 克里夫角:克里夫·摩尔论数学与计算
克里夫角:克里夫·摩尔论数学与计算 罗兰关于MATLAB的艺术
罗兰关于MATLAB的艺术 用MATLAB进行图像处理
用MATLAB进行图像处理 Simulin万博1manbetxk上的家伙
Simulin万博1manbetxk上的家伙 深度学习
深度学习 开发区
开发区 斯图尔特的MATLAB视频
斯图尔特的MATLAB视频 在标题后面
在标题后面 本周文件交换精选
本周文件交换精选 物联网上的汉斯
物联网上的汉斯 学生休息室
学生休息室 创业公司、加速器和企业家
创业公司、加速器和企业家 MATLAB社区
MATLAB社区 MATLABユーザーコミュニティー
MATLABユーザーコミュニティー新型冠状病毒COVID-19数据集分析
随着新型冠状病毒新冠-19的威胁在全世界传播,我们生活在一个日益焦虑的时代。当医护人员在前线抗击病毒时,我们通过练习社会距离来减缓流行病的蔓延。今天的客座博主,古原竹内,想分享一下他是如何在MATLAB中分析数据的。
声明:本文不是COVID-19的有效和可信信息来源,COVID-19是一种严重威胁,您应咨询权威来源,以获得准确信息,如世卫组织或美国疾病控制与预防中心。
目录
新冠病毒-19数据源
当我们日复一日地听到新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠病毒新冠。
我查看了文件交换,发现Kevin Chng就新冠病毒-19进行了文件交换.我还发现新型冠状病毒2019数据集Kaggle。我决定使用Kaggle的数据集。
我从Kaggle下载了zip文件,并将其内容移动到我当前的工作目录。
让我们检查解压缩的文件。请注意“| 2019_nCoV_data.csv |”已过时,我们不应该使用它。
s=dir(“* . csv”); s=s(arrayfun(@(x)~匹配(x.name),“2019 _ncov_data.csv”),s));filenames=arrayfun(@(x)字符串(x.name),s)
filenames=6×1字符串数组“COVID19_line_list_data.csv”“COVID19_open_line_list.csv”“covid_19_data.csv”“time_series_covid_19_confirated.csv”“time_series_covid_19_death.csv”“time_series_covid_19_recovered.csv”
- 新冠病毒19_data.csv-这是2020年1月22日起按省/州分类的全球病例主要每日档案水平数据
- time_series_covid_19_confirmed.csv-确诊病例的时间序列数据
- 时间序列新冠病毒19死亡.csv-累积死亡人数的时间序列数据
- 时间序列新冠病毒19已恢复.csv-累计恢复病例数的时间序列数据
- COVID19_line_list_data.csv-个人级别信息
- COVID19_open_line_list.csv-个人级别信息
全球确定确诊病例
让我们在地图上可视化确诊病例的数量。我们从装载开始time_series_covid_19_confirmed.csv其中包含映射所需的纬度和经度变量。我还决定保持变量名不变,而不是让MATLAB将其转换为有效的MATLAB标识符,因为有些列名是日期。
opts=detectImportOptions(文件名(4),“TextType”,“字符串”);选择。VariableNamesLine = 1;选择。DataLines =(2,正);选择。PreserveVariableNames = true;times_conf = readtable(文件名(4),选择);
数据集包含省/州变量,但我们希望在国家/地区的水平。在此之前,我们需要清理一下数据。请注意,我使用了()符号,因为变量名不是有效的MATLAB标识符。
泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“中国”) =“中国大陆”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“Czechia”) =“捷克”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =伊朗(伊斯兰共和国)) =“伊朗”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“大韩民国”) =“朝鲜,南”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“摩尔多瓦共和国”) =“摩”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“俄罗斯联邦”) =“俄罗斯”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“台北和环境”) =“台湾”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“台湾*”) =“台湾”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“联合王国”) =“英国”;泰晤士报(“国家/地区”)(泰晤士报)(“国家/地区”) = =“越南”) =“越南”;泰晤士报(“国家/地区”)(泰晤士报)(“省/州”) = =“圣马丁”) =“圣马丁”;泰晤士报(“国家/地区”)(泰晤士报)(“省/州”) = =“圣巴塞勒米”) =“圣巴塞勒米”;
现在我们可以用组摘要通过。聚合数据国家/地区通过汇总确诊病例和平均纬度和经度。
var = times_conf.Properties.VariableNames;times_conf_country = groupsummary (times_conf,“国家/地区”,{“总和”,“中庸”}, var(3:结束));
