在本视频中,我们将介绍主动悬挂系统的控制器设计。实际上,我们要设计两个控制器。对于第一个,我们将使用H∞合成为一个标称植物模型设计一个控制器,该控制器将保证性能,但不一定对系统的变化具有鲁棒性。然后我们建立一个不确定模型就像我们在上个视频中做的那样然后用合成设计一个鲁棒控制器。我觉得会很有趣的,所以我希望你们能留下来看。我是Brian,欢迎来到MATLAB技术讲座。
当汽车遇到路面颠簸时,轮胎会吸收一些冲击,并稍微压缩,然后将整个车轮组合起来。这个力通过悬架传递,导致车身反弹。对于悬挂系统,我们通常感兴趣的是车辆的性能,以及当它遇到颠簸时乘坐的舒适性。
在主动悬架系统中,除了被动弹簧和阻尼机构外,还有一个液压执行器,可以向系统注入力量,以微调我们想要的性能和舒适性。
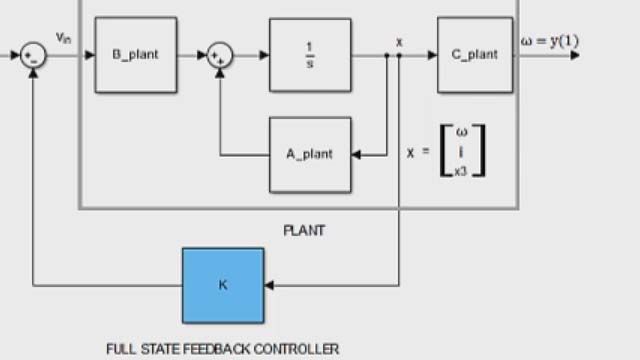
我们可以用下面的模型来近似这个系统。我们将轮胎的弯曲视为弹簧,轮胎组件作为一个质量,通过弹簧/阻尼器系统连接到车身质量,代表被动悬挂组件,并将液压执行器作为输入力。
有了这个简化的工厂模型,我们可以设计一个反馈控制器K,它将接受一些测量值,我们称之为v,并产生受控变量u。对于我们的系统,我们有一个受控变量,即所要求的液压力,我们将使用两个测量值:车身加速度ab和悬挂行程sd。悬架行程是如何压缩或扩大悬架。这就是我们的反馈控制问题。现在,让我们来看看如何设计这个控制器。就像我说的,我们从H∞合成开始。
为了从概念上理解H∞和最终的合成,我们需要展开这个方框图。除了控制器输入,我们还有外部输入到这个系统中,这些输入来自干扰、噪声,甚至是参考信号。我们称它们为w。
我们还需要考虑其他的产出。这些是错误信号,让我们了解系统的运行情况。这些输出可以是在实际系统中测量的信号,也可以是虚拟的,在某种意义上,我们只是在模型中暂时使用它们来设计控制器,而在实际系统中不需要它们。我们称这些误差信号为z。
假设我们的植物只有一个我们关心的外部输入;当我们在路上遇到颠簸时产生的干扰。我们想用三个误差信号来定义性能:车身加速度,悬挂行程,以及要求的致动器力。
简单来说,这就是整个设计问题。我们想要一种控制器,当扰动进入系统时,使误差信号最小化。我们可以这样想:当汽车遇到颠簸时,就会产生干扰,这种干扰通过轮胎、弹簧和减震器以某种方式被放大,使汽车上下移动,拉伸和压缩悬挂系统。控制器可以通过驱动执行器来修改这种扰动对这些信号的影响。目标是驱动驱动器,使扰动的放大最小化,并在该过程中使用尽可能少的驱动器力。
这就是H∞合成的作用。这是一个优化过程,计算控制器使w和z之间的增益最小化。
然而,作为设计师,您可能不希望在这个优化问题中对每个信号一视同仁。因此,我们可以通过在w和z上添加加权因子来控制模型中的信号,以设置单个信号的重要性。例如,如果我们不像关注物体加速度那样关注执行器能量,我们可以降低执行器权重因子。或者我们可以增加重量如果我们想减少驱动器的驱动因为我们更关心延长它的寿命。我们可能会开发多个控制器,每个控制器都有不同的重量,然后允许用户在不同的主动悬挂模式之间切换,比如性能、舒适性或两者之间的平衡。
