估计条件均值和方差模型
这个例子展示了如何使用复合条件均值和方差估计模型估计。
加载和数据预处理
NASDAQ指数数据加载包含计量经济学工具箱™。把日常综合指数系列回归系列。数值稳定,收益转换成比例的回报。
负载Data_EquityIdx纳斯达克= DataTable.NASDAQ;r = 100 * price2ret(纳斯达克);T =长度(r);
创建模型模板
创建一个AR(1)和GARCH(1,1)组合模型,形式
在哪里 和 是一个iid标准化的高斯过程。
VarMdl = garch (1,1)
VarMdl = garch的属性:描述:“garch(1,1)条件方差模型(高斯分布)”Distribution: Name = "Gaussian" P: 1 Q: 1 Constant: NaN GARCH: {NaN} at lag [1] ARCH: {NaN} at lag [1] Offset: 0
Mdl = arima (“ARLags”,1“方差”VarMdl)
Mdl = arima与属性:描述:“arima(1,0,0)模型(高斯分布)”Distribution: Name = "Gaussian" P: 1 D: 0 Q: 0 Constant: NaN AR: {NaN} at lag [1] SAR: {} MA: {} SMA: {} Seasonality: 0 Beta: [1×0] Variance: [GARCH(1,1) Model]
Mdl是一个华宇电脑模型估计的模板。南价值的属性Mdl和VarMdl对应于未知,可估计的系数和方差参数的复合模型。
估计模型参数
符合模型返回系列r通过使用估计。
EstMdl =估计(Mdl, r);
ARIMA(1,0,0)模型(高斯分布):价值StandardError TStatistic PValue ________ _________________ __________ __________常数0.072632 0.018047 4.0245 5.7087 e-05 AR {1} 0.13816 0.019893 6.945 3.7848 e-12 GARCH(1,1)条件方差模型(高斯分布):价值StandardError TStatistic PValue ________ _________________ __________ __________常数0.022377 0.0033201 6.7399 1.5851 e-11 GARCH{1} 0.87312 0.0091019 95.927 0弓{1}e-42 0.11865 0.008717 13.611 3.434
EstMdl是一个完全指定的华宇电脑模型。
估计显示显示了五个估计参数和相应的标准误差(AR(1)条件均值模型有两个参数,和GARCH(1,1)条件方差模型有三个参数)。
拟合模型(EstMdl)是
所有 统计数据是大于2,这表明所有参数都具有统计学意义。
动态模型需要presample观察,来初始化模型。如果你不指定presample观察,估计默认生成它们。
推断条件方差和残差
推断和情节条件方差和标准化残差。输出loglikelihood目标函数值。
[res, v, logL] =推断(EstMdl, r);图次要情节(2,1,1)情节(v) xlim ([0, T])标题(“有条件的差异”次要情节(2,1,2)情节> /√(v) xlim ([0, T])标题(标准化残差的)
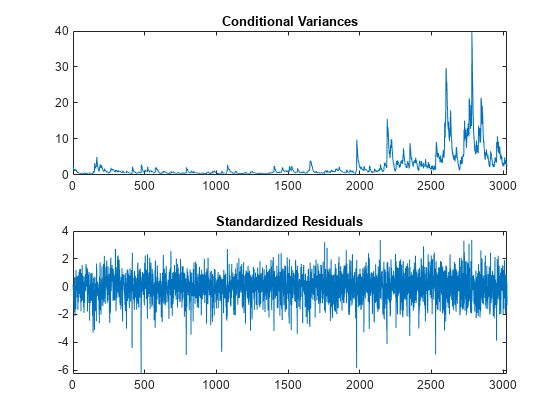
2000年后观察条件方差增长。这个结果对应于波动增加的原始回归系列。
标准化残差有更大值(绝对值大于2或3)比预期的标准正态分布。这个结果表明学生的 分布更适合创新。
合适的模型t创新分布
创建一个模型模板Mdl,并指定其创新有一个学生的
分布。
MdlT = Mdl;MdlT。分布=“t”;
MdlT有一个额外的参数估计:
分布的自由度。
适应新的纳斯达克返回系列模型。指定一个初始值方差模型常数项。
Variance0 = {“Constant0”0.001};EstMdlT =估计(MdlT r“Variance0”,Variance0);
ARIMA(1,0,0)模型(t分布):价值StandardError TStatistic PValue ________ _________________ __________ __________常数0.093488 0.016694 5.6002 2.1414 e-08 AR {1} e-13景深7.4775 0.88261 8.472 1.6175 0.13911 0.018857 7.3771 2.4126 e-17 GARCH(1,1)条件方差模型(t分布):价值StandardError TStatistic PValue ________ _________________ __________ __________常数0.011246 0.0036305 3.0976 0.0019511 GARCH{1} 0.90766 0.010516 86.315 0弓{1}e-16景深7.4775 0.88261 8.472 1.0712 0.089897 0.010835 8.2966 2.4126 e-17
之间的系数估计EstMdl和EstMdlT略有不同。自由度估计相对较小(约8),这表明显著偏离正常。
比较模型适合
总结了估计模型。从总结,获得的数量估计参数和loglikelihood从第二目标函数值。
摘要=总结(EstMdl);SummaryT =总结(EstMdlT);numparams = Summary.NumEstimatedParameters;numparamsT = SummaryT.NumEstimatedParameters;logLT = SummaryT.LogLikelihood;
比较两个模型(高斯和相吻合 创新分布)使用Akaike信息准则(AIC)和贝叶斯信息准则(BIC)。
[numparams numparamsT]
ans =1×25个6
(aic, bic) = aicbic ([logL logLT], [numparams numparamsT), T)
aic =1×2103×9.4929 - 9.3807
bic =1×2103×9.5230 - 9.4168
第一个模型有六个安装参数,而第二个模型有6个(因为它包含 分布的自由度)。尽管这种差异,信息标准模型与学生的青睐 创新AIC和BIC值分布,因为它收益率小于与高斯模型的创新。