chowtest
结构变化的周试验
语法
描述
Chow检验评估系数的稳定性β在多元线性回归模型的形式y=Xβ+ε.chowtest在指定的断点拆分数据。在初始子样本中估计系数,然后测试与互补子样本中的数据的兼容性。
StatTbl= chowtest (资源描述,英国石油公司)StatTbl包含测试结果、统计数据的变量,以及对表或时间表的变量进行Chow测试的设置资源描述.每行StatTbl包含相应测试的结果。
回归中的响应变量是最后一个表变量,所有其他变量都是预测变量。要为回归选择不同的响应变量,请使用ResponseVariable名称-值参数。要选择不同的预测变量,请使用PredictorNames名称-值参数。
例子
进行结构变化的Chow测试
进行周测试,以评估第二次世界大战前后粮食需求方程式中是否存在结构性变化。以矩阵形式输入预测级数,以向量形式输入响应级数。
加载美国食品消费数据集Data_Consumption.mat其中包含了1927年至1962年的年度测量数据,由于战争,矩阵中缺少数据数据.
负载Data_Consumption
假设你想建立一个由食品价格和可支配收入决定的消费模型,并通过战争带来的经济冲击来评估其稳定性。
画出级数。
P =数据(:,1);食品价格指数I = Data(:,2);可支配收入指数Q =数据(:,3);食品消费指数图;plot(日期,[P I Q])轴紧网格在包含(“年”) ylabel (“指数”)传说([“价格”“收入”“消费”),位置=“东南”)
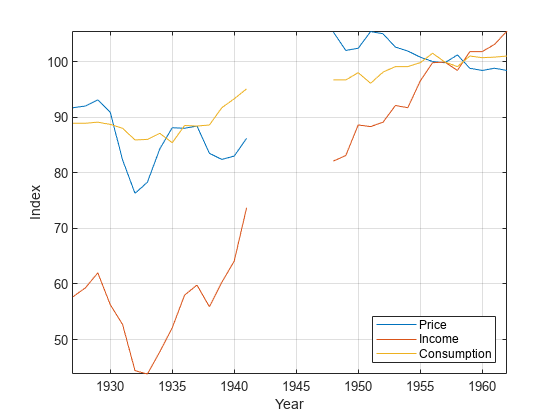
从1942年到1947年,也就是第二次世界大战期间,没有测量数据。
通过应用对数变换来稳定每个系列。
LP = log(P);LI = log(I);LQ = log(Q);
假设对数消费是食品价格和收入对数的线性函数。
是一个均值为0,标准差为0的高斯随机变量 .
找出二战前的指数。将消费与食品价格和收入进行对比。
preWarIdx =(日期<= 1941);李图scatter3 (LP (preWarIdx), (preWarIdx)、江西(preWarIdx), [],“罗”);持有在scatter3 (LP (~ preWarIdx),李(~ preWarIdx)、江西(~ preWarIdx), [],“b *”);传奇([“战前的观察”“战后的观察”),...位置=“最佳”)包含(“日志价格”) ylabel (“日志收入”) zlabel (“日志消费”)%获得更好的视野H = gca;h. camerposition = [4.3 -12.2 5.3];
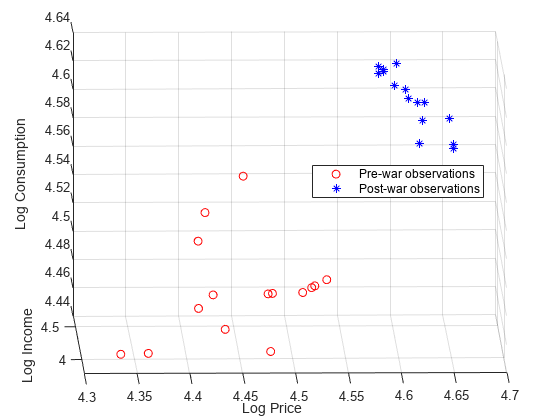
数据关系似乎受到了战争的影响。
在5%显著性水平下进行两次断点Chow检验。对于第一个测试,将断点设置为1941。将另一个测试的断点设为1948年。
bp = find(preWarIdx,1,“最后一次”);X = [lp li];y = LQ;h1941 = chowtest(X,y,bp)
h1941 =逻辑1
h1948 = chowtest(X,y,bp + 1)
h1948 =逻辑0
H1941 = 1表明有足够的证据来拒绝原假设,即当断点发生在战前时,系数是稳定的。然而,H1948 = 0表明没有足够的证据拒绝系数稳定,如果断点是战后。这一结果表明1948年的数据是有影响力的。
或者,您可以提供断点向量来执行三个Chow测试。
h = chowtest(X,y,[bp bp+1]);
结果摘要***************试验1样本量:30断点:15试验类型:断点系数测试:所有统计量:5.5400临界值:3.0088 P值:0.0049显著性水平:0.0500决定:拒绝系数稳定性***************试验2样本量:30断点:16试验类型:断点系数测试:所有统计量:1.2942临界值:3.0088 P值:0.2992显著性水平:0.0500决定:拒绝系数稳定性失败