好了,现在我们已经知道如何处理这个问题了,要建立和解决这个问题你可以看到我们有一些设计选择。我们需要创建一个工厂的模型,我们需要确定控制器可以访问哪些测量信号以及它可以控制哪些输入变量,我们需要选择外部输入和误差信号,然后最后我们必须通过对每个信号进行加权来建立代价函数。一旦我们有了这些,我们就可以用h_∞合成来解决一个大的优化问题。从数学上讲,这可能有点棘手,但这个视频的重点不是让你手工做这个。这是为了让你了解控制器是如何工作的,这样你就可以自己解决问题,让工具帮你解决数学问题。
让我们用MATLAB来做这个。
在大多数情况下,该脚本与MathWorks示例“主动悬挂的鲁棒控制”一起使用,但为了这个视频,我对它进行了一些修改。如果您想深入了解如何设置所有这些并自己进行练习,我建议您自己查看原始示例。这看起来像是一大堆令人困惑的代码,但我保证这个脚本的要点与我们刚刚走过的完全相同。
我们首先建立一个工厂模型,这是四分之一赛车悬架的弹簧/质量/阻尼器表示。现在,我们假设这个模型是完美的,动力学中没有不确定性。我们一会儿再回到这个假设。
这里需要注意的另一件事是,我们将液压作动器建模为一级系统。这意味着控制器要求一个力u,但执行器产生的实际力fs取决于它的动力学。
为了继续设计设置的其余部分,我们为每个外部输入和错误信号设置单独的加权函数。比如,W路的增益是0.07。但真正酷的是。加权函数可以是频率相关的。在这种情况下,我们在执行器信号上加了一个高通滤波器。这将对高频控制器命令的惩罚大于低频,因此为我们提供了一种限制控制带宽的方法。
这里还需要注意的是,我们为身体加速度和悬挂旅行设置了三组不同的重量。这就是我们如何区分性能模式、舒适模式和平衡模式;接下来,我们要求解三个不同的控制器,每个增益集对应一个。
现在,我们将这些块连接起来,创建一个单独的开环模型。该模型包括悬架动力学、作动器动力学和加权函数。这个开环函数叫做qcaric。
好了,有了设计问题,我们可以用h∞合成命令来构建控制器。这很简单。这是一个单独的命令,我们将开环函数传递给它,并告诉它控制器可以访问哪些信号。但请记住,幕后发生的事情是通过找到控制器K来解决一个优化问题,使从外部输入到误差信号的能量转移最小化。实际上,它做了三次,每个增益集一次。
所以,我们剩下的是一个控制器,它接收两个测量信号,悬架行程和车身加速度,并输出执行器命令u。让我们通过模拟对5厘米路面碰撞的响应来看看这些控制器的动作。我用H∞控制器构建了闭环系统,在这里我对四种不同的配置进行了1秒的模拟:不受控系统,以及舒适性、平衡性和性能配置。看看这个。
绿线是5厘米的路面凹凸,蓝线是开环响应。这就是系统的表现如果我们只有被动悬挂组件的话。但是有了闭环控制器,我们就有了舒适的轮廓,凹凸不平的地方被很好地阻尼掉了,就像你漂浮在云端一样,我们有了性能轮廓,可以很快地阻尼掉,你可以真正地感受到道路。平衡在两者之间。
这一切都很好,除了这些控制器是用一个不完美的模型设计的。我们知道悬架系统比简单的弹簧/质量/阻尼系统要复杂得多;还有四个轮子相互作用,传感器中有噪音,执行器动态可能会变化等等。在这个系列中,我们一直在问自己这个系统是如何处理变化的?
