (f,“类型”,“酒吧”);文本(b.YEndPoints + 0.001, b.XEndPoints字符串(b.YData))
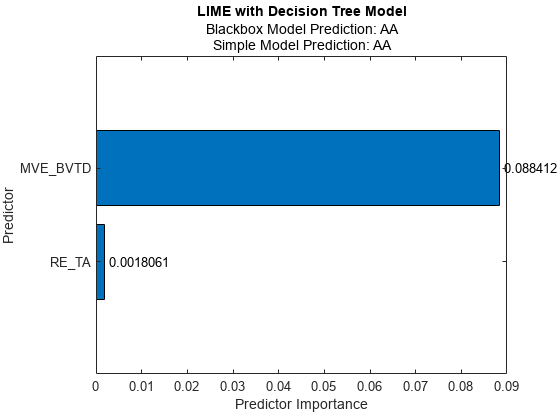
あるいは,予測子変数名をもつ表に係数値を表示することもできます。
imp=b.YData;flipud(数组2)table(imp',,...“RowNames”,f.currentAxis.YTickLabel,“VariableNames”,{“预测重要性”}))
ans=2×1表预测器重要性0.088412 RE_TA 0.0018061
線形単純モデルを使用した予測の説明
回帰モデルの学習を行い,線形単純モデルを使用する石灰オブジェクトを作成します。石灰オブジェクトを作成するときに,クエリ点と重要な予測子の数を指定しなかった場合,ソフトウェアは合成データセットの標本を生成しますが,単純モデルのあてはめは行いません。オブジェクト関数适合を使用して、クエリ点に単純モデルをあてはめます。次に、オブジェクト関数情节を使用して,あてはめた線形単純モデルの係数を表示します。
carbigデータセットを読み込みます。このデータセットには,1970年代と1980年代初期に製造された自動車の測定値が格納されています。
负载carbig
加速度、气缸などの予測子変数と応答変数英里/加仑が格納された 桌子を作成します。
台=表(加速度、汽缸、排量、马力、Model_Year重量,MPG);
学習セットの欠損値を削除すると、メモリ消費量を減らして関数菲特克内尔の学習速度を向上させることができます。tblの欠損値を削除します。
tbl=RML缺失(tbl);
tblから応答変数を削除して、予測子変数のテーブルを作成します。
tblX=移除变量(tbl,“英里”);
関数菲特克内尔を使用して英里/加仑の 黑匣子モデルの学習を行います。
rng(“默认”)%为了再现性mdl=fitrkernel(tblX,tbl.MPG,“CategoricalPredictors”[2 - 5]);
石灰オブジェクトを作成します。mdlには予測子データが含まれないため,予測子データセットを指定します。
结果=石灰(mdl tblX)
结果=石灰与属性:BlackboxModel: [1 x1 RegressionKernel] DataLocality:“全球”CategoricalPredictors:[2 5]类型:“回归”X: [392 x6表]QueryPoint: [] NumImportantPredictors: [] NumSyntheticData: 5000 SyntheticData: [5000 x6表)安装:x1双[5000]SimpleModel: [] ImportantPredictors: [] BlackboxFitted:[] SimpleModelFitted: []
结果には、生成された合成データ セットが含まれます。简单模型プロパティは空 ([]) です。
tblXの最初の観測値に線形単純モデルをあてはめます。検出する重要な予測子の数を 3.に指定します。
: queryPoint = tblX (1)
查询点=1×6表加速气缸位移马力Model_Year重量 ____________ _________ ____________ __________ __________ ______ 12 8 307 130 70 3504
结果=适合(结果,queryPoint, 3);
オブジェクト関数情节を使用して,石灰オブジェクト结果をプロットします。予測子名に含まれるアンダースコアを表示するには、座標軸のTickLabelInterpreter値を“没有”に変更します。
f=绘图(结果);f.CurrentAxis.TickLabelInterpreter=“没有”;
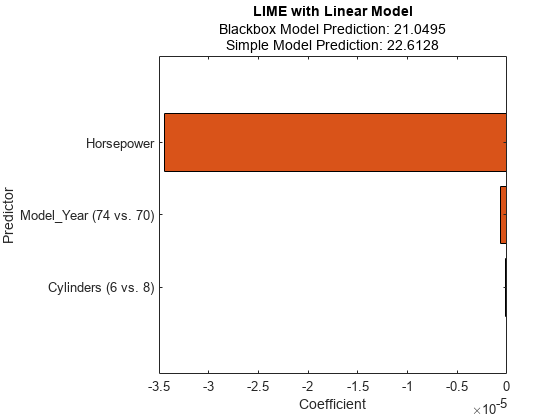
プロットには、クエリ点についての 2.つの予測値が示されています。この予測値は、结果の黑匣子プロパティと简单模型プロパティに対応します。
横棒グラフは、絶対値で並べ替えられた、単純モデルの係数値を示します。石灰は、クエリ点の重要な予測子として、马力、车型年款、および气缸を見つけます。