默认情况下,chowtest当您执行多个测试时,显示每个测试的测试结果摘要。
回归测试p-值和决策统计
加载美国食品消费数据集Data_Consumption.mat.考虑一个由对数食品价格和对数可支配收入决定的对数食品消费模型。
负载Data_ConsumptionX = log(Data(:,1:2));y = log(Data(:,3));
在5%显著性水平下进行两次断点Chow检验。对于第一个测试,将断点设置为1941。将另一个测试的断点设为1948年。返回测试决策, -值、测试统计量和测试临界值。
Bp = find(日期<= 1941,1,“最后一次”);[h,pValue,stat,cValue] = chowtest(X,y,bp)
h =逻辑1
pValue = 0.0049
Stat = 5.5400
cValue = 3.0088
pValue< 0.01,这表明拒绝零假设的证据,即回归模型中由1941年断点确定的所有系数都是相等的。
对表变量进行结构变化的Chow检验
进行周测试,以评估第二次世界大战期间的粮食需求方程是否存在结构性变化,其中时间序列是表格中的变量。
加载美国食品消费数据集Data_Consumption.mat,其中包含1927年至1962年的年度测量数据,由于战争,表格中缺少数据数据表.将表转换为时间表,并删除包含缺失值的行。
负载Data_ConsumptionDates = datetime(Dates,12,31);TT = table2时间表(数据表,RowTimes=日期);TT。Row = [];TT = rmmissing(TT);
对表中的所有变量应用日志转换。
LogTT = varfun(@log,TT);LogTT.Properties.VariableNames
ans =1 x3单元格{'log_P'} {'log_I'} {'log_Q'}
在5%显著性水平下进行两次断点Chow检验。对于第一个测试,将断点设置为1941年底。将另一个测试的断点设为1948年底。
bp1941 = find(LogTT. bp1941)时间>= datetime(1941,12,31),1);bp1948 = find(LogTT. bp1948 = find(LogTT. bp1948)时间>= datetime(1948,12,31),1);Bp = [bp1941 bp1948];StatTbl = chowtest(LogTT,bp)
结果摘要***************试验1样本量:30断点:15试验类型:断点系数测试:所有统计量:5.5400临界值:3.0088 P值:0.0049显著性水平:0.0500决定:拒绝系数稳定性***************试验2样本量:30断点:16试验类型:断点系数测试:所有统计量:1.2942临界值:3.0088 P值:0.2992显著性水平:0.0500决定:拒绝系数稳定性失败
StatTbl =2×8表h pValue stat cValue断点α拦截试验 _____ _________ ______ ______ ___________ _____ _________ ______________ 测试1真的15 0.05 0.0049125 5.54 3.0088真的{“断点”}测试2假0.05 0.29918 1.2942 3.0088 16真{“断点”}
StatTbl包含每个测试(行)的决策统计信息和选项。
默认情况下,chowtest选择最后一个表变量作为响应,并选择所有其他变量作为预测器。属性可以选择不同的变量ResponseVariable名称-值参数。方法可以选择一组不同的预测变量PredictorVariables名称-值参数。
美国真实国民生产总值结构变化的检验模型
应用周检验来评估美国实际国民生产总值(RGNP)的解释模型的稳定性,使用第二次世界大战结束作为断点。
加载Nelson-Plosser数据集Data_NelsonPlosser.mat,其中包含数据表数据表.