输出包含不必要的栏,如纬度和经度的总和或确诊病例的方式。让我们移除这些变量“sum_”或“中庸”我们保留的变量的前缀。
vars=times\u conf\u country.Properties.VariableNames;vars=regexprep(vars,“^(总和)(?=L(a | o))”,“删除”);vars=regexprep(vars,“^(平均值)(?=[0-9])”,“删除”);变量=擦除(变量{“sum_”,“中庸”});times_conf_country.Properties。VariableNames = var;times_conf_country = removevars (times_conf_country, {“GroupCount”},vars(包含),“删除”))]);
因为中国大陆太大了,我们想把它排除在我们的想象之外。
times_conf_exChina = times_conf_country (times_conf_country。(“国家/地区”) ~ =“中国大陆”:);var = times_conf_exChina.Properties.VariableNames;
让我们使用土气泡可视化数据集中的第一个和最后一个日期。由于numerica数据的列名是日期,我可以简单地选择第一个日期和最后一个日期一起显示地图。请注意土气泡将显示一个0值的冒泡,因此,如果我们不想在0情况下显示冒泡,我们需要删除值为0的行。
图t = tiledlayout(“流动”);为ii=[4,长度(vars)]乘以配置(exChina.Category=分类(repmat(" < 100,高度(times_conf_exChina),1);times_conf_exChina.类别(表2排列(times_conf_exChina(:,ii))>=100)=“> = 100”下一个tbl=中国的时间(:,[1:3,ii,end]);tbl(tbl.(4)=0,:)=[];gb=地球泡泡(tbl,“拉丁美洲”,“长”,“大小可变”一样,var (ii),“颜色变量”,“类别”);gb.BubbleColorList=[1,0,1;1,0,0];gb.LegendVisible=“关”; 国标=“的”+ var (ii);gb。SizeLimits = [0, max(times_conf_exChina.(vars{length(vars)}))];gb。MapCenter = [21.6385 36.1666];gb。ZoomLevel = 0.3606;结束标题(t) [“境外新冠肺炎确诊病例”;...“100个以上案例用红色标注的国家/地区”])
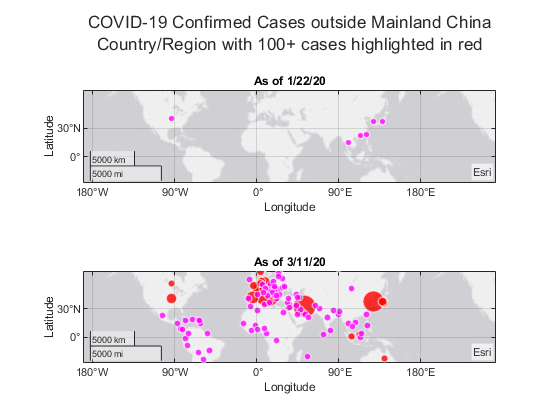
我们可以看到,它最初只影响到中国大陆周边的国家/地区,但由于韩国、意大利和伊朗出现了大规模疫情爆发。还值得注意的是,我们早在2020年1月22日就在美国发现了确诊病例。
绘制美国确诊病例地图
因为我住在波士顿,我对更多的本地案件感兴趣。我们下去省/州在美国的水平。
times_conf_us=times_conf((times_conf(“国家/地区”) = =“美国”),:;泰晤士报(“省/州”) = =“钻石公主”,:)=[];vars=times\u conf\u us.Properties.VariableNames;图t=tiledlayout(“流动”);为ii=[5,长度(vars)]乘以形态分类=分类(repmat(" < 100,高度(times_conf_us),1));times_conf_us.类别(表2阵列(times_conf_us(:,ii))>=100)=“> = 100”下一节tbl=时间形态(:,[1:4,ii,end]);tbl(tbl.(5)=0,:)=[];gb=地质气泡(tbl,“拉丁美洲”,“长”,“大小可变”一样,var (ii),“颜色变量”,“类别”);gb.BubbleColorList=[1,0,1;1,0,0];gb.LegendVisible=“关”; 国标=“的”+ var (ii);gb。SizeLimits = [0, max(times_conf_us.(vars{length(vars)}))];gb。MapCenter = [44.9669 -113.6201];gb。ZoomLevel = 1.7678;结束标题(t) [“美国的新冠病毒-19确诊病例”;...“100个以上案例用红色标注的省/州”])

你可以看到它开始于华盛顿并在那里爆发,加州和纽约也是如此。
按确诊病例对国家/地区进行排名
让我们使用以下方法按国家/地区比较确诊病例的数量:新冠病毒19_data.csv。datetime格式不一致,因此我们将首先将其视为文本。
选择= detectImportOptions(文件名(3),“TextType”,“字符串”,“DatetimeType”,“文本”); provData=可读(文件名(3),选项);
警告:在为表创建变量名之前,文件中的列标头被修改为有效的MATLAB标识符。原始的列标题保存在VariableDescriptions属性中。设置'PreserveVariableNames'为true以使用原始列标题作为表变量名。
让我们清理一下datetime格式。
provData。ObservationDate = regexprep (provData。ObservationDate,"\/20$","/2020");provData.ObservationDate=日期时间(provData.ObservationDate);
我们还需要标准化国家/地区的价值观。
