之前的视频是关于正定矩阵的。这个视频也是线性代数,一种很有趣的分解矩阵的方法叫做奇异值分解。每个人都说SVD表示奇异值分解。这个因式分解是什么?SVD的三个部分是什么?
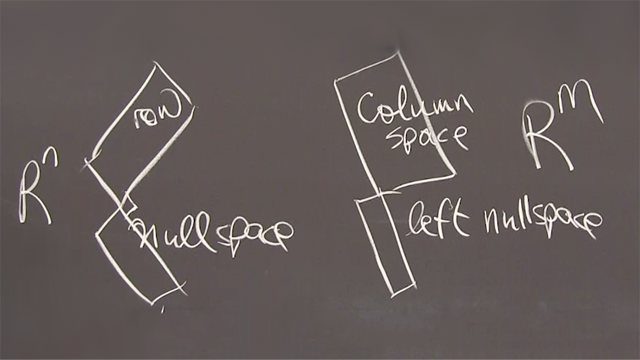
这就是每个矩阵,矩形,每个矩阵都可以分解成——这是三部分。U V转置。人们用这些字母来表示三个因素。
因子U是一个正交矩阵,正交矩阵。中间的因子是一个对角线矩阵。右边的因子V转置也是一个正交矩阵。正交,对角线,正交,或者物理上,旋转,拉伸,旋转。现在我们已经看到了一个矩阵的三个因子,V V逆。有什么不同?这个SVD和V, V转置V逆,V, V逆对角化其他矩阵的区别是什么?
是对角线的,也是对角线的,但它们是不同的。关键是我现在有两个不同的矩阵,不仅仅是V和V逆,而是两个不同的矩阵。但是新的优点是它们都是正交矩阵。所以通过——我也可以对矩形矩阵这样做。特征值确实适用于方阵。
现在我们有两个了。我们有一个输入矩阵和一个输出矩阵。在这些空间中,m和n可以有不同的维度。通过允许两个不同的基底,我们得到矩形矩阵,我们得到正交因子,同样是一条对角线。这叫做,这些数字sigma而不是特征值,叫做奇异值。这些是奇异值。这些是奇异向量,右边的奇异向量和左边的奇异向量。这就是因式分解的表述。
但我们必须思考一下,这些因素是什么?我们能明白为什么会这样吗?我想要这个。让我来做,当你看到这个的时候,我来看看A的转置A,我喜欢A的转置A,所以A的转置就是,我转置这个。V转置U转置,对吧?这是A '然后乘以A U V转置。我得到了什么?我有六个矩阵。
但是U转置U在这里是恒等矩阵,因为U是一个正交矩阵。所以我在一边只有V, a的转置,这是对角线,右边是V的转置。这一点我承认。这一点我承认。这是一个V,一个对角矩阵,一个V转置。我在这里给你们看的是,我们得到的是特征值,对角线化,通常的特征值在这里特征向量在这里。但是矩阵是A ' A。
同样,A是矩形的,完全一般,我们不能得到完美的结果。但是当我们求A ' A时,它给出了一个正的半定矩阵,它是对称的。它的特征向量是正交的。这就是我如何知道这个V矩阵,这个对称矩阵的特征向量,是正交的特征值是正的。它们是奇异值的平方。这就告诉我们A ' A的等于s的平方,对于A本身。也是一样的。A ' A等于矩阵A的平方。
它告诉我们V,告诉我们,U在这里消失了因为U转置U是单位矩阵。它就这样消失了。我怎样才能找到你?好吧,这是一种看待它的方式。我用A乘以A的转置按这个顺序,按这个顺序。现在我有U V转置乘以转置,也就是V转置U转置,我在这里对转置有很多乐趣。
但是V转置V现在是中间的单位矩阵。从这里我能学到什么?我知道U是AA转置的特征向量矩阵。所以这些有相同的特征值,A乘以B和B乘以A有相同的特征值在这种情况下,它出来了。相同的特征值。这个有特征向量V,这个有特征向量U,这些是奇异值分解中的V和U。
我要给你们看一个例子我要给你们看一个例子和一个应用,就是这样。举个例子。假设A,我把它写成一个方阵,2,2 - 1,1,不对称。当然不是肯定的。我不会用这个词,因为这个矩阵不是对称的。但它有一个SVD,有三个因子。
我算出来了。这是正交矩阵。我要除以√5得到单位向量。哦,这行不通。怎么样?这两列是正交的,这是一个完美的u,然后在∑中,我得到,哦,我想要的是1和1。我确实想要1和1。所以我有一个奇异矩阵,行列式为0,奇异矩阵。所以我的特征值是0而根号10是它的另一个特征值——这个向量的另一个奇异值。
现在我代入V转置矩阵,它是1,1,1,是- 1吗?长度是根号2,要除以根号2。我做得不是很顺利,但结果很明显。U V转置,这就是。这个矩阵的奇异值是根号10,然后是0因为它是一个奇异矩阵。特征向量,矩阵的奇异向量是左边的奇异向量和右边的奇异向量。我觉得不错。
现在要完成申请。第一个应用非常重要。本世纪以来,我们一直在得到包含数据的矩阵。也许在生命科学领域,我们会测试一群人的基因样本。我有一个数据,我有一个基因表达矩阵。我有样本,人,人1 2 3在这些列里。在这些行中,假设有四行,我有基因,基因表达。
这是完全正常的。一个矩形矩阵,因为人数和基因的数量是不一样的。实际上,这两个都是非常非常大的数,所以我有一个很大的矩阵。从中,我想——矩阵中的每个数字都告诉我这个人表达了多少基因。我们可能在寻找导致某些疾病的基因。所以我们找了几个人,一些患有这种疾病的人,我们检查基因。我们得到了一个大矩阵,我们想要了解其中的一些东西。
我们能理解什么?我们在找什么?我们在寻找某种基因组合之间的相关性和联系,我们在寻找一种基因人与人之间的联系。但不是第一个人。我们不是在找一个人。我们会找到这些人的混合物,所以我们会有一个特征样本,特征人。哦,这太糟糕了,特征人会更好。所以我觉得我看到的是一个特征人。让我看看我该把它放在哪里。
所以,我认为我的矩阵可以写成,哦,这是重点。就像我在这个例子中看到的,第一个向量第一个向量和最大的都很重要。在这个例子中,另一个是0,什么都没有。但在这个例子中,我可能有三个不同的。但最大的,第一个,U1和V1,就是我想要的组合。我想要U1 (1v1)转置,A转置A和AA转置的第一个特征向量。
第一个奇异值,最大的奇异值,就是信息。这是最好的组合人,特征人,这些人的组合和基因的最佳组合。在统计学上,方差是最大的。在普通英语中,我会说最多的信息。这个大矩阵中的大部分信息都在这个非常特殊的矩阵中它只有秩一,只有一列重复。一行重复,一个数字sigma 1,这个数字告诉我们。因为记住,U是单位向量。V是单位向量。是sigma 1卖给我的。
就像这个单位向量乘以那个键数,乘以那个单位向量,就是这个。我说的是主成分分析。我在找主分量,这部分。主成分分析。应用统计学中的一个重大应用。要知道,在大规模的药物测试中,统计学家在这里确实占有中心地位。这是研究方面,从大样本中获取信息。
U1是人的组合。V1是基因的组合。1是我能得到的最大的数。这就是主成分分析,都来自于奇异值分解。谢谢你!