负载Data_NelsonPlosser
数据集中的时间序列包含从1860年到1970年的年度宏观经济测量数据。有关详细信息、变量列表和描述,请输入描述在命令行中。
将表格转换为时间表。将样本聚焦到1915年底到1970年底的测量。
Dates = datetime(Dates,12,31);Span = isbetween(日期,datetime(1915,12,31),datetime(1970,12,31),“关闭”);TT = table2时间表(数据表,RowTimes=日期);TT。日期= [];TT = TT(span,:);
考虑一个美国RGNP的预测模型GNPR给定工业生产指数的测量值新闻学会,总就业人数E,以及实际工资或者说是.
在模型中绘制级数。
预名= [“他们”“E”“福”];tiledlayout (2, 2)为J = [“GNPR”nexttile plot(TT. time,TT{:,j})结束
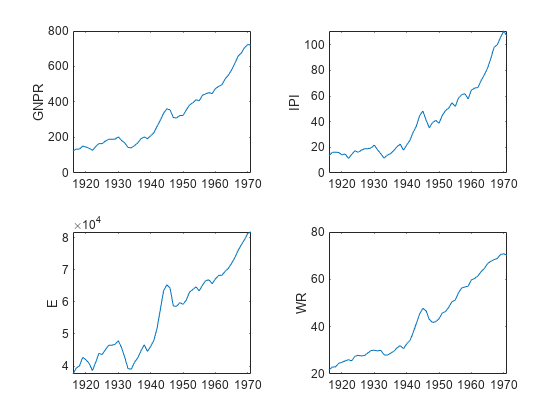
要处理指数增长,请对级数应用对数变换。
LogTT = varfun(@log,TT);
LogTT是否有包含转换变量的时间表TT,但在名字前加上log_.
选择对应于1945年9月2日第二次世界大战结束的指数。
bp = find(LogTT。时间> datetime(1945,9,2),1);
假设一个合适的多元回归模型来描述真实的GNP是
进行断点检验以评估所有回归系数是否稳定。以二战结束为切入点。将测试摘要打印到命令行。
lprednames =“log_”+ prednames;StatTbl = chowtest(LogTT,bp,ResponseVariable=“log_GNPR”,...PredictorVariables = lprednames显示=“摘要”)
结果摘要***************试验1样本量:56断点:31试验类型:断点被测系数:全部统计量:4.0978临界值:2.5652 P值:0.0062显著性水平:0.0500决定:拒绝稳定系数
StatTbl =表1×8h pValue stat cValue断点α拦截试验 _____ _________ ______ ______ ___________ _____ _________ ______________ 测试1真的0.05 0.0061633 4.0978 2.5652 31真的{“断点”}
StatTbl包含测试的决策统计信息和测试选项。StatTbl.h = 1而且StatTbl。pValue< 0.01表示字符串证据以拒绝原假设,即二战前后的回归系数是相等的。
评估回归系数子集的稳定性
进行Chow检验以评估回归系数子集的稳定性。本例扩展到进行结构变化的Chow测试.
加载美国食品消费数据集。将表转换为时间表,并删除包含缺失值的行。
负载Data_Consumption.matDates = datetime(Dates,12,31);TT = table2时间表(数据表,RowTimes=日期);TT。Row = [];TT = rmmissing(TT);
对每个系列应用对数变换。
LogTT = varfun(@log,DataTable);
找出二战前的指数。
preWarIdx = dates <= datetime(1941,12,31);
考虑两个回归模型:一个是原木消费对原木食品价格的影响,另一个是原木消费对原木收入的影响。为两个模型绘制散点图和回归线。
图绘制(LogTT.log_P (preWarIdx) LogTT.log_Q (preWarIdx),“波”,...LogTT.log_P (~ preWarIdx) LogTT.log_Q (~ preWarIdx),“r *”);轴紧网格在lsline包含(“日志价格”) ylabel (“日志消费”)传说(“战前的观察”,“战后的观察”)
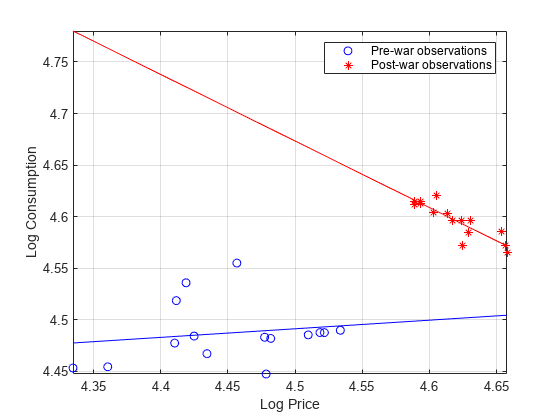