provData.Country\u Region(provData.Country\u Region==伊朗(伊斯兰共和国)) =“伊朗”;provData.Country_Region(provData.Country_Region==“爱尔兰共和国”) =“爱尔兰”;provData.Country_Region(provData.Country_Region==“大韩民国”) =“韩国”;provData.Country_Region(provData.Country_Region==“(圣马丁,)”) =“圣·马丁”;provData.Country_Region(provData.Country_Region==“罗马教廷”) =“梵蒂冈城”;provData.Country_Region(provData.Country_Region==“巴勒斯坦被占领土”) =“巴勒斯坦”;
数据集包含省/州变量。让我们在国家/地区的水平。
countryData = groupsummary (provData, {“观测日期”,“Country_Region”},...“和”,{“确认”,“死亡”,“恢复”});countryData.Properties.VariableNames =擦掉(countryData.Properties.VariableNames,“sum_”);
国家数据包含每日累积数据。我们只需要最新的数据。
countryLatest = groupsummary (countryData,“Country_Region”,“马克斯”,“确认”);countryLatest.Properties.VariableNames=擦除(countryLatest.Properties.VariableNames,“max_”);
让我们对前10名进行排名,并用直方图.
(排序,idx) = (countryLatest排序。确认,“下”);labels=countryLatest.Country_Region(idx);k=10;topK=sorted(1:k);labelsK=labels(1:k);图形直方图(“类别”分类(labelsK),“BinCounts”topK,...“DisplayOrder”,“上升”,“定位”,“水平”)xlabel(“确诊病例”)标题([组成(“按国家/地区分列的COVID-19确诊病例-前%d”,k);...“的”+ datestr (max (provData.ObservationDate))))

除中国大陆外,意大利和伊朗正在超越韩国。
国家/地区确诊病例增长
我们还可以检查这些国家的病例增长速度。
图绘制(countryData.ObservationDate (countryData。Country_Region = = labelsK (2)),...countryData.Confirmed (countryData。Country_Region = = labelsK (2)));持有在…上为ii = 3:length(labelsK) plot(countryData. observationdate (countryData. observationdate))Country_Region = = labelsK (ii)),...countryData.Confirmed (countryData。Country_Region = = labelsK (ii)),“线宽”,1);结束持有关头衔([“境外新冠肺炎确诊病例”;创作(“前%d个国家/地区”传说,k)]) (labelsK(2:结束),“地点”,“西北”)xlabel(“的”+ datestr (max (provData.ObservationDate))) ylabel (“案例”)
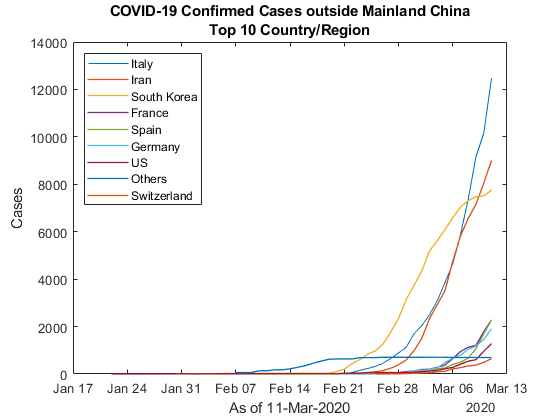
尽管韩国表现出放缓的迹象,但它在其他任何地方都在加速。
按国家/地区分列的新病例增长情况
我们可以通过减去两个日期之间的累计确诊病例数来计算新增病例数。
by_country =细胞(大小(labelsK));图t = tiledlayout(“流”);为ii = 1:length(labelsK) country =Country_Region = = labelsK (ii):);= groupsummary(国家,{“观测日期”,“Country_Region”},...“和”,{“确认”,“死亡”,“恢复”});country.Properties.VariableNames =擦掉(country.Properties.VariableNames,“sum_”);country.New=[0;country.confirfied(2:end)-country.confirfied(1:end-1)];country.New(country.New<0)=0;by_country{ii}=country;如果拉贝尔斯克(二)~=“他人”nexttile plot(country.ObservationDate,country.New) title(labelsK(ii) + compose(”——% d”马克斯(country.Confirmed)))结束结束标题(t、撰写)(“新冠新病例-前%d个国家/地区”、k))包含(t)“的”+datestr(max(provData.ObservationDate)))ylabel(t,“新案件”)

你可以看到,在中国大陆和韩国没有多少新病例。看来他们控制住了疫情。
仔细看看中国大陆
由于中国大陆的感染速度正在放缓,让我们看看还有多少活跃病例。通过从确诊病例中减去康复病例和死亡病例,可以计算活跃病例。
为ii = 1:length(labelsK) by_country{ii}。积极= by_country{2}。确认——by_country{2}。死亡——by_country {2} .Recovered;结束图区域(by_country{1}。ObservationDate,...[由{1}国家提供。由{1}国家提供活动。由{1}国家提供恢复。死亡人数])图例(“活跃”,“恢复”,“死亡”,“地点”,“西北”)头衔(“中国内地确诊病例分类”)xlabel(“的”+ datestr (max (provData.ObservationDate))) ylabel (“案例”)

拟合曲线
活动性病例数量正在下降,曲线看起来大致呈高斯分布。我们是否可以拟合一个高斯模型并预测活跃病例何时为零?