我们来看看不确定致动器的效果。这里,我用一些频率相关的不确定性来改变标称作动器动态。然后,我将用这个不确定执行器重建开环模型。所以,一切都和以前一样,现在我们的工厂是用不确定性建模的。
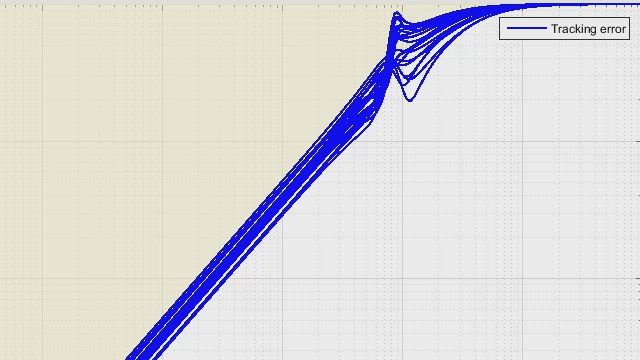
让我们通过模拟100个随机致动器变量的5厘米路面颠簸来看看标称H∞控制器的表现如何。为了简单起见,我们只考虑平衡控制器。来看看。大多数执行器组合似乎是稳定的,并产生合理的响应。然而,有些变化会产生不稳定的反应。所以,H∞控制器不是一个很好的解决方案如果执行器的动态变化像我建模的那样大。
那么,我们该如何改进呢?好吧,我们可以回到过去,调整不同信号的权重,并尝试提出一个在这些变化中稳定的控制器,但如果我们已经有了不确定系统的模型,为什么我们不开发一个从一开始就考虑这些不确定因素的控制器呢?这就是合成的作用。
综合是h∞的延伸,它仍然在解决同样的问题,只是它试图最小化整个不确定空间的最坏情况增益。
它的方法是一个叫做D-K迭代的迭代过程。这个过程的数学细节在这个视频中并不重要,但本质上它在每一步中所做的是运行H∞合成来找到一个标称控制器并检查它的鲁棒性。然后,它根据系统中的不确定性对问题进行缩放,并运行另一个H∞综合,检查其鲁棒性,然后再次缩放。它一直这样做,直到健壮性能停止改进。
鲁棒性能为Peak Mu值,一般情况下,这个值越低,系统的鲁棒性越好。您可以看到,Peak Mu在每次迭代中都在减小,并且它是报告为获得的最佳健壮性能的最终值。
因此,通过这种方式,我们知道不管最坏情况下不确定性的组合是什么,它至少会有这个水平的稳健性。就像H∞一样,我们可以用一个命令运行mu synthesis,我们将开环函数传递给它,并告诉它控制器可以访问哪些信号。它是完全一样的,只是在底层使用了不同的优化。这里,我只运行平衡增益集,集合2。
让我们来看看平衡H∞控制器和类似的合成控制器之间的区别。这和我之前展示的响应是一样的,除了现在我们可以看到合成控制器如何产生一个由于不确定性而变化较少的响应。车身位置和悬挂行程都非常一致,重要的是,稳定。乍一看,车身加速度似乎更差,但如果我们仔细观察,这里的大部分变化也更一致,这些剧烈的加速度波动只与偏离标称执行器最大的变化相关。因此,如果你在悬挂系统上安装了一个接近变幅极限的致动器,系统仍将保持稳定,但代价是行驶过程略显粗糙。也许最后是一笔不错的交易。
所以,希望你们能看到思考系统中哪里存在不确定性的价值,对不确定性建模,然后用不确定性模型来开发一个鲁棒控制器。我绝对认为自己尝试着去实践这一方法是值得的,因为它将允许你去调整一些数值并看看这将如何影响最终的控制器设计。做到这一点的一种方法是查看描述中的MathWorks示例。
这节课就讲到这里。
如果你不想错过未来的任何Tech Talk视频,不要忘记订阅这个频道。如果你想看看我的频道,控制系统讲座,我也会介绍更多的控制理论主题。感谢收看,我们下期见。