图绘制(LogTT.log_I (preWarIdx) LogTT.log_Q (preWarIdx),“波”,...LogTT.log_I (~ preWarIdx) LogTT.log_Q (~ preWarIdx),“r *”);轴紧网格在lsline包含(“日志收入”) ylabel (“日志消费”)传说(“战前的观察”,“战后的观察”,...位置=“西北”)
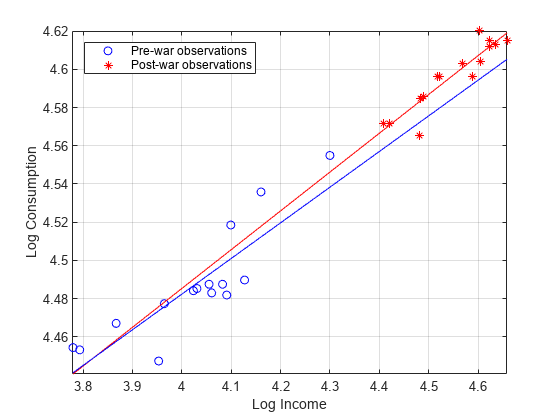
在战前和战后的子样本之间,食品价格弹性存在明显的断裂。然而,收入弹性似乎没有这样的突破。
进行两次Chow检验,以确定是否有统计证据拒绝两个回归模型的模型连续性。因为互补子样本中的观察值比系数多,所以进行断点检验。只考虑测试中的弹性。也就是说,指定假对于截距(第一个系数)和真正的对于弹性(第二个系数)。
bp = find(preWarIdx,1,“最后一次”);1941年%指数chowtest (LogTT,英国石油(bp)多项式系数=(虚假的真实),显示=“摘要”,...ResponseVariable =“log_Q”PredictorVariables =“log_P”);
结果摘要***************试验1样本量:30断点:15试验类型:断点被测系数:01统计量:7.3947临界值:4.2252 P值:0.0115显著性水平:0.0500决定:拒绝稳定系数
chowtest (LogTT,英国石油(bp)多项式系数=(虚假的真实),显示=“摘要”,...ResponseVariable =“log_Q”PredictorVariables =“log_I”);
结果摘要***************试验1样本量:30断点:15试验类型:断点被测系数:0 1统计量:0.1289临界值:4.2252 P值:0.7225显著性水平:0.0500判定:拒绝系数稳定性失败
第一个检验否定了原假设,即价格弹性在5%的显著性水平上在子样本之间是等效的。第二个检验未能拒绝原假设,即收入弹性在子样本之间是等效的。
考虑一个消费日志与价格和收入日志的回归模型。进行两个断点测试:一个只比较子样本的价格弹性,另一个只比较收入弹性。
Coeffs = [false true false;假假真];chowtest (LogTT,英国石油(bp)多项式系数=多项式系数,显示=“摘要”,...ResponseVariable =“log_Q”PredictorVariables = (“log_P”“log_I”]);
结果摘要***************试验1样本量:30断点:15试验类型:断点测试系数:01 0统计量:0.0001临界值:4.2597 P值:0.9920显著性水平:0.0500决定:拒绝系数稳定性失败***************试验2样本量:30断点:15试验类型:断点测试系数:001统计量:2.8151临界值:4.2597 P值:0.1064显著性水平:0.0500决定:拒绝系数稳定性失败
对于这两个测试,没有足够的证据拒绝5%水平的模型稳定性。
模型结构变化
模拟一个线性模型的数据,包括截距中的一个结构断裂和一个预测系数。然后,选择特定的系数来测试在断点上使用Chow测试的相等性。调整参数以评估Chow试验的敏感性。
为模拟线性模型指定四个预测因子、50个观测值和周期44处的断点。
numPreds = 4;numObs = 50;Bp = 44;rng (1);%用于再现性
通过指定预测器的均值来形成预测器数据,然后向每个均值添加随机的标准高斯噪声。
Mu = [0 1 2 3];X = repmat(mu,numObs,1) + randn(numObs,numPreds);
在预测器数据中包含一列。
X = [ones(numObs,1) X];
指定回归系数的真值,第二个预测器的截距和系数跳跃10%。
Beta1 = [1 2 3 4 5]';初始子样本系数Beta2 = beta1 + [beta1(1)*0.1 0 beta1(3)*0.1 0 0]';互补子样本系数X1 = X(1:bp,:);%初始子样本预测因子X2 = X(bp+1:end,:);互补子样本预测因子
指定一个2乘5的逻辑矩阵,表示首先测试截距和第二个回归系数,然后测试所有其他系数。