免责声明:这是一个非常粗糙的方法,你不应该从中得出任何结论——这只是为了你的阅读乐趣。
我用了曲线拟合工具箱将高斯函数拟合到忙碌的为了评估拟合优度,看看这个.
[x, y] = prepareCurveData((1:length(by_country{1}.Active))',by_country{1}.Active);英国《金融时报》= fittype (“高斯1”);选择= fitoptions (“方法”,“非线性最小二乘法”);选择。显示=“关”;opts.Lower=[-Inf-Inf 0];opts.StartPoint=[58046 27 7.66733432245782];[fobj,gof]=fit(x,y,ft,opts);gof
Gof = struct with fields: sse: 4.4145e+08 rsquare: 0.9743 dfe: 47 adjrsquare: 0.9732 rmse: 3.0647e+03
让我们通过增加20天来预测未来的输出。
extend_days = 20;xhat = [x;(x(结束)+ 1:x(结束)+ extend_days) ');xdates = [by_country {1} .ObservationDate;...(按国家分列)观测日期(结束)+天数(1):...by_country {1} .ObservationDate(结束)+天(extend_days)) ');yhat = fobj (xhat);ci = predint (fobj xhat);
现在我们已经准备好了。
图区域(按国家{1}.观测日期,按国家{1}.活动)保持在…上绘图(xdates、yhat、,“线宽”,2)绘图(xdates,ci,“颜色”,“m”,“线条样式”,”:“,“线宽”, 2)关ylim([0 inf])图例(“实际”,“高斯适合”,“信心指数”,“地点”,“东北”)头衔(“中国大陆活动性病例的高斯模型”)xlabel(“实际截止日期”+ datestr (max (provData.ObservationDate))) ylabel (“案例”)

显然,我不会从表面上接受这一点,但如果中国大陆能在4月初将活跃病例减少到零,岂不是很好?
韩国呢?
让我们来描绘韩国的活跃病例、恢复病例和死亡人数。
图区域(by_country{4}。ObservationDate,...[by_country{4}。忙碌的by_country{4}.Recovered by_country{4}.Deaths]) legend(“活跃”,“恢复”,“死亡”,“地点”,“西北”)头衔(“韩国确诊病例的分解”)xlabel(“的”+ datestr (max (provData.ObservationDate))) ylabel (“案例”)
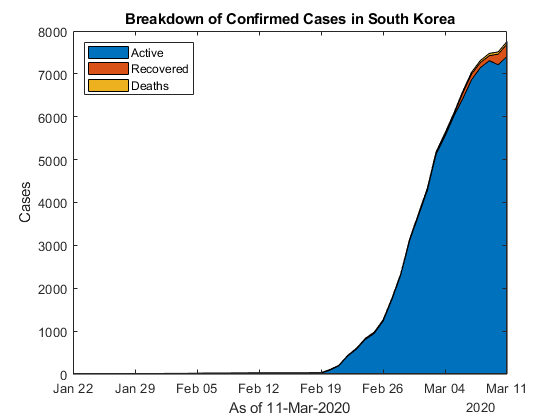
正如你在情节中看到的,现在判断他们是否达到了顶峰还为时过早。我不认为我们可以用高斯函数得到任何好的匹配。
总结
你是否使用MATLAB帮助抗击COVID-19?或者你已经开始自我隔离了?分享你如何使用MATLAB,而你经历了这个尝试的时间在这里.
MathWorks,Inc.版权所有。








评论
要留下评论,请点击在这里登录到您的MathWorks帐户或创建一个新帐户。