车型年款および气缸は複数のカテゴリをもつカテゴリカル予測子です。線形単純モデルの場合,各カテゴリカル予測子について,カテゴリの数よりも1つ少ないダミー変数が作成されます。棒グラフには最も重要なダミー変数のみが表示されます。他のダミー変数の係数は结果の简单模型プロパティを使用して確認できます。すべてのカテゴリカル ダミー変数を含む並べ替えられた係数の値を表示します。
[~,I]=sort(abs(results.SimpleModel.Beta),“下”);表(results.SimpleModel.expandedPredictor名称(I)”,results.SimpleModel.Beta(I),...“VariableNames”,{'扩展预测程序名称',“系数”})
ans=17×2表Exteded预测名字系数 __________________________ ___________ {' -3.4485马力的}e-05 {Model_Year(74和70)的}-6.1279 e-07{“Model_Year(80和70)的}-4.015 e-07{“Model_Year(81和70)的}3.4176 e-07{“Model_Year(82和70)的}-2.2483 e-07{的圆柱体(6和8)}-1.9024 e-07{“Model_Year(76和70)的}1.8136 e-07{圆柱体(5 vs。8)'} 1.746e -07 {'Model_Year (75 vs. 70)'} 1.5456e-07 {'Model_Year (77 vs. 70)'} 1.4272e-07 {'Model_Year (78 vs. 70)'} 6.7001e-08 {'Model_Year (72 vs. 70)'} 4.7214e-08 {' cylinder (4 vs. 8)'} 4.518e -08 {'Model_Year (79 vs. 70)'} -2.2598e-08⋮
黑匣子モデルを関数ハンドルとして指定
回帰モデルの学習を行い、モデルの関数预测の関数ハンドルを使用する石灰オブジェクトを作成します。オブジェクト関数适合を使用して,指定したクエリ点に単純モデルをあてはめます。次に,オブジェクト関数情节を使用して,あてはめた線形単純モデルの係数を表示します。
carbigデータセットを読み込みます。このデータセットには,1970年代と1980年代初期に製造された自動車の測定値が格納されています。
负载carbig
予測子変数加速度、气缸などを格納する 桌子を作成します。
tbl=表(加速度、气缸、排量、马力、车型年份、重量);
関数树人を使用して英里/加仑の 黑匣子モデルの学習を行います。
rng(“默认”)%为了再现性Mdl=TreeBagger(100,tbl,MPG,“方法”,“回归”,“CategoricalPredictors”[2 - 5]);
石灰は树人オブジェクトを直接はサポートしないため,石灰の最初の入力引数(黑箱モデル)を树人オブジェクトとして指定することはできません。代わりに、関数预测の関数ハンドルを使用できます。関数预测のオプションも関数の名前と値の引数を使用して指定できます。
树人オブジェクトMdlの関数预测の関数ハンドルを作成します。使用する木のインデックスの配列を1:50と指定します。
myPredict = @(tbl) predict(Mdl,tbl,)“树”,1:50);
関数ハンドル我的预测を使用して石灰オブジェクトを作成します。黑箱モデルを関数ハンドルとして指定する場合、予測子データを提供し、名前と値の引数“类型”を指定しなければなりません。tblには、双重的データ型のカテゴリカル予測子(圆柱および车型年款)が含まれています。既定では,石灰は双重的データ型の変数をカテゴリカル予測子として扱いません。2.番目 (圆柱) と 5.番目 (车型年款)の変数をカテゴリカル予測子として指定します。
结果=石灰(myPredict,tbl,“类型”,“回归”,“CategoricalPredictors”[2 - 5]);
tblの最初の観測値に線形単純モデルをあてはめます。予測子名に含まれるアンダースコアを表示するには、座標軸のTickLabelInterpreter値を“没有”に変更します。
结果=适合(结果,台(1:),4);f=绘图(结果);f.CurrentAxis.TickLabelInterpreter=“没有”;
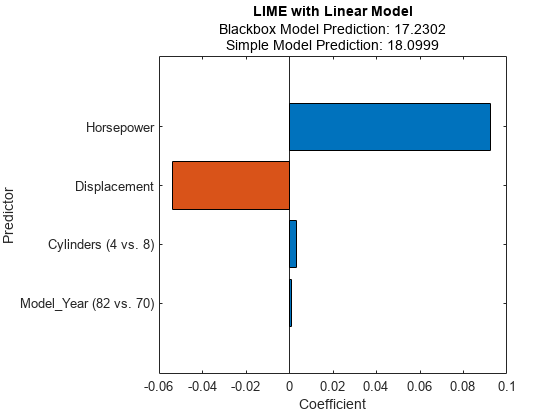
石灰は、重要な予測子として马力、取代、气缸、および车型年款を見つけます。
詳細
アルゴリズム
参照
你也可以从以下列表中选择一个网站:
