推断出
推断ARIMA ARIMAX模型残差或有条件的差异
描述
例子
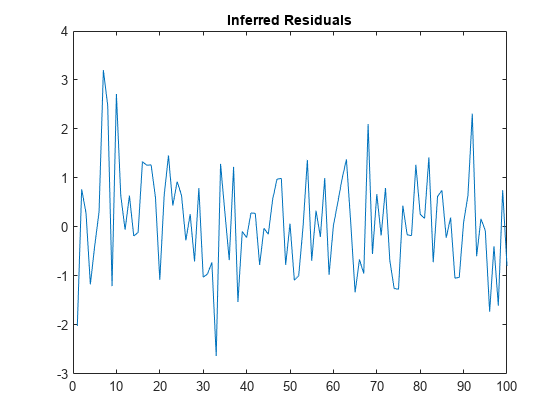
推断出残差
推断出残差的AR模型。
指定一个使用已知的AR(2)模型参数。
Mdl = arima (基于“增大化现实”技术的{0.5,-0.8},“不变”,0.002,…“方差”,0.8);
模拟响应数据与102年的观察。
rng“默认”;Y =模拟(Mdl, 102);
使用前两个反应presample数据,推断100年剩余残差观测。
E =推断(Mdl, Y(3:结束),“Y0”Y (1:2));图;情节(E);标题隐式残差的;
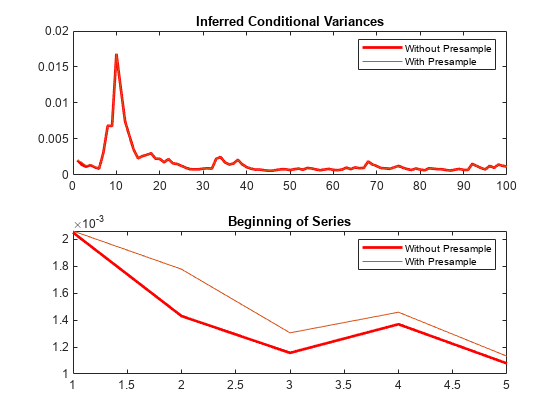
推断出条件方差
推断出的条件方差AR(1)和GARCH(1,1)组合模型。
指定一个使用已知的AR(1)模型参数。设置方差等于一garch模型。
Mdl = arima (基于“增大化现实”技术的{0.8,-0.3},“不变”,0);MdlVar = garch (“不变”,0.0002,“四国”,0.6,…“拱”,0.2);Mdl。Variance = MdlVar;
模拟响应数据与102年的观察。
rng“默认”;Y =模拟(Mdl, 102);
推断条件方差在过去100年观测不使用presample数据。
(电子战,大众)=推断(Mdl Y(3:结束);
推断条件方差在过去100年的观察使用前两个观测presample数据。
(E, V) =推断(Mdl Y(3:结束),“Y0”Y (1:2));
情节条件方差的两组比较。检查前几个观察看到开始的系列之间的细微差别。
图;次要情节(2,1,1);情节(大众,“r”,“线宽”2);持有在;情节(V);传奇(“没有Presample”,“与Presample”);标题推断条件方差的;持有从次要情节(2,1,2);情节(大众(1:5),“r”,“线宽”2);持有在;情节(V (1:5));传奇(“没有Presample”,“与Presample”);标题系列的开始;持有从
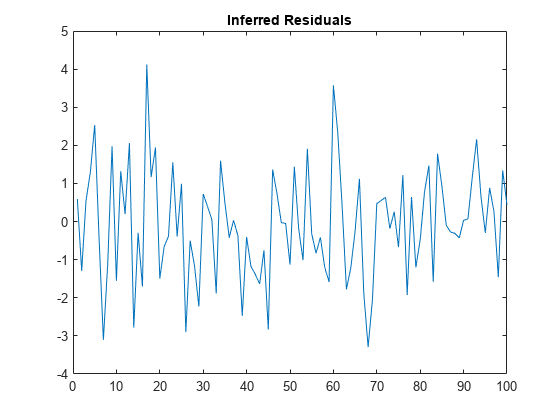
推断出从ARMAX模型残差
从一个ARMAX模型推断出残差。
指定一个ARMA(1,2)模型使用已知参数的响应(医学博士)和一个AR(1)模型预测数据(MdlX)。
md = arima (基于“增大化现实”技术的,0.2,“马”{-0.1,0.6},“不变”,…1,“方差”2,“β”3);MdlX = arima (基于“增大化现实”技术的,0.3,“不变”0,“方差”1);
模拟反应和预测数据与102年的观察。
rng“默认”;%的再现性X =模拟(MdlX, 102);102年Y =模拟(医学博士,“X”,X);
使用前两个反应presample数据,推断100年剩余残差观测。
E =推断(医学博士,Y(3:结束),“Y0”Y (1:2),“X”,X);图;情节(E);标题隐式残差的;
输入参数
输出参数
引用
[1],g . e . P。,G. M. Jenkins, and G. C. Reinsel.时间序列分析:预测与控制第三。恩格尔伍德悬崖,新泽西:普伦蒂斯霍尔,1994年。
恩德斯[2],W。应用计量经济学时间序列。新泽西州霍博肯:约翰威利& Sons, 1995。
[3]汉密尔顿,j . D。时间序列分析。普林斯顿,纽约:普林斯顿大学出版社,1994年。
版本历史
介绍了R2012a