Test1 = [true false true false false];Coeffs = [test1;~ test1)
多项式系数=2x5逻辑阵列1 0 1 0 0 0 1 0 1 1
第一个检验的零假设(:多项式系数(1))是子样本之间的截距和第二个预测器的系数的相等性。第二个检验的零假设(:多项式系数(2))是子样本中第一、第三和第四个预测因子的相等性。
为线性模型模拟数据
创建创新为均值为零,标准差为0.2的随机高斯变量向量。
σ = 0.2;innov = sigma*randn(numObs,1);y = [X1 0 (bp,size(X2,2));...0 (numObs-bp大小(X1, 2)) X2] * [beta1;beta2] +创新;
中所示的两个断点测试多项式系数.因为在预测矩阵中有一个截距X已经,指定抑制其包含在线性模型中chowtest适合。
chowtest (X, y, bp,拦截= false,多项式系数=多项式系数,...显示=“摘要”);
结果摘要***************试验1样本量:50断点:44试验类型:断点测试系数:10 10 0统计量:5.7102临界值:3.2317 P值:0.0066显著性水平:0.0500决定:拒绝系数稳定性***************试验2样本量:50断点:44试验类型:断点测试系数:0 10 1统计量:0.2497临界值:2.8387 P值:0.8611显著性水平:0.0500决定:拒绝系数稳定性失败
默认重要级别:
Chow检验正确地拒绝了零假设,即在某一时期不存在结构断裂
英国石油公司求截距和第二个系数。Chow检验正确地拒绝了其他系数的零假设。
将断点测试结果与预测测试结果进行比较。
chowtest (X, y, bp,拦截= false,多项式系数=多项式系数,...测试=“预测”显示=“摘要”);
结果摘要***************试验1样本量:50断点:44试验类型:预测检验系数:1 01 00统计量:3.7637临界值:2.8451 P值:0.0182显著性水平:0.0500决定:拒绝系数稳定性***************试验2样本量:50断点:44试验类型:预测检验系数:01 01统计量:0.2135临界值:2.6123 P值:0.9293显著性水平:0.0500决定:拒绝系数稳定性失败
在这种情况下,来自测试的推论与断点测试的推论是等价的。
输入参数
输出参数
更多关于
提示
周检验假设创新在结构变化中存在连续性。异方差会扭曲测试的大小和能力。因此,在使用测试结果进行推理之前,需要验证创新-方差-连续性假设成立。
如果两个子样本都包含大于
numCoeffs观察,您可以执行预测测试,而不是断点测试(请参阅测试).然而,预测检验相对于断点检验可能具有较低的功率[1].然而,Wilson(1978)建议在存在未知规格错误的情况下进行预测检验[4].您可以将预测检验应用于两个子样本的大小都大于的情况
numCoeffs,您通常会在其中应用断点测试。在这种情况下,预测测试相对于断点测试可能会显著降低功耗[1].然而,Wilson(1978)建议在存在未知规格错误时使用预测检验[4].预测检验基于稳定系数产生的无偏预测,平均误差为零。然而,零平均预测误差一般不能保证系数的稳定性。因此,预测测试在检查结构断裂时最有效,而不是模型连续性[3].
为了获得每个子样本的诊断统计信息,例如回归系数估计、它们的标准误差、误差平方和等,将适当的数据传递给
fitlm.有关使用的详细信息LinearModel建模对象,请参见多元线性回归.
参考文献
[1]周国强。两线性回归中系数集间相等性的检验费雪.Vol. 28, 1960, pp. 591-605。
[2]费希尔,f。两线性回归中系数集间相等性的检验:说明文。费雪.卷38,1970,第361-66页。
雷亚,j.d.。当观测数量不足时,Chow检验的不确定性。费雪.第46卷,1978,第229页。
[4]威尔逊a.l.“周考试UMP是什么时候?”美国统计学家.卷32,1978,第66-68页。
版本历史
在R2015b中引入您也可以从以下列表中选择一个网站: